
I would like to start here a research thread of the long-promised Polymath3 on the polynomial Hirsch conjecture.
I propose to try to solve the following purely combinatorial problem.
Consider t disjoint families of subsets of {1,2,…,n}, 
Suppose that
(*) For every 




The basic question is: How large can t be???
(When we say that the families are disjoint we mean that there is no set that belongs to two families. The sets in a single family need not be disjoint.)
In a recent post I showed the very simple argument for an upper bound 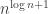
A polynomial upper bound for 



The abstract setting is taken from the paper Diameter of Polyhedra: The Limits of Abstraction by Freidrich Eisenbrand, Nicolai Hahnle, Sasha Razborov, and Thomas Rothvoss. They gave an example that
We had many posts related to the Hirsch conjecture.
Remark: The comments for this post will serve both the research thread and for discussions. I suggested to concentrate on a rather focused problem but other directions/suggestions are welcome as well.
Let’s call the maximum t, f(n).
Remark: If you restrict your attention to sets in these families containing an element m and delete m from all of them, you get another example of such families of sets, possibly with smaller value of t. (Those families which do not include any set containing m will vanish.)
Theorem: \le f(n-1)+2f(n/2)")
Proof: Consider the largest s so that the union of all sets in 
")
Consider the largest r so that the union of all sets in 
")
Now, by the definition of s and r, there is an element m shared by a set in the first s+1 families and a set in the last r+1 families. Therefore (by (*)), when we restrict our attention to the sets containing ‘m’ the families 
")
Remarks:
1) The abstract setting is taken from the paper by Eisenbrand, Hahnle, Razborov, and Rothvoss (EHRR). We can consider families of d-subsets of {1,2,…, n}, and denote the maximum cardinality t by ")
 \le 2f(d,n/2)+f(d-1,n-1)")

\le n{{\log n+d}\choose{\log n}}")
2) ")




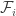
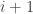
3) For the diameter of graphs of polytopes we can restrict our attention to simple polytopes namely for the case that all sets
4) Why the families of graphs of simple polytopes satisfy (*)? Because if you have a vertex 







5) EHRR considered also the following setting: consider a graph whose vertices are labeled by 

Pingback: Brawer Hirsch And Assoc Pa lawyer in Fort Lauderdale | Florida Personal Injury Lawyer
Dear Gil,
I’ve only recently thought about this problem again, so let me just throw some thoughts out there. I have been considering a variant of this problem where instead of sets one allows multisets of fixed cardinality d, or equivalently monomials of degree d over n variables.
In this setting, there is actually a very simple construction that gives a lower bound of d(n-1) + 1, the sequence of multisets (for the case d=4 but it easily generalizes):
1111, 1112, 1122, 1222, 2222, 2223, etc.,
Note that here we have a family of multi-sets where each family in fact only contains a single multi-set. There are alternative constructions that achieve the same “length” without singletons, e.g. you can also partition all d-element multisets into families and achieve d(n-1) + 1.
My current guess would be that this construction is best possible, i.e. I would conjecture d(n-1) + 1 to be an upper bound.
This upper bound holds for all _partitions_ of the d-multisets into families, i.e. it holds in the case where every multi-set appears in exacly one of the families, via a simple inductive argument: Take one multiset from the first family and one of the last, then take a (d-1)-subset of the first and one element of the last. The union is a d-multiset that must appear in one of the families, proceed by induction on the “dimension” d.
So to disprove my guess for the upper bound would require cleverly _not using_ certain multisets somehow.
The upper bound holds for n <= 3 and all d, d <= 2 and all n, and – provided that I made no mistake in my computer codes – it also holds for:
– n=4 and d<= 13
– n=5 and d<= 7
– n=6 and d<= 5
– n=7 and d<=4
– n=8 and d=3
Yes, the order of n and d is correct. I used SAT solvers to look for counter-examples to my hypothesis, and I stopped when I reached instances that ran out of memory after somewhere between one and two weeks of computation.
The case that bugs me the most personally is that I could not prove anything for d=3, where the best upper bound I know of is essentially 4n (via the Barnette/Larman argument for linear diameter in fixed dimension). Though it would be also interesting to think about what can be said about fixing n=4.
I have not given the problem any thought yet in the form that you stated it; I will give it a try, maybe it leads to some ideas that I haven't thought of in the "dimension-constrained" version that I looked at.
Dear Nicolai,
This is very interesting! Pleas do elaborate on the various general constructions giving d(n-1)+1. The argument that it is tight for families which contains all elements is also interesting. Can’t you get even better constructions for multisets based on the ideas from your paper?
Here’s a construction giving d(n-1)+1 that partitions the set of d-multisets. Take the groundset of n elements to be {0,1,2,…,n-1} and define for each multiset S the value s(S) to be the sum of its elements. Then the preimages of the numbers 0 through d(n-1) partition the multisets into families with the desired property.
This is the only other general construction I have. There are other examples for small cases that I found, and it seems like in general there should be many such examples, though so far I can only back this up with fuzzy feelings.
As for the constructions of the paper, interestingly it turns out that the two variants (with sets and with multisets) are in a sense asymptotically equivalent. Basically, what we do in the paper can be interpreted in the following way.
You start with the simple multiset construction that I outlined in my earlier post using {1,2,…,n} as your basic set. Then you get a set construction on the set {1,2,…,n}x{1,2,…,m} by replacing each of the multisets in the original by one of the blocks that we construct in the paper using disjoint coverings. It turns out that this can be generalized to starting with arbitrary multisets.
What you get is a result somewhat like this: if f(d,n) is the upper bound in the sets variant and f'(d,n) is the upper bound on the multisets variant, then of course f(d,n) <= f'(d,n) just by definition, and by the construction f'(d,nm) <= DC(m) f(d,n), where the DC(m) part is essentially the number of disjoint coverings you can find, as this determines the "length" of the blocks in the construction.
I’ve started a wiki page for this project at
http://michaelnielsen.org/polymath1/index.php?title=The_polynomial_Hirsch_conjecture
but it needs plenty of work, ideally by people who are more familiar with the problem than I.
Pingback: Polymath3 (polynomial Hirsch conjecture) now officially open « The polymath blog
One place to get started is to try to work out some upper and lower bounds on f(n) (the largest t for which such a configuration can occur) for small n, to build up some intuition.
I take it all the families F_i are assumed to be non-empty? Otherwise there is no bound on t because we could take all the F_i to be empty.
Assuming non-emptiness (and thus the trivial bound f(n) <= 2^n), one trivially has f(0)=1 (take F_1 to consist of just the emptyset), f(1)=2 (take F_1 = {emptyset}, F_2 = { {1} }, say), and f(2) = 4 (take F_1 = {emptyset}, F_2 = { { 1 } }, F_3 = { { 1,2} }, F_4 = { { 2 } }), if I understand the notations correctly.
So I guess the first thing to figure out is what f(3) is…
I can show f(3) can’t be 8. In that case, each of the families would consist of a single set, and one of the families, say F_i, would consist of the whole set {1,2,3}. Then the sets in F_1, …, F_{i-1} must be increasing, as must the sets in F_8, …, F_{i+1}. Only one of these sequences can grab the empty set and have length three; the other can have length at most 2. This gives a total length of 3+1+2 = 6, a contradiction.
On the other hand, one can attain f(3) >= 6 with the families {emptyset}, {{2}}, {{1,2}}, {{1}}, {{1,3}}, {{3}}.
Not sure whather f(3)=7 is true yet though.
More generally, one might like to play with the restricted function f'(n), defined as with f(n) except that each of the F_i are forced to be singleton families (i.e. they consist of just one set F_i = A_i, with the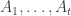 distinct). The condition (*) then becomes that
distinct). The condition (*) then becomes that  whenever
whenever 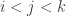 . It should be possible to compute f'(n) quite precisely. Unfortunately this does not upper bound f(n) since
. It should be possible to compute f'(n) quite precisely. Unfortunately this does not upper bound f(n) since  , but it may offer some intuition.
, but it may offer some intuition.
[Gil, if you can fix the latex in my previous comment that would be great. GK:done]
I can now rule out f(3)=7 and deduce that f(3)=6. The argument from 8:19pm shows that if one of the families contains {1,2,3}, then there must be an ascending chain to the left of that family and a descending chain to the right giving at most 6 families, a contradiction. So we can’t have {1,2,3} and so must distribute the remaining seven subsets of {1,2,3} among seven families, so that each family is again a singleton.
The sets {1}, {2}, {3} must appear somewhere; without loss of generality we may assume that {1} appears to the left of {2}, which appears to the left of {3}. Then none of the families to the left of {2} can contain a set that contains 3, and none of the families to the right can contain a set that contains 1. In particular there is nowhere for {1,3} to go and so one cannot have seven families.
Pingback: Polymath3 « Euclidean Ramsey Theory
I may be making a stupid error here, but it seems that the proof of
in the previous post
can be easily modified to give
which would then give the polynomial growth bound
Indeed, if we have t families F_1, …, F_t, we let s be the largest number such that is supported in a set of size at most 2n/3, and similarly let r be the largest number such that
is supported in a set of size at most 2n/3, and similarly let r be the largest number such that 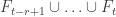 is supported in a set of size 2n/3. Then s and r are at most
is supported in a set of size 2n/3. Then s and r are at most  , and there is a set of size at least n/3 that is common to at least one member of each of the intermediate families
, and there is a set of size at least n/3 that is common to at least one member of each of the intermediate families  . Restricting to those members and then deleting the common set, it seems to me that we have
. Restricting to those members and then deleting the common set, it seems to me that we have 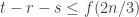 , which gives the claimed bound, unless I’ve made a mistake somewhere…
, which gives the claimed bound, unless I’ve made a mistake somewhere…
Are $F_{s+1},\ldots,F_{t-r}$, with the common set removed, disjoint?
The proof of $f(n) \leq f(n-1) + 2 f( n/2 )$ is incomplete as it also fails to show that the reduced intermediate families are disjoint.
It seems that the f'(n) (suggested at 8:22pm comment) are easy to figure out: Look at the first and second sets in the list, some element x is in the first but not in the second. This x can never appear again in the list of sets, so we get the recursion f'(n) <= f'(n-1)+1, and thus f'(n)<=n which can be achieved by the list of singletons. Somethings similar should apply also if we allow multisets (as in the first comment), where each time the maximum allowed multiplicity of some element decreases by 1, never to increase again.
Noam, it could be that the first set is completely contained in the second, but of course this situation cannot continue indefinitely, so one certainly gets a quadratic bound f'(n) = O(n^2) at least out of this.
Gil, I was reading the Eisenbrand-Hahnle-Razborov-Rothboss paper and they seem to have a slightly different combinatorial setup than in your problem, in which one has a graph whose vertices are d-element subsets of [n] with the property that any two vertices u, v are joined by a path consisting only of vertices that contain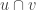 . Could you explain a bit more how your combinatorial setup is related to this (if it is), and what the connection to the polynomial Hirsch conjecture is?
. Could you explain a bit more how your combinatorial setup is related to this (if it is), and what the connection to the polynomial Hirsch conjecture is?
Terry, regarding the 11:32 attempt, I think that the bug is that even though the support of the prefix has a n/3 intersection with the support of the suffix this does not imply that this intersection is common to every set in the middle but rather only to the support of the middle.
