

Scott Aaronson gave a thought-provoking lecture in our Theory seminar three weeks ago. (Actually, this was eleven months ago.) The slides are here . The lecture discussed two results regarding the computational power of quantum computers. One result from this paper gives an oracle-evidence that there are problems in BQP outside the polynomial hierarchy. The method is based on “magnification” of results on bounded depth circuits. (It is related to the Linial-Nisan conjecture.)
The second result that we are going to discuss in this post (along with some of my provoked thoughts) is a recent result of Scott Aaronson and Alex Arkhipov which asserts that if the power of quantum computers can be simulated by digital computers then the polynomial hierarchy collapses. More precisely, their result asserts that if sampling probability distribution created by quantum computers (this is abbreviated as QSAMPLE) is in P then the polynomial hieararchy collapses to its third level.
The beautiful and important paper of Aaronson and Arkhipov is now out. Its main point of view is related to what I describe in the sixth section about “photon machines”. Update: Let me mention related idependent results by Michael J. Bremner, Richard Jozsa, Dan J. Shepherd in the paper entitled: “Classical simulation of commuting quantum computations implies collapse of the polynomial hierarchy“.
Here is the plan for this post
1) The polynomial hierarchy and results about hierarchy collapse
2) The Aaronson Arkhipov (AA) theorem and its proof
3) Two problems posed by AA
Those are: does P=BQP already leads to a collapse of the polynomial hierarchy? And does APPROXIMATE-QSAMPLE already leads to a collapse?
4) Does fault tolerance allow QSAMPLE (on the nose)? (Answer: yes)
5) Is there a quantum analog to Aaronson and Arkhipov’s result and what is the computational power of quantum computers?
6) Three Two competing scenarios
7) Aaronson and Arkhipov photon machines and the complexity class BOSONSAMPLING.
1) The polynomial hierarchy and results about hierarchy’s collapse.
If P=NP then the polynomial hierarchy collapses to the 0th level (P). If NP=coNP then the polynomial hierarchy collapses to the first level. Karp and Lipton proved that if there is a polynomial-size circuit for NP complete problems then the hierarchy collapses to the second level. There are various other results whose conclusion is a collapse of the hierarchy. Feige and Lund proved that if we can extract one bit in computing a certain permanent then this already leade to hierarchy collapse.
How should we interpret a result of the form “If X is in P then the polynomial hierarchy collapses”? Certainly it is strong evidence that X is not in P, or, in other words, that X is computationally difficult. Perhaps it means something even stronger like: “In some rough scale of computational hardness, X is almost NP-hard. (In such a scale, being NP hard and being coNP hard are comparably hard.) For example, an interpretation of the Feige-Lund theorem would be: Even if you cannot solve an NP complete problem using a subroutine that extracts one bit of the permanent, extracting one bit is nonetheless almost as difficult as giving the full answer. Under the second interpretation you would not expect hierarchy collapse results from assumptions like “factoring is in P” or “graph isomorphism is in P” or even from a statement like “(NP intersection coNP)=P”.
2) The AA’s result and how its proof roughly goes
A quantum computer with n qubits creates after a polynomial time computation certain states on these qubits. Once we measure these qubits, each such state translates into a probability distribution on 0-1 strings of length n. QSAMPLE is the name for sampling (precisely) from this probability distribution. (We measure each qubit separately in a fixed way.)
AA’s theorem: If QSAMPLE is in P then the polynomial hierarchy collapses to 
The proof goes roughly as follows. The point is that a permanent of an arbitrary matrix can be described as the probability p that the outcome of a measurement of a computable quantum state is 0. (This probability is exponentially small so even quantum computers will not be able to compute it.) If M is the classical sampling algorithm that simulates the quantum circuit., then M takes as input a random string r, and outputs a sample M(r) from the quantum computer’s output distribution. By the definition of p, p is the probability that M(r) = (0,0,0,…,0), and to estimate p, it suffices to estimate the fraction of r’s such that M(r) = (0,0,0,…,0). We know that any such approximate counting problem is in
Remark: The first (to my knowledge) result indicating a collapse of PH if quantum computers can be simulated classically was achieved in B. Terhal and D. DiVincenzo, Adaptive quantum computation, constant depth quantum circuits and Arthur-Merlin games, Quant. Inf. Comp. 4, 134-145 (2004). arXiv:quantph/0205133.
