
Here we start the second research thread about the polynomial Hirsch conjecture. I hope that people will feel as comfortable as possible to offer ideas about the problem. The combinatorial problem looks simple and also everything that we know about it is rather simple: At this stage joining the project should be very easy. If you have an idea (and certainly a question or a request,) please don’t feel necessary to read all earlier comments to see if it is already there.
In the first post we described the combinatorial problem: Finding the largest possible number f(n) of disjoint families of subsets from an n-element set which satisfy a certain simple property (*).We denote by f(d,n) the largest possible number of families satisfying (*) of d-subsets from {1,2,…,n}.
The two principle questions we ask are:
Can the upper bounds be improved?
and
Can the lower bounds be improved?
What are the places that the upper bound argument is wasteful and how can we improve it? Can randomness help for constructions? How does a family for which the upper bound argument is rather sharp will look like?
We are also interested in the situation for small values of n and for small values of d. In particular, what is f(3,n)? Extending the problem to multisets (or monomials) instead of sets may be fruitful since there is a proposed suggestion for an answer.

To summarise some of the discussion from the previous thread, I think it would be a good idea to focus a fair bit of effort on understanding f^*(3,n), defined as the largest number t of families one can have consisting of 3-element multisets {a,b,c} obeying the convexity condition. We have two basic examples that illustrate that this quantity is at least 3n-2:
* Nicolai’s (and Klas’s) example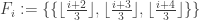 for i=1,…,3n-2
for i=1,…,3n-2
* My example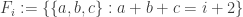 .
.
Perhaps there is a one-parameter family of intermediate examples that interpolate between these two. But there does not yet seem to be any example that breaks the 3n-2 barrier; perhaps we can start working out f^*(3,n) for small values of n (From Nicolai’s first comment it appears that f^*(3,n) = 3n-2 has already been verified up to n=8).
On the other hand, the [AHRR] argument, a version of which is on the wiki, gives something like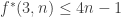 (there seems to be a bit of scope to improve the -1 constant term though). The basic idea is to try to greedily break up the families into blocks with a common element and with a fairly small total support, so that one can exploit the existing bound
(there seems to be a bit of scope to improve the -1 constant term though). The basic idea is to try to greedily break up the families into blocks with a common element and with a fairly small total support, so that one can exploit the existing bound 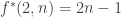 . It would be nice to see if there were other arguments that also gave a linear bound on
. It would be nice to see if there were other arguments that also gave a linear bound on 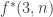 ; the argument based on using m-restrictions (to use Tim’s notation) seems to lose a lot of information somehow.
; the argument based on using m-restrictions (to use Tim’s notation) seems to lose a lot of information somehow.
I also like Tim’s idea of trying to exploit using the 2-shadows of F_i (the set of pairs {a,b} that are contained in one of the sets in F_i). All our arguments are currently relying only on the 1-shadow U_i and so one can hope that the 2-shadows are somehow carrying more information.
Although investigating f*(3,n) indeed looks like it will be more fruitful, I also still like the simpler question raised by Klas: what is f(2,n)? (I.e., what if we really insist that each F_i is a (non-multi-)set of cardinality 2?) The answer is somewhere between (3/2)n and 2n.
I conjecture the answer here to be f(2,n) = 2n – O(log n). My construction starts from my multiset example, say for n=10:
F_1 = { {1,1} }
F_2 = { {1,2} }
F_3 = { {2,2}, {1,3} }
F_4 = { {2,3}, {1,4} }
…
F_9 = { {5,5}, {4,6}, …, {1,10} }
F_10 = { {5,6}, {4,7}, …, {2,10} }
…
F_18 = { {9,10} }
F_19 = { {10,10} }
basically, what one has to do here is to replace the degenerate multisets {1,1}, {2,2}, …, {10,10} by genuine multisets. I can do this by adding a few more numbers 11, 12, 13, etc. to the domain. For instance, I can replace {1,1} in F_1 by {1,11}. Then I can replace {2,2} in F_3 by {2,12}, {3,3} in F_5 by {3,12}, {4,4} in F_7 by {4,12}, and {5,5} in F_9 by {5,12}, but I have to throw in some more sets in the intermediate families F_4, F_6,F_8 to maintain convexity, e.g. I could add {1,12} to F_4, {6,12} to F_6, and {7,12} to F_8. At this point I run out of room for 12 and have to move up to 13: I replace {6,6} in F_11 by {6,13}, {7,7} in F_13 by {7,13}, {8,8} in F_15 by {8,13}, and {9,9} in F_17 by {9,13}, throwing (say) {3,13} back into F_12, {5,13} back into F_14, and {10,13} back into F_16 to recover convexity. Finally I have to replace {10,10} in F_19 by {10,14}. This gives f(2,14) >= 19. I think in general, this procedure costs a logarithmic factor in n, but I have not worked out the details properly.
It would be interesting to see if Terry’s construction can be made more systematic and what kind of bound it actually gives.
For N=14 it seems to give exactly the same bound as the 3/2n construction I gave so in order to really notice the 2n part of the conjecture larger values of n are needed.