Lets fix the f'(n) bound to at least f'(n)<=2n (not tight, it seems). Define f'(n,k) to be the max length you can get if the first set in the sequence has size k. So, I would claim that f'(n.k)k then we have f'(n,k) <=1 + f'(n,k')
If k=k' then we have f'(n,k) <= 1+f'(n-1,k) (since some element was removed and will never appear again
If k'<k then we have f'(n,k) <= 1+f'(n-(k-k'), k') (since at least k' were removed forever)
the last comment got garbled… i was claiming that f'(n,k)<=2n-k.
Ah, I see where I went wrong now, thanks!
(Gil: can you set the thread depth in comments from 1 to 2? This makes it easier to reply to a specific comment.)
Noam, I don’t see how one can derive f'(n) <= 2n, though I do find the bound plausible. I can get f'(n) <= n + f'(n-1) but this only gives a quadratic bound.
I did not believe I can set it, but I succeded!!!
Is it not trivial that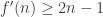 ?
?
Take {1,…,i} for
{1,…,i} for 
 {(i-n+2),…,n}$ for
{(i-n+2),…,n}$ for 
Take
In general, if each is a single set then the families must be convex in the “i”-direction in the sens that if an element in present in two sets then it must be present in all sets between them.
is a single set then the families must be convex in the “i”-direction in the sens that if an element in present in two sets then it must be present in all sets between them.
Well, it’s late at my end of the world so I’ll look in tomorrow again.
That should have said that the first sets are of the form {1,…,i} and the later sets of the form {i-n+1,…,n}
Ah, it looks like f'(n) = 2n for all n. To get the lower bound, look at
{}, {1}, {1,2}, {1,2,3}, …, {1,2,..,n}, {2,..,n}, {3,…,n}, …, {n}.
To get the upper bound, we follow Noam’s idea and move from each set to the next. When we do so, we add in some elements, take away some others, or both. But once we take away an element, we can never add it back in again. So each element gets edited at most twice; once to put it in, then again to take it out. (We can assume without loss of generality that we start with the empty set, since there’s no point putting the empty set anywhere else, and it never causes any harm.) This gives the bound of 2n.
I think the same argument gives f'(n,k) = 2n-k (or maybe 2n-k+1).
There is another nice way to construct a maximal sequence, we start with {}, {1},{1,2},{2},….{i,i+1},{i+1},{i+1,i+2},{i+2}…. This also gives length 2n, and uses only small sets.
A nice way to visualize this family is that we are following a hamiltonian path in a graph and alternatingly state the edges and vertices we visit.
I guess I just repeated what Klas said. 🙂
Pingback: Polymath3 now active « What’s new
It should be possible to compute f(4). We have a general lower bound which gives f(4) >= 8, and the recursion (if optimised) gives f(4) 2 and
which gives f(4) >= 8, and the recursion (if optimised) gives f(4) 2 and  (as there are not enough sets containing
(as there are not enough sets containing 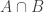 to fill the intervening families, now that 1234 is out of play). I also know that without loss of generality one can take
to fill the intervening families, now that 1234 is out of play). I also know that without loss of generality one can take  (or one can simply remove the empty set family altogether and drop f(n) by one). This already eliminates a lot of possibilities, but I wasn’t able to finish the job.
(or one can simply remove the empty set family altogether and drop f(n) by one). This already eliminates a lot of possibilities, but I wasn’t able to finish the job.
Oops, wordpress ate a chunk of my previous post. Here is another attempt (please delete the older post)
It should be possible to compute f(4). We have a general lower bound which gives f(4) >= 8, and the recursion (if optimised) gives
which gives f(4) >= 8, and the recursion (if optimised) gives  . Actually I conjecture f(4)=8, after failing several times to create a 9-family sequence. What I can say is that given a 9-family sequence, one cannot have the set 1234={1,2,3,4} (as this creates an ascending chain to the left and a descending chain to the right, which leads to at most 8 families). I also know that there does not exist F_i, F_j with
. Actually I conjecture f(4)=8, after failing several times to create a 9-family sequence. What I can say is that given a 9-family sequence, one cannot have the set 1234={1,2,3,4} (as this creates an ascending chain to the left and a descending chain to the right, which leads to at most 8 families). I also know that there does not exist F_i, F_j with  that contains A, B respectively with
that contains A, B respectively with  (as there are not enough sets containing to fill the intervening families, now that 1234 is out of play). I also know that without loss of generality one can take
(as there are not enough sets containing to fill the intervening families, now that 1234 is out of play). I also know that without loss of generality one can take 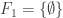 (or one can simply remove the empty set family altogether and drop f(n) by one). This already eliminates a lot of possibilities, but I wasn’t able to finish the job.
(or one can simply remove the empty set family altogether and drop f(n) by one). This already eliminates a lot of possibilities, but I wasn’t able to finish the job.
I think it’s easy to show that f'(n) <2n+1. Each element i is contained in the sets [F_b_i, F_b_i+1,…,F_e_i]. So we have n intervals corresponding to n elements. Since all sets are different each set has to be either a beginning or an end of an interval, so we can't have more that 2n.
On my flight down to Stockholm this moring I thought about this problem afgain and I think I can push the lower bound up a bit.
Define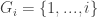 and for
and for 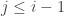 w define
w define  . Now order the
. Now order the 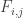 lexicographically according to the indices. Unless I’ve missed something this gives a quandratic lower bound on f(n)
lexicographically according to the indices. Unless I’ve missed something this gives a quandratic lower bound on f(n)
Right away I don’t see why this can’t be done with more indices on the “ ” families. E.g. for
” families. E.g. for 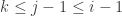 take
take  and order them lexicographically. But if we do this with a number of indices which grows with n we seem to get a superpolynomial lower bound, which makes me a bit worried.
and order them lexicographically. But if we do this with a number of indices which grows with n we seem to get a superpolynomial lower bound, which makes me a bit worried.
Now it’s time for me to pick up my luggage and travel on.
As stated earlier this example does not work because it violates the disjointness condition in the definition of the problem.
Here’s an alternative perspective on the problem. Take an n-dimensional cube, its vertices corresponding to sets. Now color a subset of its vertices using the integers such that for certain faces F one has the constraint:
(*) The colors in F have to be contiguous subset of integers.
What is the maximum number of colors that such a coloring can have?
If the set of faces on which (*) has to hold is the set of all faces containing a designated special vertex (corresponding to {1,2,…,n}), then this is just a reformulation of the original problem.
On the other extreme, if (*) has to hold for all faces, then the maximum number of colors is n+1:
Restrict to the smallest face containing both the min and max color vertex. (u and v respectively) If this face contains no other colored vertex, one is done. Otherwise, take a third vertex w and recurse on the minimum faces containing u and w, and w and v, respectively.
Can one say anything about the case where the faces on which (*) has to hold is somewhere between those two extremes?
I like this alternate perspective, but I don’t quite see why it’s a reformulation of the original problem when you consider faces that contain a designated vertex. It seems to me that this colouring version of the problem corresponds to following constraint in the original problem: for each $i$< $j$< $k$ and for each $a$, if $a \in S \in F_i$ and $a \in T \in F_k$ for some $S$ and $T$, then there exists $U \in F_j$ with $a \in U$. And this doesn’t seem quite the same as the original constraint; e.g., $F_1 = \{\{1,2,3\}\}$, $F_2 = \{\{2\}, \{3\}\}$, $F_3 = \{\{2,3,4\}\}$ seems to satisfy the colouring constraint but not the original constraint.
Perhaps I’ve not understood things properly though…
Nicolai meant faces of any dimension containing the designated vertex. You took only faces of co-dimension 1. Hence the discrepancy.
In the following I try to generalize the idea of Terence Tao that you cannot
have a big set (the full set in his case) in a family. I hope proof is right and
that I did not mess up with the constants.
Let $F_1,..,F_l$ be a sequence of disjoint families of sets over $[n]$ which satisfy condition (*).
Say that $\{1,\dots,n-k\} \in F_l$, we prove that $l \leq (n-k+1) f(k)$.
Let $S_i \in F_i$ and write $A_i$ for its restriction to $[n-k]$.
Because of condition (*), we have a sequence of sets $S_1,\dots,S_l$ such that
the sequence $A_1,\dots,A_l$ is increasing (non necessarily strictly) (you build it as in the case of one set by family).
Moreover, we can choose each $A_i$ to be maximal for the restriction of the sets of $F_i$ to $[n-k]$.
Let $A_j$ the first set of size $s$ and let $A_w+1$, the first set of size strictly greater than $s$.
We have $A=A_j=A_{j+1} = \dots = A_{w}$.
Consider now the restriction of $F_j,\dots,F_{w}$ to elements containing $A$:
we remove $A$ from these elements and we remove the others entirely.
We have a sequence of disjoint families $F’_{j},\dots,F’_{w}$ over $[n] \setminus A$ which satisfy
(*). Since $A$ has been chosen to be maximal, the families $F’_{j},\dots,F’_{w}$ contains only sets over $\{n-k+1,\dots,n\}$.
Therefore $w-j+1 \leq f(k)$. Since there are at most $n-k+1$ possible sizes of sets $A_i$,
we have $l \leq (n-k+1) f(k)$.
Therefore if there is a set of size $k$ in one of the family $F_i$ in a sequence $F_1,\dots,F_t$,
$t \leq (2 (n-k)+1) f(k)$.
This idea is an attempt to give a different upper bound to $f(n)$
and maybe to obtain $f(4)=8$.
For $n=4$ and $k=1$, that is $\{1,2,3\}$ appears in a family,
we have $t \leq (2(4-1)+1)(f(1)-1)=7$ : it rules out this case.
For $n = 4$ and $k=2$, that is $\{1,2\}$ appears in a family, we have $t \leq (2(4-2)+1)(f(2)-1) = 15$
and it does not give anything interesting.
We could try to improve this result by using the constraints
between sequences of the form $A_j,\dots,A_w$.
I’m trying to concentrate on the case where the support of each family is the entire set [n]. I think it suffices to establish the polynomial estimate for this case since, in the generic case, the support can only change 2n-1 times.
For the case of 4 I seem to have found the chain of length 6 : {{1},{2},{3},{4}}, {{23},{13},{24}}, {{123},{234}}, {{1234}},{{134,124}},{{14,12,34}} and I’m pretty convinced there’s no chain of length 7.
I think I can show f(4) is less than 11.
Assume we have 11 or more elements then 8 types of
sets in terms of which of the the first three elements are
in the set.
We must have a repetition of the same type in
two different families.
Then every set must contain an element
that contains the 3 elements of the repetition.
Now if the repetition is not null there can be
at most 8 elements that contain the repetition
but we have 9 families besides A and B and so there is a contradiction.
Now we can repeat this argument for each set of
four elements. so we have at most 5 families containing the
null set and each single element. And we have adding
one element not in a set in a family and having the resulting
augmented set outside the family is forbidden.
so outside of the 5 sets that contain
the singleton elements and the null set there are no
two element sets, no single element sets
and no null set. but that leaves 5 elements for 6
sets which gives a contradiction. So f(4) cannot be 11.
Apologies if I ask questions that are answered in earlier comments or earlier discussion posts on this problem. It occurred to me that if we are trying to investigate sequences of set systems such that for every
such that for every  a certain property holds, then it might be interesting to try to understand what triples with that property can be like. That is, suppose you have three families
a certain property holds, then it might be interesting to try to understand what triples with that property can be like. That is, suppose you have three families 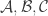 of subsets of
of subsets of ![[n]](https://s0.wp.com/latex.php?latex=%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) such that no set belongs to more than one family, and suppose that for every
such that no set belongs to more than one family, and suppose that for every  and every
and every  there exists
there exists 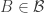 such that
such that  What can these families be like?
What can these families be like?