3) Two problems AA posed
Problem 1: Is it possible to replace QSAMPLE by BQP ?
Specifically, is the following conjecture true? Conjecture: If BQP is in P then the polynomial hierarchy collapses.
Problem 2: Is it the case that if APPROXIMATE-QSAMPLE is in Q then this already leads to hierarchy collapase.
By APPROXIMATE-QSAMPLE we refer to the ability to sample the distribution up to a small constant error in terms of total variation distance. (The AA’s result requires much stronger approximation.) AA were able to show that their result extends to APPROXIMATE-SAMPLE if a certain natural problem regarding approximation of random permanents is #P hard.
A natural question that arises (yet again) from this work is: What is really the power of (noiseless) quantum computers?
In particular,
Problem 3 : Do BQP and QSAMPLE represent (more or less) the same computational power?
4) Does Fault Tolerance allows QSAMPLE (on the nose)?
With a couple of savvy fault tolerance quantum people in the audience (Michael Ben-Or and Dorit Aharonov) and a novice one (me) the question of what happens for noisy quantum computers naturally arose. This also motivates AA problem 2 which assumes that quantum computers can sample quantum distributions up to some small error in the total variation distance between distributions.
Suppose that you have a noisy quantum memory of n qubits at a certain state 

Question 4: Do noisy quantum computers allow QSAMPLE (on the nose)? (Answer: yes)
Here we assume that noiseless classical computing is possible. Let me present an approach towards a positive answer. At first I thought that this will require a new type of quantum error correcting codes that I was not sure if they can be constructed but after a few conversations with FT experts I realized that the answer is ‘Yes’ by rather routine FT methods.
5) Is there a quantum analog to Aaronson and Arkhipov’s result?
AA’s result deals with the quantum complexity class QSAMPLE, but besides that it refers to the classical polynomial hierarchy.
Maybe one can say something under the weaker assumption that QSAMPLE belongs to BQP?
Question 5: If QSAMPLE is in BQP, does this imply unreasonable computational complexity consequences?
What I mean is this: Suppose you are given a classical computer with BQP subroutine. So every decision problem in BQP the subroutine can solve in polynomial time. How strong is this computer? Lets call it a BQP machine. Can this computer create (or well approximate) probability distributions in QSAMPLE? If the answer is yes then already P=BQP collapses the hierarchy by AA’s result. But it is possible that if a BQP machine can approximate QSAMPLE then this already will have unreasonable computational complexity consequences.
The direct quantum Analogs of AA’s result will ask: If BQP machines can QSAMPLE maybe #P-hard problems occurs in a low level of the quantum polynomial hierarchy? Does it imply that that #P-hard problems are in 

But again what I ask about is this. Perhaps QSAMPLE represents much stronger computational power compared to BQP, so that AA’s theorem (perhaps even their proof) can be extended to show that simulating QSAMPLE by BQP-machines already has surprising computational-complexity consequences.
6) Three Two competing scenarios
So let me draw two three competing scenarios:
a) QSAMPLE and BQP both represent the computational complexity of a quantum computer (and both can be simulated for a noisy quantum computer). The is perhaps the common sense scenario.
b) QSAMPLE is considerably more powerful than BQP while still can be achieved by quantum fault tolerance. (This would be my fantasy.)
c) QSAMPLE is considerably more powerful than BQP and reflects a genuine difference between what quantum computers can do and what noisy quantum computers can do.
These possibilities are especially interesting because I expect that it will be possible to decide between them. So this seems an interesting and feasible research question.
7) AA’s photon machines and BOSONSAMPLING.
AA move one step further (This description was based on the hearing the lecture, now that the paper is out, perhaps I should say several further steps) and present a very simple type of quantum computers which already enable creating probability distributions which (under reasonable computational complexity assumptions) cannot be created classically. This is very nice, and trying to test the hypothesis of superior computational power on small quantum devices is an inportant direction. Indeed, the paper proposes that there might be a simple linear optics experiment that “overthrows” the “polynomial Church-Turing thesis”.
The analog for QSAMPLE for these simple quantum computers is called BOSONSAMPLING. It is not known if BOSONSAMPLING represents the full power of quantum computers (quite likely it is weaker) but it already suffices to imply the results mentioned above.
