
Two experimental results of 10/100 and 15/100 are not equivalent to one experiment with outcomes 3/200.
(Here is a link to the original post.)
One way to see it is to think about 100 experiments. The outcomes under the null hypothesis will be 100 numbers (more or less) uniformly distributed in [0,1]. So the product is extremely tiny.
What we have to compute is the probability that the product of two random numbers uniformly distributed in [0,1] is smaller or equal 0.015. This probability is much larger than 0.015.
Here is a useful approximation (I thank Brendan McKay for reminding me): if we have 
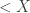
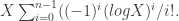
In this case 0.015 * ( 1 – log(0.015) ) = 0.078
So the outcomes of the two experiments do not show a significant support for the theory.
The theory of hypothesis testing in statistics is quite fascinating, and of course, it became a principal tool in science and led to major scientific revolutions. One interesting aspect is the similarity between the notion of statistical proof which is important all over science and the notion of interactive proof in computer science. Unlike mathematical proofs, statistical proof are based on following certain protocols and standing alone if you cannot guarantee that the protocol was followed the proof has little value.

Interesting. But I don’t see any simple way to derive the formula
you used. Any suggestions?
It’s probably worth mentioning that this is basically Fisher’s method for combining p-values.
[Thanks! I did not know that this method goes back to Fisher. But now I found a Wikipedia article about it. G.]
I just recovered a very interesing comment by Nick to the original post.
I received the following email from a friend, and I couldn’t resist bragging about it.
Hi Gil,
I spend way too much time aimlessly surfing the Internet. Yet, every now and then, it leads to something useful. This just happened to me:
Last week, in trying to help an applied researcher with a statistics problem, I began to reinvent Fisher’s method for combining tests of the same null hypothesis. Of course I understood that this must have been well known and that I should do a literature search, but I procrastinated. Then, now this morning, while doing my usual aimless tour of the Internet, something led me to ask myself what you have been up to lately, so I looked up your blog and found Fisher’s test in you very latest blog entry.
Thanks!
Hi,
I don’t have much background in statistics but I feel as if there is still something left unsaid here. The original question was “why can’t you multiply the probabilities”. But the outcomes in the two groups are assumed to be independent, so why not? The probability that a random person in the first group ranks within 10% & a random person in the second group ranks within 15% is, in fact, 3/200.
To me, the problem with this argument is that you frame your event of choice after you see the outcome. After 100 experiments, whatever happened, you can pick a suitable event of probability 1/2^100 which just happened to occur.
But this can happen even in one experiment. To make it more glaring, suppose I compare the heights of 1000 people and I see that the person who was born 7/7 ranks #128. I can say “wow, the rank of this person is the 7th power of an integer, how unlikely is that!! there must be something going on here”.
It seems to me Gil’s explanation relies on some hidden assumptions, such as “down-monotone events being considered reasonable”, which seems related to p-values and such, but I’m missing the background here.
Dear Jan
I think you make a very correct point. The probability of the event that a random person in the first group is ranked among the top 15% AND a random person in the second group is ranked among the first 10% is indeed 3/200. But this is different from the question we were asking.
It is also correct that this problem is closely related to the issue of testing statistically some apriori conjectures compared to exploring surprising facts in given data.
@RD
y=log x
then calculate the SUM of y’s