At this stage I have so little intuition about the problem that I’d be happy with a few non-trivial examples, whether or not they are relevant to the problem itself. To set the bar for non-triviality, here’s a trivial example: insist that all sets in are contained in
are contained in ![[1,s]](https://s0.wp.com/latex.php?latex=%5B1%2Cs%5D&bg=ffffff&fg=333333&s=0&c=20201002) and not contained in
and not contained in ![[r,s]](https://s0.wp.com/latex.php?latex=%5Br%2Cs%5D&bg=ffffff&fg=333333&s=0&c=20201002) (where
(where 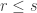 ), that all sets in
), that all sets in  are contained in
are contained in ![[r,n]](https://s0.wp.com/latex.php?latex=%5Br%2Cn%5D&bg=ffffff&fg=333333&s=0&c=20201002) but not in
but not in ![[r,s],](https://s0.wp.com/latex.php?latex=%5Br%2Cs%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002) and that
and that  contains the set
contains the set ![[r,s].](https://s0.wp.com/latex.php?latex=%5Br%2Cs%5D.&bg=ffffff&fg=333333&s=0&c=20201002)
Now any example that looks anything like that is fairly hopeless for the problem because if you have a parameter that “glides to the right” as the family “glides to the right” then it can take at most values, so there can be at most
values, so there can be at most  families.
families.
Let me ask a slightly more precise question. Are there good examples of triples of families where the middle family has several sets, and needs to have several sets?
Actually, I’ve thought of an example, but it’s somehow trivial in a different way. Let be a fairly large collection of random sets and let
be a fairly large collection of random sets and let  be another fairly large collection of random sets, chosen to be disjoint. (That is, choose a large collection of random sets and then randomly partition it into two families.) Now let
be another fairly large collection of random sets, chosen to be disjoint. (That is, choose a large collection of random sets and then randomly partition it into two families.) Now let  consist of all sets
consist of all sets 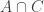 such that
such that  and
and 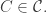 Then trivially it has the property we want, and since with high probability the sets in
Then trivially it has the property we want, and since with high probability the sets in  have size around
have size around 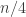 and the sets in
and the sets in  and
and  have size around
have size around  the three families are disjoint.
the three families are disjoint.
This raises another question. Is there a useful sense in which this second example is trivial? (By “useful sense” I mean a sense that shows that a random construction like this couldn’t possibly be used to create a counterexample to the combinatorial version of the polynomial Hirsch conjecture.)
Another weirdness is that my last comment has appeared before some comments that were made several hours earlier.
Let me think briefly about random counterexamples. Basically, I have an idea for such an example and I want to check that it doesn’t work.
The idea is this. If you take a random collection of sets of size then as long as it is big enough its lower shadow at the layer
then as long as it is big enough its lower shadow at the layer  will be full. (By that I mean that every set of size
will be full. (By that I mean that every set of size  will be contained in one of the sets in the collection.) Also, as long as it is small enough, the intersection of any two of the sets will have size about
will be contained in one of the sets in the collection.) Also, as long as it is small enough, the intersection of any two of the sets will have size about  I can feel this not working already, but let me press on. If we could get both properties simultaneously, then we could just take a whole bunch of random set systems consisting of sets of size
I can feel this not working already, but let me press on. If we could get both properties simultaneously, then we could just take a whole bunch of random set systems consisting of sets of size 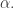 Any two sets in any two of the collections would have small intersection and would therefore be contained in at least one set from each collection. This is of course a much much stronger counterexample than is needed, since it dispenses with the condition
Any two sets in any two of the collections would have small intersection and would therefore be contained in at least one set from each collection. This is of course a much much stronger counterexample than is needed, since it dispenses with the condition  So obviously it isn’t going to work.
So obviously it isn’t going to work.
[Quick question: does anyone have a proof that you can’t have too many disjoint families of sets such that any three families in the collection have the property we are talking about? Presumably this is not hard.]
But in any case it’s pretty obvious that if you’ve got enough sets to cover all sets of size then you’re going to have to have some intersections that are a bit bigger than that.
then you’re going to have to have some intersections that are a bit bigger than that.
Nevertheless, let me do a quick calculation in case it suggests anything. If I want to choose a random collection of sets of size in such a way that all sets of size
in such a way that all sets of size  are covered, then, crudely speaking, I need the probability of choosing a given set of size
are covered, then, crudely speaking, I need the probability of choosing a given set of size  to be the reciprocal of the number of
to be the reciprocal of the number of  -sets containing any given
-sets containing any given  -set. That is, I need to take a probability of
-set. That is, I need to take a probability of  That’s actually the probability that means that the expected number of sets in the family that contain any given
That’s actually the probability that means that the expected number of sets in the family that contain any given  -set is 1, which isn’t exactly right but gives the right sort of idea. So if
-set is 1, which isn’t exactly right but gives the right sort of idea. So if  and
and  then we get that the number of sets is
then we get that the number of sets is 
Hmm, the other probability I wanted to work out was the probability that the intersection of two sets of size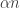 has size substantially different from
has size substantially different from  In that way, I wanted to work out how many sets you could pick with no two having too large an intersection. If that was bigger than the size above then it would be quite interesting, but of course it won’t be.
In that way, I wanted to work out how many sets you could pick with no two having too large an intersection. If that was bigger than the size above then it would be quite interesting, but of course it won’t be.
Quick question: does anyone have a proof that you can’t have too many disjoint families of sets such that any three families in the collection have the property we are talking about? Presumably this is not hard.
The elementary argument kills this off pretty quickly and gives a bound of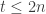 in this case. Indeed, the case n=1 follows from direct inspection, and for larger n, once one has t families for some
in this case. Indeed, the case n=1 follows from direct inspection, and for larger n, once one has t families for some 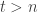 , two of them have a common element, say n; then the other t-2 families must have sets that contain n. Now restrict to those sets that contain n, then delete n, and we get from induction hypothesis that
, two of them have a common element, say n; then the other t-2 families must have sets that contain n. Now restrict to those sets that contain n, then delete n, and we get from induction hypothesis that  , and the claim follows.
, and the claim follows.
A rather general question is this. A basic problem with trying to find a counterexample is that the linear ordering on the families makes it natural to try to associate each family with … something. But what? With a ground set of size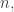 using the ground set is absolutely out. So we need to create some other structure. Klas tried this above, with the set
using the ground set is absolutely out. So we need to create some other structure. Klas tried this above, with the set 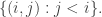 I vaguely wonder about something geometric, but I start getting the problem that if one has a higher-dimensional structure (in order to get more points) then one still has to find a nice one-dimensional path through it. Maybe something vaguely fractal in flavour would be a good idea. (Please don’t ask me to say more precisely what I mean by this …)
I vaguely wonder about something geometric, but I start getting the problem that if one has a higher-dimensional structure (in order to get more points) then one still has to find a nice one-dimensional path through it. Maybe something vaguely fractal in flavour would be a good idea. (Please don’t ask me to say more precisely what I mean by this …)
I am sorry about the wordpress strange behavior.
For improved lower bounds: Considering random examples for our families is appealing. One general “sanity test” (suggested by Jeff Kahn) that is rather harmfull to some random suggestion is: “Check what the proof does for the example.” Often when you look at such an example then the union of the sets in the first very few families will be everything and also in the very few last families. And this looks to be the case also when you restrict yourself to sets containing certain elements. This “sanity check” does not kill every random example but it is useful.
For improved upper bounds: In the present proof in order to reach a set R from the first r families and a set T from the last r families so that R and T share k elements we can only guarantee that for
r = f(n/2) + f((n-1)/2)+ f((n-2)/2))+…+ f((n-k)/2).
Somehow it looks that when k is large we can do better. And that we do not have to waste so much effort further down in the recursion.
In particular we reach the same set in the first r families and last r families for r around roughly nf(n/2) it would be nice to improve it.
I think I can show f(4) is less than 10. We have it
must be less than 11 previously.
Assume we have 10 or more elements then there are 8 types of
sets in terms of which of the the first three elements are
in the set. We must have a repetition of the same type in
sets in two different families.
Then every set must contain an element
that contains the 3 elements of the repetition.
Now if the repetition is not null there can be
at most 8 elements that contain the repetition
but we have 8 families besides A and B and so there is a contradiction.
But we can improve this since we have two instances of the repetition
in the first two elements so we have at most 6 unused elements.
Now we can repeat this argument for each set of
four elements. so we have at most 5 families containing the
null set and each single element. And we have adding
one element not in a set in a family and having the resulting
augmented set outside the family is forbidden.
so outside of the 5 sets that contain
the singleton elements and the null set there are no
two element sets, no single element sets
and no null set. but that leaves 5 elements for 5
sets. This means that each family must contain one of the
sets with more than two elements. In particular one must
contain the set with four elements and one a set with three
elements. Then since their intersection will have three elements
every family must have a set with three elements but there are not
enough sets with three elements to go around.
sets which gives a contradiction. So f(4) cannot be more than 9.
Gil, could you remind us what is known about the case d=2? From your previous blog post I understand that f(2,n)=O(n log^2 n), while the only construction I can see is f(2,n) is of length n-1. Are these the best that is known?
I think that the following argument establishes an O(nlogn) upper bound for f(2,n): Define the “prefix-support” of an index i to be the support of all sets in all F_j for ji. Now let us ask whether there exists some i in the middle third (t/3 <i < 2t/3) such that the intersection of the prefix-support and the suffix-support of i is less than k=n/log(n). If not, then every F_i in the middle third must have at least n/(2k) pairs in it so then t/3 is bounded by the the total number of pairs (n choose 2) divided by n/(2k), which gives an O(nlogn) bound on t (for k=n/logn). Otherwise, fix such i, and let m be the size of of the prefix-support, so the size of the suffix-support is at most n-m+k, and we get the recursion , which (I think) solves to O(nlogn) for k=n/logn when taking into account that m=theta(n).
, which (I think) solves to O(nlogn) for k=n/logn when taking into account that m=theta(n).
WordPress ate part of the definitions in the beginning: the prefix-support of i is the support of $latex \cup_{ji} F_j$.
WordPress ate the LaTex again, so lets try verbally: the prefix-support is the combined support of all set systems that come before i, while suffix-support is the support of all sets that come after i.
OK, this was not only garbled by wordpress but also by myself and is quite confused and with typos. I think it still works, and will try to write a more coherent version later…
As another attempt to gain intuition, I want to have a quick try at a just-do-it construction of a collection of families satisfying the given condition. Let’s call the families I’m trying (with no hope of success) to construct
The pair of families with most impact on the other families is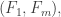 so let me start by choosing those so as to make it as easy as possible for every family in between to cover all the intersections of sets in
so let me start by choosing those so as to make it as easy as possible for every family in between to cover all the intersections of sets in 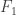 and sets in
and sets in 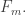 Before I do that, let me introduce some terminology (local to this comment unless others like it). I’ll write
Before I do that, let me introduce some terminology (local to this comment unless others like it). I’ll write  for the “pointwise intersection” of
for the “pointwise intersection” of  and
and 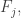 by which I mean
by which I mean 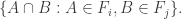 And if
And if  and
and  are set systems I’ll say that
are set systems I’ll say that  covers
covers  if for every
if for every 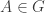 there is some
there is some  such that
such that 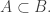 Then the condition we want is that
Then the condition we want is that  covers
covers  whenever
whenever 
If we want it to be very easy for the families with
with  to cover
to cover  then the obvious thing to do is make
then the obvious thing to do is make 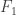 and
and 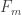 as small as possible and to make the intersections of the sets they contain as small as possible as well. Come to think of it (and although this must have been mentioned several times, it is only just registering with me) it’s clear that WLOG there is just one set in
as small as possible and to make the intersections of the sets they contain as small as possible as well. Come to think of it (and although this must have been mentioned several times, it is only just registering with me) it’s clear that WLOG there is just one set in 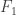 and one set in
and one set in  because making those families smaller does not make any of the conditions that have to be satisfied harder.
because making those families smaller does not make any of the conditions that have to be satisfied harder.