There is one practical as well as conceptual concern though. It seems that even if you try to experiment on a small fragment of quantum computers like the photon machines that AA consider, quantum fault tolerance is likely to require the full monty, namely, universal quantum computer capabilities. (But this itself is an interesting question.)
Question 6: Does fault tolerance on AA’s photon machines requires universal quantum computing?
We can ask a question of a more general nature. There are various canditates for intermidiate computational classes between BPP and BQP. (Like when you allow log depth quantum circuits). Maybe fault tolerance leaves you just with BPP and BQP and nothing in between?
Question 7: Is it the case(under the standard assumptions regarding noise) that there is no intermediate computational class between BPP and BQP described by noisy quantum devices.
I see now some problems with Question 7 (and perhaps also Question 6) when you understand “full monty” as a computational complexity notion. (For example, applying current fault tolerance methods on log depth quantum circuit will still requires circuits of rather small depth.) We can ask less formally if fault tolerance for any noisy quantum device which may represent a lower complexity power than universal noisy quantum computers still requires the full apparatus of current FT techniques.
Update: See also this post on Scott’s blog for further discussion on AA’s work and some links. For some further questions of computational complexity nature see this post and this reply. See also this article.
Update (Dec2012): The Aaronson-Arkhipov paper have led to several exciting experimental works. See this post over the Shtetl-optimized.
(Belated) update. A related CS-stackexchange question: The cozy neighborhoods of “P” and of “NP-hard. And a few otthers : the-complexity-of-sampling-approximately-the-fourier-transform-of-a-boolean Sampling satisfiable 3-SAT formulas.
Update (Nov 2013) Another post on Scott’s blog with a new proposal for realization.
Further remarks (21 July 2013):
1) The nice idea with BosonSampling is that if all we want to achieve is a probability distribution that cannot be approximated classically, then this can be an easier task compared to full-fledged quantum computer. Like in any implementation of quantum computation also for BosonSampling the crucial problem is errors/decoherence.
Another hope regarding BosonSampling is that perhaps we do not need to care about noise but rather to include the noise in the description of the target distribution and show (or conjecture) that even the noisy distribution is still unattainable by classical computers. But this hope seems unrealistic when we take into account the noisy computational process.
2) The AA’s model does not take into account the noise in the process for preparing the bosonic target state. Thus, important challenges for theoreticians are to give an appropriate model for the experimental process needed to create the proposed bosonic states, and to examine if quantum fault-tolerance is possible within the restricted model of boson Machines. (This is open problem (6) in AA’s paper.) The simplest such model would assume that the gates (phaseshifters and beamsplitters) are noisy. It will be interesting to develop bosonic error correcting-codes and bosonic fault-tolerance, or to figure out why this cannot be done.
3) I do not see a reason for why it will be easier to implement BosonSampling on 30 (say) bosons compared to implementing ordinary universal quantum computer with 30 qubits. It is commonly believed that quantum fault-tolerance will be needed for the universal device, even on a small number of qubits, and I don’t see a reason for why it could be avoided for the bosonic device. Indeed I was surprised when Scott offered the belief that 30-boson machines can be implemented without fault-tolerance.
4) When we study the crucial issue of synchronization and other concerns about implementation we may need to consider quantum evolutions on the large Hilbert space of n distinguishable photons and carefully model the process leading to a prescribed bosonic state of indistinguishable bosons. (This seems a good path toward the crucial issue of synchronization which is mentioned in AA’s paper, and also for dealing with other issues that cannot be described in their model.) Since we are talking about a “small” Hilbert space, described by symmetric tensors, inside a huge Hilbert space described by all tensors, we can expect that the errors will increase (even super-polynomially) with the number of photons and the number of unitary operations. This will prevent BosonSampling from scaling up. Of course, this is a matter that can be studied both experimentally and theoretically.
5) So an obvious direction for dealing with noisy Bosonic machines is to consider noisy bosonic gates, and yet another direction is to study BosonSampling in a larger Hilbert space with tensor product that seems important in any underlying realization. Another interesting study would be to stay with evolutions of indistinguishable photons and to explore how noisy unitary evolutions where the noise is described by smoothed Lindblad evolutions behaves. (See this post for a long discussion regarding these noisy evolutions.) It will be interesting to examine if smoothed Lindblad evolutions give a realistic picture for current experimental processes via phaseshifters and beamsplitters (which do not enact fault-tolerance). The whole idea of smoothed Lindblad evolutions is to describe an approximate general law – without any reference to the structure of our Hilbert space, and to the nature of “gates”- when there is a huge relevant Hilbert space which is ignored, so this can be a good place to test the idea.