The AHRR argument proceeds by greedily breaking up the t families F_1, …, F_t into blocks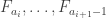 , such that each of them are supported in a fairly small set
, such that each of them are supported in a fairly small set  (with
(with  , in fact, and such that the supports
, in fact, and such that the supports 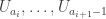 in that block have a common element
in that block have a common element 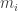 . In the d=3 case, this means that the length of each block is at most
. In the d=3 case, this means that the length of each block is at most 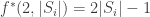 , leading to a total length of at most
, leading to a total length of at most 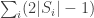 . One can show easily that we may assume wlog that there are at least two blocks for n at least 2, and this leads to an upper bound of 4n-4 for f^*(2,n).
. One can show easily that we may assume wlog that there are at least two blocks for n at least 2, and this leads to an upper bound of 4n-4 for f^*(2,n).
In Nicolai’s example, there are n-1 blocks, of the form
{{i,i,i}}, {{i,i,i+1}}, {{i,i+1,i+1}}
(so the common element here is i, and S_i = {i,i+1} has cardinality 2), plus a final block {{n,n,n}}. The bound on f^*(2,|S_i|) used here is tight; the loss is coming from all the -1’s in the sum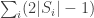 , because there are so many blocks.
, because there are so many blocks.
In my example, there are two blocks, one in which the index j of F_j ranges from 1 to 2n-1 (with common element 1 and S_i = [n]), and one in which j ranges from 2n-2 to 3n-2 (with common element n and S_i = {2,…,n}). The bound on f^*(2,n) is tight for the first block but not for the second, which is where the loss comes from. One way to think about it is that the second block can in fact be extended to a much larger block (from j=n to j=3n-2) that still has a common element n, though the total support is now enlarged slightly to [n]). The big overlap between these two blocks can then be “blamed” for the loss from 4n-O(1) back down to 3n-O(1).
So to get close to 4n, one has to use very few blocks, and they have to not “overlap” each other too much. I don’t know how to control this rather fuzzy notion of “overlap” though.
To put it another way: at present it is conceivable that f^*(3,n) is equal to 4n-4 for some n, but this is only possible under a specific scenario: one in which the first 2n-1 families F_1, …, F_{2n-1} share a common element (say 1) in their supports, while the remaining 2n-3 families F_{2n}, …, F_{4n-4} do not have 1 in their supports (which are then contained in {2,..,n}) but have another common element (say n) in their supports. Then the two blocks F_1,…,F_{2n-1} and F_{2n},…,F_{4n-4} both saturate the bound f^*(2,n) = 2n-1 without contradiction. Nevertheless, this situation should presumably not be possible, somehow because the two blocks are “competing” for the “same resources” in some way.
Regarding random constructions, one idea I had was to write things in the dual format that was mentioned in [AHRR]. Namely, for every subset A of [n], consider the (possibly empty) interval I_A of indices i such that A is contained in one of the sets in F_i. (The convexity condition ensures that this I_A is indeed an interval.) The various properties of the F_i can then be reformulated into a single axiom:
* (Layer axiom) For any A, consists of
consists of  with at most one element removed.
with at most one element removed.
The question is then to maximise the cardinality t of![\bigcup_{A \subset [n]} I_A](https://s0.wp.com/latex.php?latex=%5Cbigcup_%7BA+%5Csubset+%5Bn%5D%7D+I_A&bg=ffffff&fg=333333&s=0&c=20201002) .
.
Anyway, with this formulation it is tempting to find some semi-random way to select the intervals I_A, maybe starting from small A first and then working upwards. I haven’t tried this seriously though.
I was just thinking about lower bounds and had an idea for a construction. Thinking what it should give, I thought it ought to give a quadratic lower bound. Because of that I thought I should look at [AHRR] more carefully, and sure enough my construction wasn’t new. In fact, given that their construction is more complicated than mine but based on almost identical ideas, my guess is that mine isn’t even completely correct.
But for that very reason it seems worth briefly sketching it, either to find a slight simplification or (far more likely) to show why they did what they did.
The underlying thought is this. Suppose you have a family F of d-sets such that every (d-1)-set is contained in a set in F. These, I see from [AHRR], are called (d-1,d,n)-covering designs. Then given any two disjoint families G, H that consist of sets of size at most d, the triple (G,F,H) satisfies condition (*), since the intersection of two distinct sets of size at most d has size at most d-1. It follows that if we have a sequence of disjoint families of sets such that for each
of disjoint families of sets such that for each  there exists
there exists  such that
such that  is a
is a 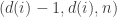 -covering design …
-covering design …
… ah, I’ve found my mistake. I was going to say that if the are non-decreasing then the sequence would be connected. I had even checked this, but I had been careless, since I had forgotten the case where
are non-decreasing then the sequence would be connected. I had even checked this, but I had been careless, since I had forgotten the case where  and
and  consist of sets of size
consist of sets of size  and
and  of sets of a bigger size. Then we can pick a set
of sets of a bigger size. Then we can pick a set  and a set
and a set  from
from 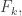 and
and 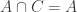 will not be contained in any set in
will not be contained in any set in 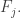 So now let me go back to AHRR and try to understand how they deal with this apparently major difficulty (major because if later sets have to avoid containing earlier sets then it seems to kill the idea completely when you have different d around).
So now let me go back to AHRR and try to understand how they deal with this apparently major difficulty (major because if later sets have to avoid containing earlier sets then it seems to kill the idea completely when you have different d around).