A separate minimality argument also seems to say that WLOG not only are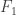 and
and 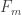 singletons, but they are “hereditarily” singletons in that their unique elements are singletons. Why? Well, if
singletons, but they are “hereditarily” singletons in that their unique elements are singletons. Why? Well, if 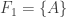 then removing an element from
then removing an element from  does not make anything harder (because
does not make anything harder (because 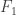 is not required to cover anything) and makes all covering conditions involving
is not required to cover anything) and makes all covering conditions involving 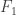 easier (because sets in the intermediate
easier (because sets in the intermediate  cover a proper subset of
cover a proper subset of  if they cover
if they cover  ). In fact, we could go further and say that
). In fact, we could go further and say that 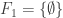 and that
and that  for some
for some 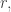 but I don’t really like that because we can play the empty-set trick only once and it destroys the symmetry. So I’m going to ban the empty set for the purposes of this argument.
but I don’t really like that because we can play the empty-set trick only once and it destroys the symmetry. So I’m going to ban the empty set for the purposes of this argument.
So now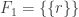 and
and 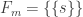 for some
for some  The next question is whether
The next question is whether  should or should not equal
should or should not equal  This is no longer a WLOG I think, because if
This is no longer a WLOG I think, because if  then it makes it easier for intermediate families to cover
then it makes it easier for intermediate families to cover  (they do automatically) but when we put in
(they do automatically) but when we put in  it means that
it means that  and
and  are (potentially) different sets, so there is more to keep track of. But a further
are (potentially) different sets, so there is more to keep track of. But a further  will either be earlier than
will either be earlier than  and not care about
and not care about 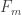 or later and not care about
or later and not care about  so my instinct is that it is better to make
so my instinct is that it is better to make 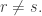 (And since this is a greedyish just-do-it, there is no real harm in imposing some minor conditions like this as we go along.)
(And since this is a greedyish just-do-it, there is no real harm in imposing some minor conditions like this as we go along.)
Since this comment is getting quite long, I’ll continue in a new one rather than risk losing the whole lot.
This comment continues from this one.
There is now a major decision to be made: which family should we choose next? Should it be one of the extreme families — without loss of generality — or should we try a kind of repeated bisection and go for a family right in the middle? Since going for a family right in the middle doesn’t actually split the collection properly in two (since the two halves will have plenty of constraints that affect both at the same time) I think going for an extreme family is more natural. So let’s see whether we can say anything WLOG-ish about
— or should we try a kind of repeated bisection and go for a family right in the middle? Since going for a family right in the middle doesn’t actually split the collection properly in two (since the two halves will have plenty of constraints that affect both at the same time) I think going for an extreme family is more natural. So let’s see whether we can say anything WLOG-ish about 
I now see that I said something false above. It is not true that the unique set in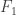 is WLOG a singleton, because there is one respect in which that makes life harder: since the
is WLOG a singleton, because there is one respect in which that makes life harder: since the  are disjoint we cannot use that singleton again. So let us stick with the decision to choose singletons but bear in mind that we did in fact lose generality (but in a minor way, I can’t help feeling).
are disjoint we cannot use that singleton again. So let us stick with the decision to choose singletons but bear in mind that we did in fact lose generality (but in a minor way, I can’t help feeling).
I also see that I said something very stupid: I was wondering whether it was better to take or
or  but of course taking
but of course taking  was forbidden by the disjointness condition.
was forbidden by the disjointness condition.
The reason I noticed the first mistake was that that observation seemed to iterate itself. That is, if we think greedily, then we’ll want to make be of the form
be of the form 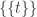 and so on, and we’ll quickly run out of singletons.
and so on, and we’ll quickly run out of singletons.
So the moral so far is that if we are greedy about making it as easy as possible for to cover
to cover  whenever
whenever 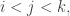 then we make the disjointness condition very powerful.
then we make the disjointness condition very powerful.
Since that is precisely the sort of intuition I was hoping to get from this exercise, I’ll stop this comment here. But the next plan is to try once again to use a greedy algorithm, this time with a new condition that will make the disjointness condition less powerful. Details in the next comment, which I will start writing immediately.
It seems that my <a href="https://gilkalai.wordpress.com/2010/09/29/polymath-3-polynomial-hirsch-conjecture/#comment-3448"previous comment went somewhat back in history.
Sorry my previous post was awful since wordpress does not understand latex directly. I try to add latex markups, I hope it is the right thing to do. The computations on examples were false
because I use something I did not establish.
Now let’s try to improve a bit what I have said.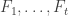 into levels: we have a sequence of sets
into levels: we have a sequence of sets  such that the intersection of S_i with {1,…,n-k} is constant on a level.
such that the intersection of S_i with {1,…,n-k} is constant on a level.
The idea is that if as big set {1,…,n-k} appears in a family,
we can decompose the sequence of families
Moreover each level is of size f(k) at most.
We can improve on that a bit to try to compute the first values of f.
Let g(n,m) the maximum size of the sequences of disjoint families satisfying (*) such that only sets of size at most m appears in the families. We have g(n,n) = f(n) and g(n,.) is incresaing.
Assume now there is a set of size n-k but no larger one in a sequence of t families. Then we can bound t by
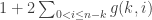
Consider now the case where we have a set of size n-1 but not of size n. .
.
We can see that the first and last levels have only two sets to share therefore we can say wlog that the first level is of size 2 and the last of size 0. By a bit of case study
I think I can prove that there is at most two levels with two families.
Therefore we have that the size of such a sequence is bounded
by 1 + 2*2 (the two levels of size two) + 2(n-1)-3 (the last level is removed as well as the two of size 2).
So if there is a set of size n-1 (but not the one of siz n),
the size of the sequence is at most 2n. Moreover, one can find
such a sequence of size 2n:
Well, now that really rules out the case of a set of size 3, but no of size 4 in a sequence built over {1,2,3,4}.
Therefore to prove f(4)=8, one has only to look at a sequence of families containing only pairs. That is computing g(4,2) and it must not be that hard.
Before starting this comment I took a look back and saw that I had missed Gil’s discussion of Well, my basic thought now is that since a purely greedy algorithm encourages one to look at
Well, my basic thought now is that since a purely greedy algorithm encourages one to look at  which is a bit silly, it might be a good idea to try to apply a greedy algorithm to the question of lower bounds for
which is a bit silly, it might be a good idea to try to apply a greedy algorithm to the question of lower bounds for 
I’ll continue with the notation I suggested in this comment.
As before, it makes sense for and
and 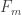 to be singletons (where by “makes sense” I mean that WLOG this is what happens). Now of course by “singleton” I mean “set of size
to be singletons (where by “makes sense” I mean that WLOG this is what happens). Now of course by “singleton” I mean “set of size  “. Actually, since this is just a start, let’s take
“. Actually, since this is just a start, let’s take  and try to get a superlinear lower bound (which does in fact exist according to an earlier post of Gil’s, according to Noam Nisan above).
and try to get a superlinear lower bound (which does in fact exist according to an earlier post of Gil’s, according to Noam Nisan above).
So now and
and 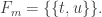 The first question is whether we should take
The first question is whether we should take  and
and 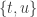 to be disjoint or to intersect in a singleton. It seems pretty clearly better to make them disjoint, so as to minimize the difficulties later.
to be disjoint or to intersect in a singleton. It seems pretty clearly better to make them disjoint, so as to minimize the difficulties later.
Now what? Again, let us go for next. Here’s an argument that I find quite convincing. Since every set system covers
next. Here’s an argument that I find quite convincing. Since every set system covers  WLOG
WLOG  is a singleton
is a singleton 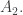 (Let’s also write
(Let’s also write 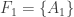 and
and 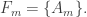 ) Now we care hugely about
) Now we care hugely about  because there are lots of intermediate
because there are lots of intermediate 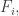 and not at all about
and not at all about  Oh wait, that’s false isn’t it, because for each
Oh wait, that’s false isn’t it, because for each  we need
we need  to cover
to cover  So it’s not even obvious that we want
So it’s not even obvious that we want  to be a singleton. Indeed, if
to be a singleton. Indeed, if 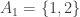 and
and 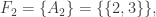 then all sets in all
then all sets in all  must either be disjoint from
must either be disjoint from  or must intersect it in
or must intersect it in  That tells us that the element 1 is banned, and banning elements is a very bad idea because you can do it at most
That tells us that the element 1 is banned, and banning elements is a very bad idea because you can do it at most  times.
times.
On the other hand, if we keep insisting that we mustn’t ban elements, that is going to be a problem as well, so there seem to be two conflicting pressures here.
For now, however, I’m going to go with not banning elements. So that tells us that, in order not to restrict the later too much, it would be a good idea if
too much, it would be a good idea if  contains at least one set that contains
contains at least one set that contains  and at least one set that contains
and at least one set that contains  But in order to do that in a “minimal” way, let us take
But in order to do that in a “minimal” way, let us take 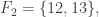 where I am now abbreviating
where I am now abbreviating 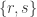 by
by  I am of course also thinking of the
I am of course also thinking of the  as graphs, so let me make that thought explicit: we want a sequence of graphs
as graphs, so let me make that thought explicit: we want a sequence of graphs  such that no two of the graphs share an edge, and such that if
such that no two of the graphs share an edge, and such that if  and
and  and
and  contain edges that meet at a vertex, then
contain edges that meet at a vertex, then  must also contain an edge that meets at that vertex.
must also contain an edge that meets at that vertex.
Ah — rereading Noam Nisan’s question I now see that the superlinear bound he was referring to was an upper bound. So it could be that obtaining a lower bound even of would be interesting.
would be interesting.
So now we have chosen the following three graphs: Let’s assume that
Let’s assume that  and
and  but write it
but write it 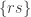 because it is harder to write
because it is harder to write 
What constraint does that place on the remaining graphs ? Since no set in
? Since no set in 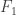 or
or  intersects any set in
intersects any set in  it is not hard for
it is not hard for  to cover
to cover  and
and 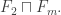 So we just have to worry about
So we just have to worry about  covering
covering  And we have made sure that that happens automatically, since
And we have made sure that that happens automatically, since  covers all possible intersections with a set in
covers all possible intersections with a set in 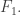 (This is another sort of greed that is clearly too greedy.) So the only constraint comes from the disjointness condition: every edge in
(This is another sort of greed that is clearly too greedy.) So the only constraint comes from the disjointness condition: every edge in  must contain a vertex outside the set
must contain a vertex outside the set  since we have used up the edges
since we have used up the edges 
Now let’s think about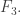 (It’s no longer clear to me that we wanted to decide
(It’s no longer clear to me that we wanted to decide 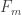 at the beginning — let’s keep an open mind about that.)
at the beginning — let’s keep an open mind about that.)
The obvious analogue of what we did when choosing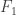 and
and  is to set
is to set 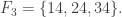 But this is starting to commit ourselves to a pattern that we don’t want to continue, since it stops at
But this is starting to commit ourselves to a pattern that we don’t want to continue, since it stops at  (But let me check whether it works. If
(But let me check whether it works. If  is the set of all pairs with maximal element
is the set of all pairs with maximal element 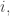 then if
then if  and an edge in
and an edge in  meets an edge in
meets an edge in 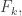 then those two edges must either be of the form
then those two edges must either be of the form 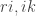 or of the form
or of the form  for some
for some 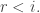 So they intersect in some
So they intersect in some  which means that their intersection is covered by the edge
which means that their intersection is covered by the edge  )
)
If we decide at some point to break the pattern, then what happens? Again, this comment is getting long so I’ll start a new one.