6) On a technical level: AA’s paper emphasizes the question of approximating the permanent of a random Gaussian matrix, which is related to bosonic states based on random Gaussian superpositions. When you consider mixture rather than superposition (which may be more relevant to realistic noise) the question becomes (I think) that of approximating the expected value of the permanent for a (smoothed) Gaussian model. This may be a computationally tractable problem.
Connection with noise-sensitivity (July 23, 2013)
The following assertion seems most relevant to point 6: If you start with a random Gaussian matrix A and let B be a tiny Gaussian perturbation of A, then the expected value of the determinant/permanent of B will essentially not depend on A!
Here is a little more background about it:
Noise-sensitivity of maximum eigenvalue
Suppose you are given a random matrix A and a a function f(A). What you care about is how the distribution of A compares with the distribution of a small random perturbation B of A. The function f is called noise sensitive if the distribution of f(B) is very close to that of f(A). This property is related to the Fourier expansion of the function f. Sixe.seven years ago Ofer Zeitouni and I proved (but we did not wrote it down yet) that if A is Gaussian and B is a small Gaussian perturbation of A, and if the function f is the maximum eigenvalue, then f is very noise-sensitive.
Fourier-expansion of functions of matrices
Noise sensitivity is closely related to Fourier expansion, and it is an interesting question (that I asked over Mathoverflow) to understand the Fourier expansion of the set of eigenvalues, the maximum eigenvalue and related functions.
Fourier expansion of the determinant (and permanent)
At a later point I was curious about the determinant, and for the Boolean case I noticed remarkable properties of its Fourier expansion. So I decided to ask Yuval Filmus about it:
Dear Yuval
Yuval’s answer came like a cold shower:
Hi Gil,
Oh well. In any case, since the Fourier transform is supported on terms of size n, both the determinant and permanent are very noise-sensitive. This means that if you start with a random matrix A and let B be a tiny random perturbation of A, then the distribution of values of determinant/permanent of B (and hence their expectation) will essentially not depend on A. Of course, this is a hand-waving argument that should be checked carefully and so is its relevance to BosonSampling.
Avi’s Joke and common sense
Here is a quote from AA: “Besides bosons, the other basic particles in the universe are fermions; these include matter particles such as quarks and electrons. Remarkably, the amplitudes for n-fermion processes are given not by permanents but by determinants of n×n matrices. Despite the similarity of their definitions, it is well-known that the permanent and determinant differ dramatically in their computational properties; the former is #P-complete while the latter is in P. In a lecture in 2000, Wigderson called attention to this striking connection between the boson and fermion dichotomy of physics and the permanent-determinant dichotomy of computer science. He joked that, between bosons and fermions, “the bosons got the harder job.” One could view this paper as a formalization of Wigderson’s joke.”
While sharing Alex and Scott’s admiration to Avi in general and Avi’s jokes in particular, if we do want to take this joke seriously, then the common-sense approach would be first to try to understand why is it that nature treats bosons and fermions quite equally and the dramatic computational distinction is not manifested at all. The answer is that a crucial ingredient for a computational model is the model of noise/errors, and that noise-sensitivity makes bosons and fermions quite similar physically and computationally.

Pingback: Tweets that mention Aaronson and Arkhipov’s Result on Hierarchy Collapse | Combinatorics and more -- Topsy.com
Pingback: Recent posts in quantum computing « Emergent Hive
Pingback: Shtetl-Optimized » Blog Archive » The Boson Apocalypse
Pingback: What Would Be Left, If…? « Gödel’s Lost Letter and P=NP
Pingback: BosonSampling and (BKS) Noise Sensitivity | Combinatorics and more
Hi Gil,
I don’t understand the statement about det A and det B. What do you mean by the distribution of
det B does not depend on the distribution of det A ? (The determinant is a continuous function so
if B-A is small enough then det A and det B are about the same ?)
Btw, when do you come to Yale this year ? Best, Van
Dear Van, Greetings from the far west.