From a brief glance it looks as though the basic idea is this. I have tried to build what one might call an “increasing” sequence of families, and that has created the problem. They build an “increasing” family and tie it together with a “decreasing” family, at only small cost to the bound. Then if you have a triple of sizes in the increasing family, which is the problematic case, the sizes in the decreasing family will be
in the increasing family, which is the problematic case, the sizes in the decreasing family will be  which is not a problematic case. There are few details to check of course, but I think that is the basic idea. The tying process is simply this: you take two disjoint ground sets, put an increasing family
which is not a problematic case. There are few details to check of course, but I think that is the basic idea. The tying process is simply this: you take two disjoint ground sets, put an increasing family 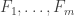 in one, a decreasing family
in one, a decreasing family  in the other, and then take
in the other, and then take 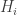 to be the set of all unions of a set in
to be the set of all unions of a set in  with a set in
with a set in 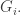
Oops, no, that’s not it, since it doesn’t actually deal with the difficulty. There’s still something clever going on that I haven’t grasped. I think I’d better stop this sequence of comments and keep the rest of my flounderings to myself.
Another comment on AHRR. They prove that the largest number of disjoint (n,r+1,r)-covering designs is at most n-r, and at least n-r(r+2).
For r=2 the upper bound is tight for large n since there exist sets of n-2 disjoint steiner triple systems, assuming that n is in the right class modulo 6, as proved in http://ams.math.uni-bielefeld.de/mathscinet/search/publdoc.html?arg3=&co4=AND&co5=AND&co6=AND&co7=AND&dr=all&pg4=AUCN&pg5=TI&pg6=RT&pg7=ALLF&pg8=ET&review_format=html&s4=&s5=disjoint%20steiner%20triple&s6=&s7=&s8=All&vfpref=html&yearRangeFirst=&yearRangeSecond=&yrop=eq&r=10&mx-pid=692824 and various papers finishing some remaining cases.
In this https://gilkalai.wordpress.com/2010/09/29/polymath-3-polynomial-hirsch-conjecture/#comment-3453 comment Tim was considering constructions for large families with d=2. If the graph used in the construction are all matchings this would lead to an “interval edge-colouring”, introduced by Asratyan in the late 80s. In these colourings the colours on the edges incident with any vertex must form an interval, and they must form a proper edge colouring.
For such colourings it is known that the number of colour classes can’t be more than 2n-3, see e.g. http://arxiv.org/abs/1007.1717v2
As for f(2,n), you can get at least by slightly extending the construction in our paper. The high-level view of our construction for d=2 is:
by slightly extending the construction in our paper. The high-level view of our construction for d=2 is:
B(A)
M(A,1;B,1)
B(B)
Here, A and B are sets of size m and n = 2m. The number of families in the B-blocks is m-c, the number of families in the M-block is m, which gives the roughly 3n/2.
Now, extend the construction to
B(A)
M(A,1;B,1)
B(B)
M(B,1;C,1)
B(C)
….
B(Z)
Taking k sets of size m for a total n=km, you get families. Setting k=m gives
families. Setting k=m gives  families.
families.
I have to think about Terry’s approach of starting with the multiset construction and then nuking the “degenerates”.
If I recall correctly, a similar argument also gives $3n – O(\sqrt{n})$ for the case d=3 for the set case.
While it would be interesting to see if the root term could be reduced I think these constructions put even more weight on Terry’s question regarding the upper bound for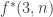 .
.
I’ll sit down later today and try to digest the EHR upper bound a bit better.
Third and last attempt to get a comment through: For d=2, you can get 2n-O(sqrt(n)) by extending our construction. This is merely a short test comment, because my previous comments seem to have disappeared.
Okay, now we’re getting somewhere. The idea is as follows. In our paper we have a high-level construction like this:
B(A)
M(A,1;B,1)
B(B)
The B-blocks are called bridges because you can extend this construction.
Our construction in the paper is this:
Bridge(A)
Mesh(A,B)
Bridge(B)
This can be extended in a straightforward way to add more mesh and bridge blocks:
Mesh(B,C)
Bridge(C)
etc.
If you take k sets of m elements, you end up with k(m-c) + (k-1)m families (the first summand for the bridge blocks, the second summand for the mesh blocks). Set k=m and you get the 2n minus a square root term.
If I recall correctly, analogous constructions can be done for any fixed d.
It still feels to me as though the elementary argument can be squeezed to give more. An initial target would be to get a bound of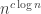 for a smaller constant
for a smaller constant 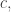 and then the hope would be to iterate the improvement to get a bound of a genuinely different type. I’m writing this comment not because I can actually do this, but because I want either to persuade people that it is possible or to understand why it is harder than it at first looks.
and then the hope would be to iterate the improvement to get a bound of a genuinely different type. I’m writing this comment not because I can actually do this, but because I want either to persuade people that it is possible or to understand why it is harder than it at first looks.