This is a continuation of my previous comment.
Let us experiment a bit and try That is, in order to break a pattern that we need to break sooner or later, let us miss out
That is, in order to break a pattern that we need to break sooner or later, let us miss out  from
from 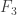 and explore the implications for future
and explore the implications for future  For convenience I am now not going to assume that we have chosen
For convenience I am now not going to assume that we have chosen  my greedy (but I hope not overgreedy) algorithm just chooses the families in the obvious order.
my greedy (but I hope not overgreedy) algorithm just chooses the families in the obvious order.
What condition does this impose on future ? Any intersection with
? Any intersection with 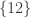 will be
will be 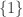 or
or 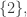 so it will be covered by
so it will be covered by  and
and 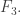 So that’s fine. But the fact that we have missed out
So that’s fine. But the fact that we have missed out  from
from 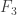 means that we can’t afford any edge that contains the vertex 3, since that will intersect an edge in
means that we can’t afford any edge that contains the vertex 3, since that will intersect an edge in  in the vertex 3, and will then not be covered by
in the vertex 3, and will then not be covered by 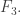 That means that the best our lower bound for
That means that the best our lower bound for  can be is
can be is 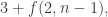 and it probably can’t even be that. So this is bad news if we are going for a superlinear lower bound.
and it probably can’t even be that. So this is bad news if we are going for a superlinear lower bound.
Let’s instead try which is genuinely different example. Can any edge in
which is genuinely different example. Can any edge in  contain 1? If it does, then … OK, it obviously can’t, so once again we’re in trouble.
contain 1? If it does, then … OK, it obviously can’t, so once again we’re in trouble.
If we don’t ban vertices, then what are our options? Let’s try to understand the general circumstance under which a vertex gets banned. Suppose that a vertex is used in some
is used in some  and not in
and not in  , where
, where 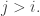 Then that vertex cannot be used in
Then that vertex cannot be used in  if
if  for the simple reason that then
for the simple reason that then  and
and  is not covered by
is not covered by 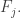
So let be the set of all vertices used by
be the set of all vertices used by  (or equivalently the union of the sets in
(or equivalently the union of the sets in  ). We have just seen that if
). We have just seen that if  and
and 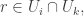 then
then 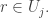 So a preliminary question we should ask is whether we can find a nice long sequence of sets
So a preliminary question we should ask is whether we can find a nice long sequence of sets  satisfying this condition.
satisfying this condition.
The answer is potentially yes, since there is no reason to suppose that the sets are distinct. But let us first see what happens if they are distinct. I think there should be a linear upper bound on their number.
are distinct. But let us first see what happens if they are distinct. I think there should be a linear upper bound on their number.
Let be a sequence of distinct sets with this property. Let us assume that the ground set is ordered in such a way that each new element that is added is as small as possible.
be a sequence of distinct sets with this property. Let us assume that the ground set is ordered in such a way that each new element that is added is as small as possible.
Hmm, I don’t think that helps. But how about this. For each element of the ground set, the condition tells us that the set of
of the ground set, the condition tells us that the set of  such that
such that 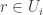 is an interval
is an interval  So we ought to be able to rephrase things using those intervals. The question becomes this: let
So we ought to be able to rephrase things using those intervals. The question becomes this: let 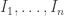 be a collection of subintervals of
be a collection of subintervals of ![[m].](https://s0.wp.com/latex.php?latex=%5Bm%5D.&bg=ffffff&fg=333333&s=0&c=20201002) For each
For each ![i\in[m]](https://s0.wp.com/latex.php?latex=i%5Cin%5Bm%5D&bg=ffffff&fg=333333&s=0&c=20201002) let
let  How big can
How big can ![[m]](https://s0.wp.com/latex.php?latex=%5Bm%5D&bg=ffffff&fg=333333&s=0&c=20201002) be if all the sets
be if all the sets  are distinct?
are distinct?
That’s much better, since it tells us that between each and
and 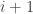 some interval
some interval  must either just have started or just have finished. So we get a bound of
must either just have started or just have finished. So we get a bound of  (Perhaps it’s actually
(Perhaps it’s actually  but I can’t face thinking about that.)
but I can’t face thinking about that.)
This suggests to me a construction, but once again this comment is getting a bit long so I’ll start a new one.
I’ve just been reading properly some of the earlier comments and noticed that the argument I gave in the third-to-last paragraph is essentially the argument that Noam and Terry came up with to bound the function
I want to try out a construction suggested by the thoughts at the end of this comment, though it may come to nothing.
The basic idea is this. Let’s define our sets as follows. We begin with a collection of increasing intervals
as follows. We begin with a collection of increasing intervals ![[1,i]](https://s0.wp.com/latex.php?latex=%5B1%2Ci%5D&bg=ffffff&fg=333333&s=0&c=20201002) and then when we reach
and then when we reach ![[1,n]](https://s0.wp.com/latex.php?latex=%5B1%2Cn%5D&bg=ffffff&fg=333333&s=0&c=20201002) we continue with
we continue with ![[2,n],[3,n],\dots,\{n\}.](https://s0.wp.com/latex.php?latex=%5B2%2Cn%5D%2C%5B3%2Cn%5D%2C%5Cdots%2C%5C%7Bn%5C%7D.&bg=ffffff&fg=333333&s=0&c=20201002) These sets have the property that if
These sets have the property that if  and
and 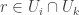 then
then 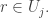
Now I want to define for each a graph
a graph  with vertex set
with vertex set  (except that strictly speaking
(except that strictly speaking  has vertex set
has vertex set ![[n]](https://s0.wp.com/latex.php?latex=%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) and the vertices outside
and the vertices outside  are isolated). I want these
are isolated). I want these  to have the following two properties. First,
to have the following two properties. First,  is a vertex cover of
is a vertex cover of  that is, all the vertices in
that is, all the vertices in  are used. Secondly, the
are used. Secondly, the  are edge-disjoint. Suppose we have these two conditions. Then if
are edge-disjoint. Suppose we have these two conditions. Then if 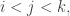 then
then  consists of vertices that belong to
consists of vertices that belong to  and hence to
and hence to  and they are then covered by
and they are then covered by 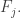
The most economical vertex covers will be perfect matchings, though that causes a slight problem if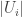 is odd. But maybe we can cope with the extra vertices somehow.
is odd. But maybe we can cope with the extra vertices somehow.
I think that so far these conditions may be too restrictive. Indeed, for a trivial reason we can’t cover so we should have started with
so we should have started with 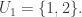 But if we do that, then
But if we do that, then 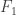 is forced to be
is forced to be  which means that
which means that  is forced to contain
is forced to contain  and all sorts of other decisions are pretty forced as well.
and all sorts of other decisions are pretty forced as well.
So the extra idea that might conceivably help (though it is unlikely) is to start with for some small
for some small  That might give us enough flexibility to make the choices we need to make and obtain a lower bound of
That might give us enough flexibility to make the choices we need to make and obtain a lower bound of  However, I don’t rule out some simple counting argument showing that we use up the edges in some
However, I don’t rule out some simple counting argument showing that we use up the edges in some  too quickly.
too quickly.
Looking at n=4, here’s a nontrivial (better than n-1) sequence for f(2,n): {12}, {23,14}, {13,24}, {34}.
I think that this generalizes for general n: at the beginning put a recursive sequence on the first n/2 elements; at the end put a recursive sequence on the last n/2 elements; now at the middle we’ll put n/2 set systems where each of these has exactly n/2 pairs, where each pair has one element from the first n/2 elements and another from the last n/2 elements. (There are indeed n/2 such disjoint matchings in the bipartite graph with n/2 vertices on each side.) The point is that the support on all set systems in the middle is complete, so they trivially contain any intersection of two pairs.
If this works the we get the recursion f(2,n) \ge 2f(2,n/2) + n/2, which solves at Omega(n log n).
Noam, I don’t think this construction works. The problem is that the recursive sequences at either end obey additional constraints coming from the stuff in the middle. For instance, because the support on all the middle stuff is complete, the supports on the first recursive sequence have to be monotone increasing, and the supports on the second recursive sequence have to be monotone decreasing. (One can already see this if one tries the n=8 version of the construction.)
I discovered this by reading [AHRR] and discovering that they had the bound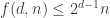 , or in this case
, or in this case 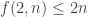 . I’ll put their argument on the wiki.
. I’ll put their argument on the wiki.
Is it known if 2n is the right bound here?
The best construction I have been able to do is this:
Start by dividing 1….n into n/2 disjoint pairs {1,2}{3,4},…,{i,i+1},…
next insert the following families between {a,b} and {c,d}:
{{a,c},{b,d}} , {{a,d},{b,c}}
This gives a family of size 1+3(n/2-1) and I have not been able to improve it for, very, small n
{a,b} and {c,d} should be consecutive pairs in the first sequence.
Ahh, I see. Indeed broken. Thanks.
That looks convincing (this is a reply to Noam Nisan’s comment which should appear just before this one but may not if WordPress continues to act strangely). It interests me to see how it fits with what I was writing about, so let me briefly comment on that. First of all, let’s think about the sequence of s. I’ll write what the sequence is in the case
s. I’ll write what the sequence is in the case 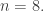 It is 12,1234,34,12345678,56,5678,78. If we condense the pairs to singletons it looks like this: 1, 12, 2, 1234, 3, 34, 4. We can produce this sequence by drawing a binary tree in a natural way and then visiting its vertices from left to right. We label the leaves from 1 to
It is 12,1234,34,12345678,56,5678,78. If we condense the pairs to singletons it looks like this: 1, 12, 2, 1234, 3, 34, 4. We can produce this sequence by drawing a binary tree in a natural way and then visiting its vertices from left to right. We label the leaves from 1 to  and we label vertices that appear higher up by the set of all the leaves below them.
and we label vertices that appear higher up by the set of all the leaves below them.
The gain from to
to 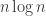 comes from the fact that these sets appear with a certain multiplicity: the multiplicity of a set
comes from the fact that these sets appear with a certain multiplicity: the multiplicity of a set  in the sequence is proportional to the size of that set.
in the sequence is proportional to the size of that set.
By the way, is the following argument correct? Let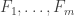 be a general system of families satisfying the condition we want. For each
be a general system of families satisfying the condition we want. For each  let
let  be the union of all the sets in
be the union of all the sets in  Then if
Then if  and
and 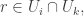 it follows that
it follows that 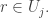 (Otherwise just pick a set in
(Otherwise just pick a set in  and a set in
and a set in  that both contain
that both contain  and their intersection won’t be contained in any set in
and their intersection won’t be contained in any set in 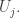 ) Therefore, by the observation I made in this comment (a fact that I’m sure others were well aware of long before my comment) there are at most
) Therefore, by the observation I made in this comment (a fact that I’m sure others were well aware of long before my comment) there are at most  distinct sets
distinct sets 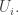 It follows that if we have a superpolynomial lower bound, then we must have a superpolynomial lower bound with the same
It follows that if we have a superpolynomial lower bound, then we must have a superpolynomial lower bound with the same  for every family. So an equivalent formulation of the problem would be to find a polynomial upper bound (or superpolynomial lower bound) for the number of
for every family. So an equivalent formulation of the problem would be to find a polynomial upper bound (or superpolynomial lower bound) for the number of  with the additional constraint that the union of every
with the additional constraint that the union of every  is the whole of
is the whole of ![[n].](https://s0.wp.com/latex.php?latex=%5Bn%5D.&bg=ffffff&fg=333333&s=0&c=20201002)
If that is correct, then I think it helps us to think about the problem, because it raises the following question: if the unions of all the set systems are the same, then what is going to give us a linear ordering? In Noam’s example, if you look at the popular there is no ordering — any triple of families that share a union has the desired relationship. A closely related question is one I’ve asked already: what is the upper bound for the number of families if you ask for
there is no ordering — any triple of families that share a union has the desired relationship. A closely related question is one I’ve asked already: what is the upper bound for the number of families if you ask for  to cover
to cover  for every
for every 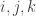 ?