Noise sensitivity of a function f (the permanent in our case) means that if you have a random (complex Gaussian with variance 1, in our case) input x and a random noise N (complex Gaussian with variance t, in our case) and you consider f(noisy input) (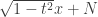 ) then the distribution of f on the noisy input hardly depends on x. For example if you consider the maximum eigenvalue of a random Gaussian matrix M and add to it a small Gaussian noise N the resulting distribution will be whp (on the choice of M) asymptotically indistinguishable from that of the maximal eigenvalue of a random Gaussian matrix (of the combined variance).
) then the distribution of f on the noisy input hardly depends on x. For example if you consider the maximum eigenvalue of a random Gaussian matrix M and add to it a small Gaussian noise N the resulting distribution will be whp (on the choice of M) asymptotically indistinguishable from that of the maximal eigenvalue of a random Gaussian matrix (of the combined variance).
I was in Yale for a couple of days last week and this fall I will spend a semester in Berkeley. I plan visiting Yale in February.
Dear Gil,
For the maximum eigenvalue M+N, M, N all have the same distribution after scaling, so the distribution of the max eigenvalue, properly normalized, is the same for all M+N, M, and N, but it does not seem to illustrate the point.
Dear Van, The point is this: Suppose you choose M at random. The maximum eigenvalue of M is now determined, (it can be, say, larger than 99% of random choices.) Now we choose N (and the variance t for N can be really small e.g. 1/n^{1/4})
The claim is that AFTER M IS CHOSEN even if the maximum eigenvalue of M is well above the median or well below the median, with high probability the distribution of the maximum eigenvalue of M+N (normalized) will be close to that for a random matrix. In other words, the distribution for M+N largely forgets M.
Hello mates, good paragraph and pleasant arguments
commented at this place, I am really enjoying by these.
Apparently, since this was not clear to some experts (and even not so fresh in my own memory when they asked me), a few more words of explanation are needed for section 4) in this post about quantum sampling and quantum fault-tolerance. When you apply quantum fault tolerance and allow polynomial number of overhaed in terms of the number of qubits (say n^4) you can reach a protected logical state on n qubits whose trace distance from the intended state is exponentially small (say exp (-n^3)). Now, the punch-line is that you measure *all* the n^5 qubits used for decoding. The quantum error correcting code is transformed under measurement to a classical error correcting code where the logical sample – 0-1 string of lenth n is encoded by a 0-1 string of length n^5. The probability that error correction will fail is again exp (- n^3). This means that all the hardness results for exact quantum sampling (by Scott and Alex and by others) apply to fault tolerant quantum computers.
Of course, we do not know to implement quantum fault tolerance within the very limited classes of quantum sampling (boson sampling, bounded depth polynomial size quantum circuits, …) for which PH collapse results are proved.
Let me also mention a nice essay by Scott on quantum sampling https://www.scottaaronson.com/blog/?p=3427 with references (and links) also to earlier relevant results by Fenner et al. and Terhal and DiVincenzo.
A couple further remarks: One can argue that the nice punchline about measurement above, is not even needed since measuring a qubit is a 1-qubit gate and quantum fault tolerance gate apply equally well to all gates, the unitary gates of the quantum computation itself and the gates for measuring. (However, this could be a bit confusing, and the punchline is shorter than a detailed argument for why it is not needed.)
Also I want to stress the conclusion: all the hardness results for exact quantum sampling applies for fault-tolerant quantum computers.
Finally, there are good theoretical evidence (similar to the argument in Scott and Alex’ paper) that scenario b) is correct. quantum sampling is considerably stronger computational class than BQP. (E.g. evidence that a classical computer with BQP oracle cannot perform quantum sampling.)
A couple more historical comments. First, Boson Sampling was considered in an early 1996 paper L. Troyansky and N. Tishby. Permanent uncertainty: On the quantum evaluation of the determinant and the permanent of a matrix.. (It is mentioned, of course, in A&A’s paper.)
Second, apparently the joke about “Bosons having harder time” was first made by Tishby in response to a lecture by Wigderson on the computational complexity of permanents in the mid 90s, and Tishby;s joke have led to his 1996 paper with Troyansky. Of course, finding the precise historical origins of jokes and giving correct credit for them is extremely important.
“Of course finding the precise historical origins of joke and giving correct credit for them is extremely important.” This is a joke, of course. (Which is why proper credit for it is extremely important.)
Pingback: Photonic Huge Quantum Advantage ??? | Combinatorics and more