The basic idea is this. In the elementary argument we divide up the families into three subintervals as follows. We take the largest initial segment such that all families are supported in a set of size
such that all families are supported in a set of size  and note that
and note that  is at most
is at most 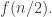 We also take the largest final segment
We also take the largest final segment  such that all families are supported in a set of size
such that all families are supported in a set of size  and note that
and note that 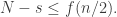 Then the union of the supports up to
Then the union of the supports up to  intersects the union of the supports after
intersects the union of the supports after 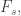 so there must be some element common to the supports of all of
so there must be some element common to the supports of all of  which leads to the bound of
which leads to the bound of  for
for 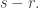
Now let us think about the supports of which I shall call
which I shall call 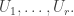 Suppose that
Suppose that  contains an element that is not contained in a later
contains an element that is not contained in a later 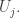 Then that element is banned from all
Then that element is banned from all  beyond
beyond 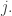 But that means that one of two possibilities holds. Either the sets
But that means that one of two possibilities holds. Either the sets 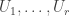 form an increasing sequence, in which case it is easy to find an element common to all the sets and do the next stage of the iteration far more efficiently, or there is an element that is banned from all sets after
form an increasing sequence, in which case it is easy to find an element common to all the sets and do the next stage of the iteration far more efficiently, or there is an element that is banned from all sets after  in which case it seems as though we can improve the bound for the middle section from
in which case it seems as though we can improve the bound for the middle section from  to
to 
This suggests to me that either I am making a stupid mistake or we can put a bit more effort into the elementary argument (note that if the above reasoning is correct then it is just the start of what one could do) and get a stronger bound.
I think I may have seen my mistake. The trouble is that if we know that every intermediate family includes an element and we also know that every intermediate family includes a second element
and we also know that every intermediate family includes a second element 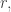 we can’t necessarily restrict to sets that contain both
we can’t necessarily restrict to sets that contain both  and
and  because the sets that contain
because the sets that contain  could be different from the sets that contain
could be different from the sets that contain  So we don’t get an easy improvement from
So we don’t get an easy improvement from  to
to 
However, I still can’t rid myself of the feeling that more can be got out if we try to push the elementary argument.
Oops, my mistake has a mistake. The improvement from f(n-1) to f(n-2) came from banning an element rather than insisting on it, so it looks as though it could be OK after all. I’ll think about this properly in about two hours’ time.
Just before I start this comment I want to make a quick meta-comment. I’m treating this polymath project as I treat ones that have taken place on my blog, in the sense that I am spilling out a lot of half-baked thoughts, or even thinking in real time as I write, rather than spending an hour or two with a piece of paper and reporting back if I find anything interesting. But I don’t mind modifying this practice if anyone (and particularly Gil) would rather I wrote less and thought harder first.
But in the absence of such an instruction for the time being, I’m going to make a preliminary attempt to improve the elementary argument. The basic idea will be to consider not just one iteration but two and see what happens. (A few minutes ago I did in fact sketch something out on a piece of paper over a cup of coffee, and my impression then was that I could save a factor of n, which is not that interesting on its own but it is vaguely promising.)
As in the elementary argument, and after permuting the ground set if necessary, we can assume that the sequence of families is divided into three intervals, one consisting of families that live in![[n/2],](https://s0.wp.com/latex.php?latex=%5Bn%2F2%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002) one of families that all use the element
one of families that all use the element  and one of families that live in
and one of families that live in ![[n/2+2,n]](https://s0.wp.com/latex.php?latex=%5Bn%2F2%2B2%2Cn%5D&bg=ffffff&fg=333333&s=0&c=20201002) (or something along those lines — I don’t want to get too involved in parity considerations).
(or something along those lines — I don’t want to get too involved in parity considerations).
Let’s now consider the first interval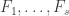 of families. We know that
of families. We know that  but now I want to say something more detailed. To do that I would like to divide into two cases. Let
but now I want to say something more detailed. To do that I would like to divide into two cases. Let  be the support of
be the support of  In the first case let us assume that the
In the first case let us assume that the  up to
up to 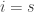 are not nested upwards. In that case, some
are not nested upwards. In that case, some  contains an element
contains an element  that is not contained in a later
that is not contained in a later  From that it follows that
From that it follows that  can never be used again, so the number of families in the middle interval is at most
can never be used again, so the number of families in the middle interval is at most 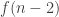 (as we see by restricting to sets that contain
(as we see by restricting to sets that contain  and exploiting the fact that they do not contain
and exploiting the fact that they do not contain  ). So in that case we get a bound of at most
). So in that case we get a bound of at most 
In the second case, the are nested upwards in the initial interval and downwards in the final interval (or else we can run the previous argument but reflected in
are nested upwards in the initial interval and downwards in the final interval (or else we can run the previous argument but reflected in  ). That means that any element used in
). That means that any element used in 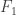 is used in all of
is used in all of 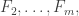 so the number of families is at most
so the number of families is at most 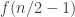 by the restriction argument. So in this case we get a bound of at most
by the restriction argument. So in this case we get a bound of at most 
Which of these two bounds is bigger? That’s equivalent to asking which is bigger out of and
and 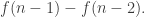 Assuming that
Assuming that  grows reasonably fast, as we may, the second is much bigger, which implies that
grows reasonably fast, as we may, the second is much bigger, which implies that  is a new upper bound.
is a new upper bound.