?
The case that the support of every family is [n], seems indeed enough and concentrating on it was also suggested by Yuri ( https://gilkalai.wordpress.com/2010/09/29/polymath-3-polynomial-hirsch-conjecture/#comment-3438 ). This restriction doesn’t seem so convenient for proving upper bounds, since the property disappears under “restrictions”. For example running the EHRR argument would reduce n by 1 without shortening the sequence at all but loosing the property.
Ah, thanks for pointing that out — I’m coming late to this discussion and have not been following the earlier discussion posts. For now I myself am trying to think about lower bounds (either to find one or to understand better why the conjecture might be true) so I quite like the support restriction because it somehow stops one from trying to make the “wrong” use of the ground set. It also suggests the following question that directly generalizes what you were doing in your example. Suppose we have three disjoint sets X,Y,Z of size n. How many families can we find with the following properties?
can we find with the following properties?
(i) For every and every
and every  the intersections
the intersections 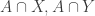 and
and 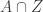 all have size 1.
all have size 1.
(ii) Each is a partition of
is a partition of 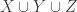 into sets of size 3.
into sets of size 3.
(iii) For every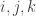 and every
and every  and
and 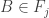 there exists
there exists 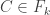 such that
such that 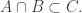
(iv) No set belongs to more than one of the
If we do it for X and Y and sets of size 2 then the answer is easily seen to be n (and condition (iii) holds automatically), but for sets of size 3 it doesn’t seem so obvious, since each element of X can be in triples, but if we exploit that then we have to worry about condition (iii).
triples, but if we exploit that then we have to worry about condition (iii).
I haven’t thought about this question at all so it may have a simple answer. If it does, then I would follow it up by modifying condition (iii) so that it reads “For every and every
and every  and
and 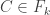 there exists
there exists 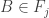 such that
such that  “
“
I now see that Yuri’s comment was not from an earlier discussion thread — I just missed it because I was trying to think more about general constructions than constructions for small
Hi everyone,
Here’s another thought on handling the d=2 case (and perhaps the more general case):
Suppose we add the following condition on our collection of set families $F_i$:
(**) Each $(d-1)$-element subset of $[n]$ is active on at most two of the families $F_i$.
Here, I mean that a set $S$ is active on $F_i$ if there is a $d$-set $T \in F_i$ for which $T \supset S$.
This condition must be satisfied for polytopes — working in the dual picture, any codimension 1 face of a simplicial polytope is contained in exactly two facets.
So how does this help us in the case that $d=2$? Suppose $F_1,\ldots,F_t$ is a family of disjoint 2-sets on ground set $[n]$ that satisfies Gil’s property (*) and the above property (**)
Let’s count the number of pairs $(j,k) \in [n] \times [t]$ for which $j$ is active on $F_k$. Each $j \in [n]$ is active on at most two of the families $F_i$, and hence the number of such pairs is at most $2n$. On the other hand, since each family $F_k$ is nonempty, there are at least two vertices $j \in [n]$ that are active on each family $F_k$. Thus the number of such ordered pairs is at least $2t$.
Thus $t \leq n$, giving an upper bound of $f(n,2) \leq n-1$ when we assume the additional condition (**).
This technique doesn’t seem to generalize to higher dimensions without some sort of analysis of how the sizes of the set families $F_i$ grow as $i$ ranges from $1$ to $t$.
I think I can show f(4) is less than 9. We have it
must be less than 10 previously.
Assume we have 9 or more elements then there are 8 types of
sets in terms of which of the the first three elements are
in the set. We must have a repetition of the same type in
sets in two different families.
Then every set must contain an element
that contains the 3 elements of the repetition.
Now if the repetition is not null there can be
at most 8 elements that contain the repetition
but we have 7 families besides A and B and so there is a contradiction.
But we can improve this since we have two instances of the repetition
in the first two elements so we have at most 6 unused elements.
Now we can repeat this argument for each set of
four elements. so we have at most 5 families containing the
null set and each single element. And we have adding
one element not in a set in a family and having the resulting
augmented set outside the family is forbidden.
so outside of the 5 sets that contain
the singleton elements and the null set there are no
two element sets, no single element sets
and no null set. but that leaves 5 elements for 4
sets.
This means that each family must contain one of the
sets with more than two elements. We divide the proof into
two cases
In the first case one family must
contains the set with four elements. Then another family must consist of a single set with three elements. Then since their intersection will have three elements
every family besides these two must have a set with three elements but there are not
enough sets with three elements to go around.
sets which gives a contradiction.
The second case
is when the four element set is not in one of these four sets. Then these sets must consist of four families each containing one of the three element sets. But then the families containing 123 and 124 will contain sets whose intersection is 12 but the family containing 134 will not contain a set which contains the elements 1 and 2 so in this case we have a contradiction.
So in both cases we have a contradiction and So f(4) cannot be more than 9. However since f(4) must
be 8 or 9 from previous comments in fact it must be 8.
Kristal, I am having trouble following the argument (I think part of the problem is that not enough of the objects in the argument are given names, and the two objects that are given names – A and B – are not defined). Could you put it on the wiki in more detail perhaps?
I have rewritten it and put it on the wiki.
Thanks Kristal! But I’m still having trouble with the first part of the argument. It seems you are classifying subsets of [4]={1,2,3,4} into eight classes, depending on how these sets intersect {1,2,3}. You then use the pigeonhole principle to find two families A, B that contain sets (let’s call them X and Y) which intersect {1,2,3} in the same way, e.g. {1,2} and {1,2,4}. What I don’t see then is why the other seven families also have to contain a set that intersects {1,2,3} in this way. The convexity condition tells us that every family between A and B will contain a set that contains the intersection of X and Y (in this case, {1,2}), but this doesn’t seem to be the same as what you are saying.
I went back and looked at my attempt at a proof and the difficulty you mention cannot be overcome. So I went and deleted the material I posted from the wiki. I am looking at a different idea to try and find out the value of f(4).
Let me try again to proof of an upper bound: f(2,n)=O(n log n).
Fix a sequence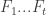 . Let us denote by
. Let us denote by  the support of
the support of  , by
, by  the support of the i’th prefix, and by
the support of the i’th prefix, and by 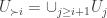 the support of the i’th suffix. The condition on the sequence of F’s implies that
the support of the i’th suffix. The condition on the sequence of F’s implies that  for all i. Intuitively, a small Ui will allow us to get a good upper bound by induction since the prefix and the suffix are on almost disjoint supports. On the other hand, a large Ui implies a large Fi (since the F’s contain pairs), and if many U’s are large then we exhaust the (n choose 2) pairs quickly.
for all i. Intuitively, a small Ui will allow us to get a good upper bound by induction since the prefix and the suffix are on almost disjoint supports. On the other hand, a large Ui implies a large Fi (since the F’s contain pairs), and if many U’s are large then we exhaust the (n choose 2) pairs quickly.
More formally, let us prove by induction . We now claim that for some
. We now claim that for some  we have that
we have that  . Otherwise these 10nlogn Fi’s will each hold more than n/(10log n) pairs, exceeding the total number of possible pairs. Let us denote
. Otherwise these 10nlogn Fi’s will each hold more than n/(10log n) pairs, exceeding the total number of possible pairs. Let us denote 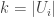 ,
, 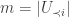 and so we have $|latex U_{ \succ i}| \le n+k-m$, with $k \le n/(5logn)$.
and so we have $|latex U_{ \succ i}| \le n+k-m$, with $k \le n/(5logn)$.
Now we observe that m and n+k-m are both about half of n, formally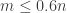 and
and  . This is implied by the induction hypothesis since
. This is implied by the induction hypothesis since 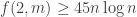 and
and 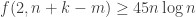 . We now get the recursion
. We now get the recursion  of which the RHS can be bounded using the induction hypothesis by
of which the RHS can be bounded using the induction hypothesis by  which is less than the required 100nlogn.
which is less than the required 100nlogn.
[GK: Noam, I fixed the latex by copy and paste, I dont understand why it did not parse.]
Looks good to me; I’ve put it on the wiki.
Using the wordpress comment mechanism is pretty annoying, as I can’t edit my remarks, nor do I even get to see a preview of my comment, not to mention the bugs (I think that the greater-than and less-than symbols confuse it due to it looking like an html tag). Maybe a better platform for polymath would be something like stack overflow? http://cstheory.stackexchange.com/questions/1814/a-combinatorial-version-for-the-polynomial-hirsch-conjecture
[GK: Dear Noam, I agree that the graphic, ability to preview and edit, and easier latex, will make a platform like stackoverflow more comfortable. I do not see how we can change things for this project]
Just to comment that it’s true that the symbols < and > are to be treated with extreme caution. I don’t use them: instead I type “ampersand lt/gt semicolon” and then it works. Of course, that’s quite annoying too …
The trick is to set up your own wordpress blog, and post/edit your comment there (you can even set them as private or draft) and then copy/paste here when you’re done editing.
What one can do is put any lengthy arguments on the wiki at
http://michaelnielsen.org/polymath1/index.php?title=The_polynomial_Hirsch_conjecture#f.28n.29_for_small_n
and just put a link to it and maybe a brief summary in the blog.
First sorry for the wordpress problems.
It looks right now that we try several avenues to improve the upper bounds or the lower bounds. When it comes to upper bounds even if we come up with new arguments which give weaker results than the best known results, then this can still serve us later. (I suppose this is true for lower bounds as well.) I find it hard to digest everything everybody wrote, but I will try to write a post soon with summary of what is known on upper bounds and reccurence relations for f(d,n). (Essentially everything is in the EHRR’s paper and is quite simple.)
From the elementary proof: “If you restrict your attention to sets in these families containing an element m and delete m from all of them, you get another example of such families of sets, possibly with smaller value of t. (Those families which do not include any set containing m will vanish.)”
I’m sure I’m being stupid, but I’ve just realized I don’t understand this argument. The reason I don’t understand it is that I don’t see why removing m from all the sets can’t identify families that don’t vanish, or destroy the disjointness condition. For example, suppose we have just three families {1,2,3}, {12,23,13} and {123}. If we remove 3 from all sets then we get {1,2,emptyset}, {1,2,12} and {12}, which violates the disjointness condition. And if we have the three families {1,2}, {12}, {13,23}, then removing 3 from all sets identifies the third family with the first (which is just a stronger form of their not being disjoint.
I can tell that what I’m writing is nonsense but some mental block is stopping me from seeing why it is nonsense.
Sorry — the second example wasn’t a good one because not all the sets in the first two families contained the element 3. Here’s another attempt. The families could be {13,2}, {123}, {1,23} and now removing 3 from all sets identifies the first and third families.
I think that the idea is to also completely delete sets that do NOT contain m. Thus {13,2}, {123}, {1,23} would become (after restricting on 3) {1}, {12}, {2}
Thanks — that makes good sense.