What effect does that very slightly improved recurrence have on the bound for ? One way of trying to estimate this is to apply the iteration to the inner
? One way of trying to estimate this is to apply the iteration to the inner  to get an upper bound of
to get an upper bound of  and again and again until the middle interval has got down to size
and again and again until the middle interval has got down to size 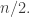 That gives us exactly what we would have got with the original iteration except that all the arguments have had 1 subtracted. Now if
That gives us exactly what we would have got with the original iteration except that all the arguments have had 1 subtracted. Now if  is in the general ball park of
is in the general ball park of 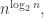 then the difference we make by subtracting 1 from n is a ratio of around
then the difference we make by subtracting 1 from n is a ratio of around 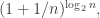 which is not that wonderful. In fact, it’s not that wonderful even when we iterate the observation, which we get to do about
which is not that wonderful. In fact, it’s not that wonderful even when we iterate the observation, which we get to do about 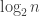 times. Indeed, it seems to give an improvement by a constant factor (which comes almost entirely from right at the beginning of the induction).
times. Indeed, it seems to give an improvement by a constant factor (which comes almost entirely from right at the beginning of the induction).
However, there is more to say, which I’ll say in a new comment.
Dear Tim, regarding the meta-comment. Writing many half-baked thoughts even in real time is most welcome. (I am a bit slow contributing this time but I intend to catch up.) Other forms of operation are welcome as well.
The extra that one can say — and I don’t know how significant it is — is that if the above argument can’t be improved then some pretty strong things can be said about the system. Suppose we have that the supports of the first families form a non-decreasing sequence with
families form a non-decreasing sequence with ![U_r=[n/2].](https://s0.wp.com/latex.php?latex=U_r%3D%5Bn%2F2%5D.&bg=ffffff&fg=333333&s=0&c=20201002) There are all sorts of ways that we might try to improve on the obvious bound of
There are all sorts of ways that we might try to improve on the obvious bound of 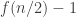 for
for  To discuss this, let me assume WLOG that the
To discuss this, let me assume WLOG that the  are initial segments. Then instead of using the fact that
are initial segments. Then instead of using the fact that  for every
for every 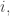 we could use the fact that all but at most
we could use the fact that all but at most 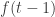 families use the element
families use the element 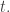 If for no
If for no  does that give rise to a substantial improvement, then we know that several
does that give rise to a substantial improvement, then we know that several  -restrictions fail to be monotone.
-restrictions fail to be monotone.
If a -restriction fails to be monotone, it tells us that we can find
-restriction fails to be monotone, it tells us that we can find 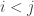 such that
such that 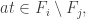 which bans
which bans  from the lower shadow of all subsequent families. However, this is not yet a very strong condition because we have only a linear number of 2-sets that we are able to ban. Or at least I think that is the case.
from the lower shadow of all subsequent families. However, this is not yet a very strong condition because we have only a linear number of 2-sets that we are able to ban. Or at least I think that is the case.
I think I need to do a bit of thinking away from a keyboard, but one problem that might be worth considering is what the effect is on the bound if we have a ground set of the form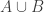 with
with  and
and  disjoint sets of the same size, and we have a matching
disjoint sets of the same size, and we have a matching  between
between  and
and 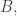 and we ban all sets that have a subset of the form
and we ban all sets that have a subset of the form 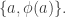
Pingback: Polymath3 « Euclidean Ramsey Theory
I have a sort of meta comment: I presented the problem in a fairly “naked” way because I thought this will be most effective. If there are connections, equivalent formulations, or other things that I should elaborate on please let me know. (Often, I find it hard to juggle between equivalent formulations no matter how simple the equivalence are…) I do intend to repeat the simple connection between the formulation in terms of diameter of certain graphs and the formulation in terms of families because maybe it is useful to be familiar with both. Any other advice regarding running the project is most welcome.
I rather like the naked formulation myself, because if I understood better how the combinatorial problem implied results about polytopes I think I’d be more afraid of thinking about it …
Let me repeat the equivalence between the two EHRR formulations: One formulation was this:
You have a graph G so that every vertex v is labeled by a subset S(v) of {1,2,…,n} (We can further require that |S(v)|=d or that |S(v)|<=d.) We assume that all these subsets are distinct and that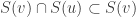 .
.
(**) for every two vertices v and u there is a path so that all vertices w in the path satisfy
f(n) (respectively f(d,n)) is the maximum diameter of this graph.
Starting with such a graph G and a vertex u we obtain families by letting
by letting 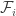 to be all the sets of labeles of vertices of
to be all the sets of labeles of vertices of  which are of distance i+1 from u.
which are of distance i+1 from u.
The condition (*) is satisfied because when you consider a set S(v) in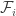 and S(w) in
and S(w) in 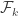 then the path between v and w which satisfies (**) will necessary have a representative in
then the path between v and w which satisfies (**) will necessary have a representative in  for every j strictly between i and k.
for every j strictly between i and k.
In the other direction, if you have families you can just associate to every set in every family a vertex and connect all vertices for the ith family to all vertices in the (i+1)th family.
Gil,
With your express invitation to write out equivalent formulations, even if the equivalence is quite silly. Here is an equivalent formulation of the number of disjoint covering designs problem:
Color the (k+1)-faces of an (n+1)-simplex so that each k-face has all colors. How many colors are possible?
I find it a little easier to think of it in the polar formulation:
Color the (n-k-1)-faces of an (n+1)-simplex so that each (n-k)-face has all colors. How many colors are possible?
Question: is there a color assignment function that can be defined on each facet of the simplex, in such a way that it is well defined over the entire simplex?
It may be good to have a “non-inductive” proof of f(2,n) <= 2n-1 (or f^*(2,n) <= 2n-1), as this may shed more light on how to bound f^*(3,n) accurately. The main thing here, I think, is to get the main term 2n; to begin with, one can be sloppy with the -1 error, viewing it as a lower order term.
The idea I had in this regard was to try to "factor" the problem of constructing families F_1,…,F_t of 2-element sets (or multi-sets) in to that of constructing the 1-shadows (aka supports) U_1,…,U_t first, and then selecting the 2-shadows (which, in this d=2 setting, are just F_1,…,F_t).
One obvious constraint on the U_i is convexity, which is a simple enough condition. Another constraint, if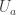 and
and  have a common element m, then we know that
have a common element m, then we know that  from the
from the 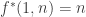 bound. Again, this looks like an easy condition to understand.
bound. Again, this looks like an easy condition to understand.
The trick is, once one fixes the 1-shadows U_i, how to fill in the 2-shadows. Here, there are two constraints. Firstly, no edge can be used more than once. Secondly, each F_i actually has to cover all of its support U_i.
This is sort of a packing problem. One can try to abstract away the mechanics of how one actually does the packing, by instead writing down basic bounds on the F_i that come from volume considerations. For instance, since the F_i have to cover U_i, we have
but then since they have to be disjoint, we have
Perhaps this (together with the information on the shadows U_i) is already enough to get a bound of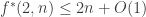 ?
?
If we understand how this works then perhaps we can ramp it up to d=3, looking at how the 1-shadows, 2-shadows, and 3-shadows interact with each other.
p.s. I'll be traveling for the next few days and will probably post quite little to this thread for a while.
I should perhaps clarify: the [AHRR] argument gets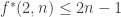 purely by using the information on the supports U_1,…,U_t, namely the convexity and the bound
purely by using the information on the supports U_1,…,U_t, namely the convexity and the bound  when
when 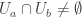 , using a covering argument (which, coincidentally, bears some resemblance to the Besicovitch covering lemma). But I’m hoping that some of the 2-shadow information can help reduce the dependence on these 1-shadow facts, because if one repeats the 1-shadow argument in d=3 one only gets the 4n-O(1) bound rather than the 3n-O(1) bound that we are shooting for.
, using a covering argument (which, coincidentally, bears some resemblance to the Besicovitch covering lemma). But I’m hoping that some of the 2-shadow information can help reduce the dependence on these 1-shadow facts, because if one repeats the 1-shadow argument in d=3 one only gets the 4n-O(1) bound rather than the 3n-O(1) bound that we are shooting for.
One thought on the structure of the for the d=2 case.
for the d=2 case.
If we view each as a graph with vertex
as a graph with vertex  I believe that we can assume that no connected component contains a path on three edges. If it did we could delete the middle edge of the path without violating any of the conditions.
I believe that we can assume that no connected component contains a path on three edges. If it did we could delete the middle edge of the path without violating any of the conditions.
So every component of is either an edge or a star, which means that
is either an edge or a star, which means that 
In general we should be able to delete any set in such that all its
such that all its  -subsets are contained in other members of
-subsets are contained in other members of  .
.
Here are some meta-thoughts and later some thoughts of the problem.
1) The ideal mode of polymath in my eyes would allow a large number of people (Ok, by large I probably mean a few dozens) to follow a project comfortably along with their main research projects and other duties. I realize that in the successful polymath1 the mode of participation was more intensive (and, of course, since I truly want this problem get settled I would be happy to see such an intensive paste over here,) but in order to have useful projects of this kind, perhaps a few in parallel, it should be in a paste, and form (and in a software platform ), which allow people to follow it along with their main activities, and perhaps even to jump in and out.
2) Perhaps the most difficult thing in such a project is to take a step initiated by one participant to push it a little forward, preparing it for more participants . Perhaps this is a bit like in football, if you have to receive the ball from another player and than to dribble with it and move it to another player this is sort of complicated. (Here I mean European football, aka soccer).
3) As the host, I will be happy to do anything which you may think can be useful to the project. (Unfortunately, serving pizza or coffee is not supported by wordpress at this time).
Some thoughts about the problem:
1) I really like the plan to try to understand f*(3,n) (or f(3,n)). (Without neglecting also f(2,n)). I never thought about this avenue, but in hindsight it looks good.
There is a sister problem to PHC which is about effective (randomized) pivot rules for LP problems with d variables and n variables. (And various abstractions) and also there looking at fixed d (by a long list of people: Megiddo, Seidel, Klarkson, Sharir-Welzl, Matousek, Chazelle…) was an avaenue also for results when d is general.
2) What is really frustrating about the reccurence f(d,n)<=2f(d,n/2)+f(d-1,n-1) is that intuitively we may think that when we reach the common 'm' and delete it we dont have to start all over again; but rather the problem is already warm. Moreover by replacing f(d,n/2) by f(d,2n/3) we can reach one out of n/3 m's at our choice. We need an idea how to gain something inside the reccursion.
3) One idea I tried to play with (for which I need the graph with labelled set formulation) is this. Suppose that you give weights w_1,…,w_n to the vertices. And you give weights to sets which is the product of the weights of the vertices. And that when you compute the diameter you count every vertex by the weight of its label. It looks that maybe we can get a reccurence relation to f(d,w_1,…,w_n) the upper bound of such weighted diameter. I do not see how it can help us though.