I’m trying to think what an extremal collection of families might look like if the proof of the upper bound was actually sharp. It would be telling us that to form an extremal family for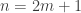 we would need to form an extremal family inside
we would need to form an extremal family inside ![[m]](https://s0.wp.com/latex.php?latex=%5Bm%5D&bg=ffffff&fg=333333&s=0&c=20201002) and another one inside
and another one inside ![[m+2,n],](https://s0.wp.com/latex.php?latex=%5Bm%2B2%2Cn%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002) and between the two one would take an extremal family in
and between the two one would take an extremal family in ![[n]\setminus\{m+1\}](https://s0.wp.com/latex.php?latex=%5Bn%5D%5Csetminus%5C%7Bm%2B1%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002) and add
and add 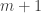 to each set in that family.
to each set in that family.
Can we say anything further about the supports of the various families? (Apologies once again if, as seems likely, I am repeating arguments that have already been made.) Well, if the middle family is extremal, then there must once again be a partition of the ground set into two such that the first few families occupy one part and the last few the other. So can we say anything about how this partition relates to the first partition? I think we can. Let’s call the two subsets of![[n]\setminus\{m+1\}](https://s0.wp.com/latex.php?latex=%5Bn%5D%5Csetminus%5C%7Bm%2B1%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002)
 and
and 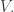 If
If  contains any element bigger than
contains any element bigger than  then
then  must also contain that element, which is a contradiction.
must also contain that element, which is a contradiction.
So now, if I’m not much mistaken, we know that the first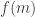 sets live inside
sets live inside ![[m]](https://s0.wp.com/latex.php?latex=%5Bm%5D&bg=ffffff&fg=333333&s=0&c=20201002) and the last
and the last 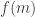 sets live inside
sets live inside ![[m+2,n].](https://s0.wp.com/latex.php?latex=%5Bm%2B2%2Cn%5D.&bg=ffffff&fg=333333&s=0&c=20201002) We also know that something similar holds for the family in between, except that all sets there include the middle element
We also know that something similar holds for the family in between, except that all sets there include the middle element 
I feel as though we may be heading towards a contradiction here. Suppose that the first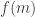 sets form an extremal family inside
sets form an extremal family inside ![[m]](https://s0.wp.com/latex.php?latex=%5Bm%5D&bg=ffffff&fg=333333&s=0&c=20201002) and the next
and the next 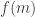 (or possibly
(or possibly 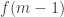 — there are irritating parity considerations here) also form an extremal family inside
— there are irritating parity considerations here) also form an extremal family inside ![[m]](https://s0.wp.com/latex.php?latex=%5Bm%5D&bg=ffffff&fg=333333&s=0&c=20201002) except that
except that 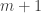 is tacked on to all the sets.
is tacked on to all the sets.
The extremality of these two bunches of families ought now to force us to find two partitions of![[m]](https://s0.wp.com/latex.php?latex=%5Bm%5D&bg=ffffff&fg=333333&s=0&c=20201002) into roughly equal subsets. Let’s call these two pairs of sets
into roughly equal subsets. Let’s call these two pairs of sets  and
and 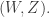 So the first
So the first  of the first lot of families live in
of the first lot of families live in  the last
the last  live in
live in 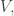 the first
the first  of the second lot of families in
of the second lot of families in  and the last
and the last  in
in 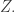 We now know that any element of
We now know that any element of  must be in
must be in  as must any element of
as must any element of 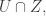 a contradiction.
a contradiction.
In fact, we can put that more concisely. Suppose the first sets have union
sets have union ![[m/2]](https://s0.wp.com/latex.php?latex=%5Bm%2F2%5D&bg=ffffff&fg=333333&s=0&c=20201002) and the last
and the last  of the first
of the first 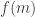 sets have union roughly
sets have union roughly ![[m/2,m].](https://s0.wp.com/latex.php?latex=%5Bm%2F2%2Cm%5D.&bg=ffffff&fg=333333&s=0&c=20201002) Then later sets seem to be forced to avoid
Then later sets seem to be forced to avoid ![[m/2]](https://s0.wp.com/latex.php?latex=%5Bm%2F2%5D&bg=ffffff&fg=333333&s=0&c=20201002) altogether, which makes the maximum size of the first intermediate collection of families much smaller. This is starting to remind me of a proposed argument of Terry’s that didn’t work, so let me look back at that. Hmm, I’m not sure it’s quite the same.
altogether, which makes the maximum size of the first intermediate collection of families much smaller. This is starting to remind me of a proposed argument of Terry’s that didn’t work, so let me look back at that. Hmm, I’m not sure it’s quite the same.
Now I’m definitely not claiming to have a proof of anything, since as soon as we allow the example not to be extremal it becomes much harder to say anything about it. But I find these considerations suggestive: it seems that one ought to be able to improve considerably on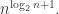
If one were going to try to turn the above argument into a proof, I think one would have to show that if you have a large sequence of families then there must be a bipartition of the ground set such that the first few families are concentrated in the first set of the bipartition and the last few in the last set. Equivalently, the idea would be to show that the sets in the first few families were disjoint from the sets in the last few. It might be that one couldn’t prove this exactly, but could show that it was almost true after a small restriction, or something along those slightly vaguer lines.
Just to add an obvious thought to that last paragraph: if we have a large but not maximal family, then it could be that the supports of all the families are equal to the whole of the ground set, as we have already seen. So some kind of restriction would be essential to get the disjointness (if it is possible at all).
As I have already mentioned, it seems to me that for the purposes of an upper bound it would be extremely useful if one could prove that for any sequence of families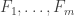 over a certain length, the first few
over a certain length, the first few  would have to be disjoint from the last few. However, that is not the right statement to try to prove because at the cost of dividing by
would have to be disjoint from the last few. However, that is not the right statement to try to prove because at the cost of dividing by  we can insist that the support of every single family is the whole ground set.
we can insist that the support of every single family is the whole ground set.
But as Noam points out, this property is not preserved by restrictions, so it would be interesting to know whether it is possible to formulate a reasonable conjecture that would still be useful.
As a first step in that direction, I want to consider a rather extreme situation. What can we say about a family if the supports of all its restrictions are full? Let us use the term –restriction of a family
–restriction of a family  for the collection of all sets
for the collection of all sets 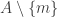 such that
such that  and
and 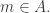 If the
If the  -restriction of
-restriction of  has support equal to
has support equal to ![[n]\setminus\{m\},](https://s0.wp.com/latex.php?latex=%5Bn%5D%5Csetminus%5C%7Bm%5C%7D%2C&bg=ffffff&fg=333333&s=0&c=20201002) then for every
then for every ![r\in[n], r\ne m](https://s0.wp.com/latex.php?latex=r%5Cin%5Bn%5D%2C+r%5Cne+m&bg=ffffff&fg=333333&s=0&c=20201002) there exists a set
there exists a set  such that
such that 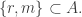 So this condition is saying that every set of size 2 is covered by a set in
So this condition is saying that every set of size 2 is covered by a set in 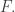 So whereas the original support condition says that every 1-set is covered, now we are talking about 2-sets.
So whereas the original support condition says that every 1-set is covered, now we are talking about 2-sets.
This leads immediately to a question that I find quite interesting. It is quite easy to describe how the sequence of supports of the can behave, and this leads to the argument that there can be at most
can behave, and this leads to the argument that there can be at most 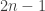 different supports. But what about the “2-supports”? That is, if we define
different supports. But what about the “2-supports”? That is, if we define  to be the set of all pairs covered by
to be the set of all pairs covered by 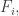 then what can we say about the sequence
then what can we say about the sequence 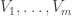 ? In particular, how long can it be? I would like to guess that it can have length at most
? In particular, how long can it be? I would like to guess that it can have length at most 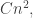 but that really is a complete guess based on not having thought about the problem.
but that really is a complete guess based on not having thought about the problem.
If it turns out to be correct, then the “we might as well assume that all the 2-supports are the same” argument is that much weaker, which suggests that there is more chance of saying something interesting by considering a restriction.
I’ve just realized that there is a fairly simple answer to part of the question, which is that the sets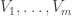 must themselves form a sequence of families of the given kind. Why? Well, if
must themselves form a sequence of families of the given kind. Why? Well, if  and there exist
and there exist 
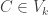 such that
such that 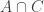 is not contained in any set in
is not contained in any set in  then pick sets
then pick sets  and
and  such that
such that 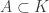 and
and  Then
Then  contains
contains 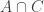 and is therefore not contained in any
and is therefore not contained in any 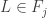 (or else that
(or else that  would contain a pair
would contain a pair  that contains
that contains 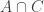 ).
).
So it seems that taking the -lower shadow of a system of families with the desired property gives you another system, though without the disjointness condition.
-lower shadow of a system of families with the desired property gives you another system, though without the disjointness condition.
Thus, another question of some minor interest might be this. If you want a system of (distinct but not necessarily disjoint) families of sets of size 2 such that for any
of sets of size 2 such that for any  and any
and any 
 there exists
there exists 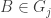 such that
such that 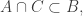 then how big can
then how big can  be? The answer to the corresponding question for sets of size 1 is
be? The answer to the corresponding question for sets of size 1 is 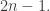
The answer to that last question is easy (and possibly not very interesting). There is an obvious upper bound of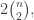 since the collection of
since the collection of  that contain any given 2-set must be an interval. But we can also achieve this upper bound by simply adding the 2-sets one at a time and removing them again, just as one does for 1-sets. Anyhow, this confirms my earlier guess that the length would be quadratic.
that contain any given 2-set must be an interval. But we can also achieve this upper bound by simply adding the 2-sets one at a time and removing them again, just as one does for 1-sets. Anyhow, this confirms my earlier guess that the length would be quadratic.
A further small remark: by taking into account both the 1-shadows and the 2-shadows we can deduce a bit more about how the 2-sets are added. First you need the set 12, then the two sets 13, 23 (not necessarily in that order), then the sets 14,24,34, and so on until you’ve added all sets. Then you have to remove all the 2-sets containing 1, then all the 2-sets containing 2 (but not 1) and so on.
Regarding f(2,n); the upper bound is actually 2n-1 rather than 2n, because there is at least one element in the first support block (see wiki for notation) that is not duplicated in any other block (indeed every element of
(see wiki for notation) that is not duplicated in any other block (indeed every element of  is of this type).
is of this type).
Conversely, I can attain this bound if I allow the “cheat” of using two-element multi-sets {a,a} in addition to ordinary two-element sets {a,b}. The argument on the wiki extends perfectly well to multi-sets. If one then sets
for i=1,…,2n-1, one obtains a family of sets obeying (*).
In principle it should be easy to tinker with this example to remove the multisets {a,a} (which are only a small minority of the sets here) and get true sets, by paying a small factor in t (maybe a log factor), but this seems to be surprisingly tricky.
Now, things get more interesting at the d=3 level. The elementary argument on the wiki gives , and this bound works for multisets also. However, the best example I can come up with is
, and this bound works for multisets also. However, the best example I can come up with is
for i=1,…,3n-2, so there is a gap between 3n-O(1) and 4n-O(1). This may seem trifling, but it may get to the heart of the issue because we really need to know whether the dependence on d is exponential (as the elementary argument suggests) or polynomial, and this is the first test case for this.
p.s. If one can fix the multiset issue, then the construction above should give a lower bound of about dn for f(d,n), which matches the quadratic lower bound on [AHRR].