4) trying to find examles which somehow behave as badly as the reccurence, perhaps with some randomization is certainly something to be tried.
5) I wonder for what class of graded lattices the upper bound argument work. It works for sets; it works perhaps for atomic graded lattices in which every interval is atomic; but somehow monomials are not such lattices so it may eextend further. (This is a side question except for the desperate thought that if we indeed the scope of the inequality sufficiently we may make it sharp.)
6) There are some pleasant inequalities for f(d,n) when n is a constant tines d. This suggests that the really bad case may be when n is a power of d.
Also Nicolai’s conjecture f*(d,n)=d(n-1) + 1 is very elegant. And the function d(n-1)+1 appears in various extremal combinatorial problems.
A rather standard method which is sometimes useful when we have an extremal problem with multiple extremal examples is the “linear algebra method” (or dimension argument) : to associate to the things we want to bound (the families in our case) elements in a vector space of the required dimension ((d(n-1)+1) in our case) and to show that the assumptions implies that the elements are linearly independent. (See this tricki article http://www.tricki.org/article/Dimension_arguments_in_combinatorics and also https://gilkalai.wordpress.com/2008/05/01/extremal-combinatorics-i/ https://gilkalai.wordpress.com/2008/12/25/lovaszs-two-families-theorem/ )
I was wondering about that too, for precisely that reason. But what the Tricki argument doesn’t give (because I don’t have an answer to this) is any kind of half-systematic method for thinking up a vector space to use. Is there any sort of philosophical account of what to do?
Off topic: Shouldn’t [AHRR] be [EHRR]? {GK: right.}
I do not know if this is of any use, but there is a way to encode the problem that makes the convexity condition simple (but mess up the disjointness). Simply consider for a subset $A$ of $1,\ldots,n$ the sets $I(A)$ of indices $i$ such that there is a $B\in\mathcal{F}_i$ containing $A$. Then the convexity translates to the $I(A)$ being intervals, while the disjointness can be translated into the property
(1) that the set $i(A)$ of indices appearing in $I(A)$ but not in any $I(A’)$ where $A’$ runs over the successors of $A$, is empty or a singleton.
Of course, the definition of $I(A)$ make $I$ a decreasing map (with respect to inclusion) and the data of a decreasing map $I$ satisfying (1) defines a unique convex family of subsets.
Here is an illustration of the preceding formulation. I propose to recover the fact that if {1,…,n} is in some convex family, then this family has cardinal at most 2n.
Under the hypothesis, we have that I(1,2,…, n) is some singleton (the alternative would be that it is empty). But then, all the I(A) with A of cardinal n-1 must be concentrated in a size 3 interval (each one of them have at most one point that is not in I(1…n) ). An immediate induction shows that the I(A) with card A=n-k are concentrated on an interval of size 1+2k. Last,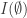 must be concentrated on an interval of size at most 2n.
must be concentrated on an interval of size at most 2n.
We can also get the same kind of information on the lower lever. Assuming that I(1,…,n) is empty, I claim that there are at most 3 sets A of cardinal n-1 such that I(A) is not empty.
Such sets satisfy that I(A) is a singleton, and if there were at least 4 of them, there would be 2 such sets A,B whose indices differ by at least 3. Let C be the intersection of A and B. Then I(C) contains I(A) and I(B), so that it has cardinal at least 4. But A, B and {1,…,n} are the only successors of C, a contradiction with the disjointness condition.
Is that basically the dual formulation mentioned by Terry above?
Ah, yes it is exactly the same formulation indeed.
I just wanted to mention a slight modification to how one can describe the problem. It isn’t enough of a modification to qualify as a reformulation, since it is too trivially equivalent to the original problem, but it is a slight change of language that I find I prefer. (Also, it is the kind of observation that anyone who has thought seriously about the problem will be aware of already I’m sure. This comment is therefore mainly for the benefit of people who are dipping into the discussion and hoping to follow some of it.)
Recall that a \textit{down-set} is a collection of subsets of![[n]](https://s0.wp.com/latex.php?latex=%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) that is closed under taking subsets. We would like to find an upper bound for the length of a sequence of down-sets
that is closed under taking subsets. We would like to find an upper bound for the length of a sequence of down-sets  if it satisfies the following two conditions.
if it satisfies the following two conditions.
1. For every set![A\subset[n]](https://s0.wp.com/latex.php?latex=A%5Csubset%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) the set of
the set of  such that
such that 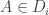 is an interval.
is an interval.
This can be rephrased as follows, which I find useful because it tells us when certain sets are banned from all future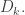
1′. If and
and 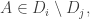 then
then 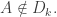
2. No two of the share a maximal element.
share a maximal element.