I think comment #1 by Nicolai says there is a lower bound of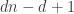 if you allow multisets…
if you allow multisets…
Also, I don’t quite understand the argument on the wiki. I follow till the point that and
and 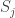 are disjoint if
are disjoint if  , but I don’t see that this gives the conclusion that
, but I don’t see that this gives the conclusion that 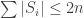 . If the hypothesis I just mentioned is the only one used for the conclusion, then why couldn’t one have $S_1 = S_2 = S_3 = [n]$? I suppose I should look at [EHRR]’s Theorem 4 (which also gets
. If the hypothesis I just mentioned is the only one used for the conclusion, then why couldn’t one have $S_1 = S_2 = S_3 = [n]$? I suppose I should look at [EHRR]’s Theorem 4 (which also gets  ; from a quick glance it looks slightly different from what’s on the wiki, having a disjointness condition with
; from a quick glance it looks slightly different from what’s on the wiki, having a disjointness condition with 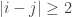 …
…
Oops, the 3 was supposed to be a 2 in that argument, sorry! I edited the wiki argument accordingly.
Actually, with this change, I still don’t quite see the argument which is on the wiki; i.e., I don’t see why the convexity condition implies that and
and 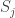 need to be disjoint if
need to be disjoint if  and
and  differ by 2.
differ by 2.
Hmm, a reply I wrote didn’t seem to show up. Maybe it’s in moderation? The short version of it was that Nicolai’s comment 1 says there is a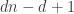 lower bound if you allow multisets.
lower bound if you allow multisets.
Ah, yes, I seem to have once again repeated a previous comment. Well, at least we’re all on the same page now…
It looks natural to include a version of f when the problem is restricted to sets of size at most d, rather than exactly d. In that case this construction, by collapsing the multisets to sets, and the one I gave earlier https://gilkalai.wordpress.com/2010/09/29/polymath-3-polynomial-hirsch-conjecture/#comment-3466 both show that the d=2 case can reach 2n-1.
I’m fairly sure that the example I gave here https://gilkalai.wordpress.com/2010/09/29/polymath-3-polynomial-hirsch-conjecture/#comment-3485 is optimal for n up to 6. I tried quite a few things by hand and did a partial computer check without coming up with anything better. So if it really is possible to remove the multisets the reduction in size has to be quite large for small n.
But I wouldn’t be surprised if there is a difference between having sets of size exactly d and sets of size at most d.
I like the idea of concentrating on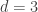 (either in the sets case or the multisets case). As we have seen, one learns quite a lot by looking at the supports of the various families. I think one way of trying to get a handle on the
(either in the sets case or the multisets case). As we have seen, one learns quite a lot by looking at the supports of the various families. I think one way of trying to get a handle on the 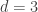 case is to look at what I have been thinking of as the 2-support: that is, the set of all 2-sets (or multisets) that are subsets of sets in the family.
case is to look at what I have been thinking of as the 2-support: that is, the set of all 2-sets (or multisets) that are subsets of sets in the family.
To make that clear, if is a family of sets of size 3, let
is a family of sets of size 3, let  be the union of all the sets in
be the union of all the sets in  (the 1-support) and let
(the 1-support) and let  be the set of all (multi)sets
be the set of all (multi)sets  of size 2 such that there is a set
of size 2 such that there is a set  with
with 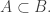 We know a great deal about how the sequence
We know a great deal about how the sequence  can look. But what can we say about the sequence
can look. But what can we say about the sequence 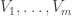 ? There are two constraints that I can see. One is that they satisfy condition (*), and the other is that their supports also satisfy condition (*). I feel as though I’d like to characterize all sequences
? There are two constraints that I can see. One is that they satisfy condition (*), and the other is that their supports also satisfy condition (*). I feel as though I’d like to characterize all sequences 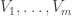 that have these two properties, and then try to think which ones lift to sequences of disjoint families
that have these two properties, and then try to think which ones lift to sequences of disjoint families 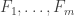 that also have property (*).
that also have property (*).
A while ago, Gowers suggested to look at a harsher condition requiring that for all ,
, 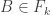 there exists
there exists  such that
such that  not only for i < j < k but for all i,j,k.
not only for i < j < k but for all i,j,k.
Here’s an even more extreme version of this approach where we just look at the union of the F’s:
Let’s say that a family F of sets has index t if for every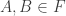 (
( ) there exist at least t different
) there exist at least t different 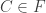 such that
such that  . How large an index can a family of subsets of [n] be?
. How large an index can a family of subsets of [n] be?
If we have a family with index t then we get a t/n lower bound for our original problem, by splitting the family at random into a t/n of families Fi (since for a specific intersection and a specific i the probability that there is no covering C in Fi is exp(-n) and then we can take the union bound on all intersections and all i’s.)
This version may be not be so far from the original version: If we look at the “average index” rather than the index (How many sets in expectation cover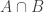 for A and B chosen at random from F.). Take a sequence of Fi’s of length t for our original problem; wlog you may assume that all Fi’s have approximately the same size; and then take their union. For an average A and B from the union, there are theta(t) many levels between them in the original sequence so we get average index of at least theta(t).
for A and B chosen at random from F.). Take a sequence of Fi’s of length t for our original problem; wlog you may assume that all Fi’s have approximately the same size; and then take their union. For an average A and B from the union, there are theta(t) many levels between them in the original sequence so we get average index of at least theta(t).
Here’s a quick calculation. Suppose we could find a Steiner system with parameters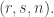 That is, F is a collection of
That is, F is a collection of  -sets such that each
-sets such that each  -set is a subset of exactly one set in F. Then
-set is a subset of exactly one set in F. Then  would be the number of
would be the number of  -sets containing each
-sets containing each  -set. Unfortunately that works out as
-set. Unfortunately that works out as  which is unhelpful. So it looks as though F can’t be too homogeneous.
which is unhelpful. So it looks as though F can’t be too homogeneous.
Another question that occurs to me is that if you are asking for something even more drastic than I asked for then what does Terry’s argument from this comment say?
Sorry, that should have been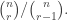
Right.
So let me rephrase (slightly generalize) the impossibility of having a family with a super-linear index: let r be the largest size of an intersection of two sets from F. There can be at most n-r sets that contain this intersection since otherwise two of them will share an additional item giving a larger intersection hence a contradiction.
I wonder if this logic can be generalized to the “average index” thereby proving an upper bound on the original problem.
If we take all sets, then almost all intersections have size about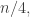 so the average index is exponentially large. (Or else I have misunderstood the question.)
so the average index is exponentially large. (Or else I have misunderstood the question.)
yes, this indeed doesn’t make sense.
Small inconsistency in the wiki: it says the -shadows form a convex sequence. This should be qualified as to apply if each set has size
-shadows form a convex sequence. This should be qualified as to apply if each set has size  . Otherwise
. Otherwise  is convex, but its 2-shadow is not.
is convex, but its 2-shadow is not.
This is an attempt to “fix the multiset issue” in Terrence Tao’s construction where consists of the multisets
consists of the multisets 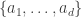 with
with 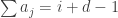 .
.
I start with the $\latex d=2$ case. I introduce a new repetition symbol x and use the set instead of the multiset
instead of the multiset  . Now this is not working as
. Now this is not working as  will be in the support of every other
will be in the support of every other  . So I break it up and use a different repetition symbol in different intervals for
. So I break it up and use a different repetition symbol in different intervals for  . On can simply use the same symbol
. On can simply use the same symbol  for
for 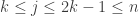 and “fill in” with pairs
and “fill in” with pairs  for
for  in between. This means cca
in between. This means cca  extra symbols (can be brought down to cca $\latex \log n$) and the estimate
extra symbols (can be brought down to cca $\latex \log n$) and the estimate  .
.
Example: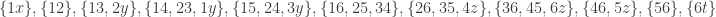 .
.
For the example there will be a tiny improvement in the bound if you simply delete the final (6,6) pair instead of introducing a new repetition symbol. But that is just an additive constant.
In the general case one starts with introducing
one starts with introducing  repetition symbols, where
repetition symbols, where  is to be interpreted as “elements number
is to be interpreted as “elements number  and and number
and and number  are equal in the increasing ordering of Tao’s multiset”. As before, this is not good as is.
are equal in the increasing ordering of Tao’s multiset”. As before, this is not good as is.
I interpret the convexity condition as “the families containing a set containing must form an interval for every set
must form an interval for every set  “. This is meaningful for
“. This is meaningful for  , so for
, so for 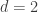 we had only to worry about the supports, now we have to worry about 2-shadows and higher too. But I still believe that with splitting the new symbols into a logarithmic number of intervals this is doable. If so, it would give
we had only to worry about the supports, now we have to worry about 2-shadows and higher too. But I still believe that with splitting the new symbols into a logarithmic number of intervals this is doable. If so, it would give  .
.
Gabor, I guess you mean . Your bound, as stated, specializes to
. Your bound, as stated, specializes to  …
…
I should have said it before but there is a new thread of comments https://gilkalai.wordpress.com/2010/10/03/polymath-3-the-polynomial-hirsch-conjecture-2/
Pingback: Polymath3 : Polynomial Hirsch Conjecture 3 « Combinatorics and more
One idea I had a long time ago about Hirsch conjecture and also about linear programming (which I never got anywhere with) is this. It’s also an
interesting problem in its own right.
We want to walk from vertex A to vertex B with few steps.
Set up a linear objective function F that is maximized at B. Now walk using
simplex method from A to some neighboring vertex, CHOOSING AMONG
NEIGHBORS THAT INCREASE F, UNIFORMLY AT RANDOM.
(The “random simplex algorithm.”)
The question is, what is the expected number of steps before you reach B?
And can it be bounded by polynomial(#dimensions, #facet-hyperplanes)?
Note, this randomness seems to defeat all (?) the constructions by Klee, Minty, & successors of linear programming problems with immensely long runtimes.
Dear Warren
Indeed this is a good idea and perhaps can be traced to early days og linear programming. It was an open problem if there are examples that this method called RANDOM EDGE is polynomial. This was resolved very recently and just a few days ago I had a post about it
Aha… great. I was about to write all sorts of elementary facts about random simplex
algorithm for your enjoyment… but since you now tell me about the Friedmann-Hansen-Zwick paper, I’ll refrain. This paper looks quite astonishing (I mean, they are bringing in what would seem at first sight, to be totally unrelated garbage, then using it as tools). It also seems highly devastating/painful to the simplex algorithm world and to any hopes of proving polynomial Hirsch.
Click to access random_edge.pdf
Commenting on Warren’s “It also seems highly devastating/painful to the simplex algorithm world and to any hopes of proving polynomial Hirsch”.
I agree with the first part but not with the second part. Here is an optimistic–for the purposes of this polymath project– reading of the Friedmann-Hansen-Zwick paper:
Since the lower bound(s) they prove for RANDOM EDGE (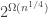 ) and RANDOM FACET (
) and RANDOM FACET ( ) are actually higher than the upper bounds we know for polytope diameters (
) are actually higher than the upper bounds we know for polytope diameters (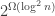 ), their result should have no effect in our beliefs about polynomiality of diameters. Rather, it only confirms the fact that getting diameter bounds and getting pivot-rule bounds are fundamentally different problems.
), their result should have no effect in our beliefs about polynomiality of diameters. Rather, it only confirms the fact that getting diameter bounds and getting pivot-rule bounds are fundamentally different problems.
In the recent examples, the polytopes themselves are I believe combinatorially isomorphic to cubes.
Eralier, for the abstract setting such lower bounds were achieved by Matousek (RANDOM FACET) and Matoousek and Szabo (RANDOM EDGE). Also there the polytope was combinatorially the cube.
It would be nice to have a high-level description of what is going on in the Friedmann-Hansen-Zwick paper. It contains a forest of details, but it’s pretty hard to feel confident they know what they are doing, if you don’t digest all the details.
Pingback: A combinatorial version for the polynomial Hirsch conjecture | Q&A System
Pingback: Some old and new problems in combinatorics and geometry | Combinatorics and more
You made some decent points there. I looked online for the problem and found most individuals will go coupled with using your site.