Let me prove that this is equivalent to the original formulation. Given a sequence of families satisfying the disjointness and convexity conditions, let
satisfying the disjointness and convexity conditions, let  be the down-set generated by
be the down-set generated by  (that is, the collection of all subsets of sets in
(that is, the collection of all subsets of sets in  Then every maximal element of
Then every maximal element of  is an element of
is an element of 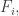 so the disjointness condition for the
so the disjointness condition for the  implies the disjointness condition for the
implies the disjointness condition for the  Also, if
Also, if  and
and  then we can find sets
then we can find sets  and
and 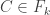 that contain
that contain  It follows from the convexity condition that we can find a set
It follows from the convexity condition that we can find a set 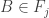 that contains
that contains 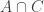 and hence
and hence  Therefore
Therefore 
In the other direction, given the down-sets we can define
we can define  to be the set of maximal elements of
to be the set of maximal elements of  Then we get the disjointness condition trivially. Also, if
Then we get the disjointness condition trivially. Also, if  and
and  and
and 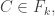 then
then 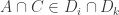 and hence, by condition 1,
and hence, by condition 1, 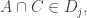 which implies that there is some set in
which implies that there is some set in  that contains
that contains 
Now why should this formulation be even slightly advantageous? I don’t know if I yet have a precise answer to this — it’s more like a hunch that it encourages one to think about the problem in “the correct” way. One aspect of it that makes me feel more optimistic is that down-sets are quite structured objects, so it somehow feels more plausible that it should be hard to create sequences of down-sets with constraints.
What are these constraints? Well, as we define a longer and longer sequence of down-sets, we find that more and more sets become forbidden. And building a down-set that is forced to avoid a whole lot of sets can be quite hard.
Let me try to justify the first of those two statements in a small way. Suppose we tried to be very extreme and produce a sequence of down-sets with each one contained in the next, but still satisfying the distincnt-maximal-elements condition. Then each maximal element in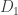 would have to be contained in a strictly larger maximal element in
would have to be contained in a strictly larger maximal element in  and so on. So trivially we can’t have an increasing sequence of down-sets satisfying the disjointness condition of length greater than
and so on. So trivially we can’t have an increasing sequence of down-sets satisfying the disjointness condition of length greater than 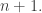
And now let me think very briefly about the second condition by considering what effect it would have if we knew that our down-sets were not allowed to contain the set That means that WLOG the supports start off not containing 1 or 2, then they contain 1, then they contain neither, then they contain 2, and finally they contain neither again. (Some of these intervals could be empty.) This isn’t getting me anywhere.
That means that WLOG the supports start off not containing 1 or 2, then they contain 1, then they contain neither, then they contain 2, and finally they contain neither again. (Some of these intervals could be empty.) This isn’t getting me anywhere.
One final brief and speculative thought. Perhaps the problem would yield to some kind of very clever induction that takes into account far more than just the size of the ground set. For example, we might try to generalize the problem vastly by giving an upper bound for the maximum length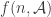 of a sequence of down-sets satisfying the given condition, given that all sets in
of a sequence of down-sets satisfying the given condition, given that all sets in  are forbidden. And perhaps we could express that in terms of some other pairs (integer, set-system) that are in some sense simpler.
are forbidden. And perhaps we could express that in terms of some other pairs (integer, set-system) that are in some sense simpler.
Sorry, a better way of putting that very last point is to fix once and for all and just do an induction on the set systems
once and for all and just do an induction on the set systems 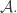 Then
Then  is just the length of the longest sequence of down-sets when the set
is just the length of the longest sequence of down-sets when the set  is banned. If we define
is banned. If we define  to be the length of the longest sequence when no sets in
to be the length of the longest sequence when no sets in  are allowed, then the hope would be to show that
are allowed, then the hope would be to show that  can be bounded above in terms of the values at
can be bounded above in terms of the values at  for some “worse” set-systems
for some “worse” set-systems 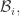 where that means that they contain more sets, or smaller sets, or something like that. (I think what we really want is that they have bigger upper shadows.)
where that means that they contain more sets, or smaller sets, or something like that. (I think what we really want is that they have bigger upper shadows.)
Let me have another go at saying, still in vague terms, what it might be possible to do.
For each and each
and each ![A\subset[n]](https://s0.wp.com/latex.php?latex=A%5Csubset%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) let
let 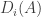 be the trace of
be the trace of  on
on 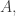 that is, the collection of all sets
that is, the collection of all sets  such that
such that 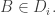 Then
Then 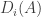 is of course still a down-set. Also, if the down-sets
is of course still a down-set. Also, if the down-sets  satisfy the convexity condition (by which I mean conditions 1 and 1′ above) then so do the down-sets
satisfy the convexity condition (by which I mean conditions 1 and 1′ above) then so do the down-sets  This follows trivially from the fact that
This follows trivially from the fact that 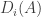 is the intersection of
is the intersection of  with the power-set of
with the power-set of 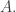
A simple consequence of this is that if then the sets
then the sets 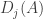 for
for 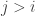 are monotone decreasing. Indeed, if
are monotone decreasing. Indeed, if 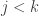 and
and 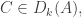 then since
then since 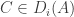 (as
(as  is a down-set) it follows that
is a down-set) it follows that  (by the convexity condition).
(by the convexity condition).
Now we know that monotone families of down-sets can’t be too big, so it seems at first as though this “downward pressure” that places on the subsequent down-sets should be rather strong. Unfortunately, that doesn’t follow because we lose the distinct-maximal-elements condition.
places on the subsequent down-sets should be rather strong. Unfortunately, that doesn’t follow because we lose the distinct-maximal-elements condition.
However, there may be some pressure in this direction too. After all, the number of families that contain a given set is at most
is at most  which is pretty small if
which is pretty small if  is at all large and
is at all large and  grows superpolynomially. So even if we don’t have a distinct-maximal-elements condition we might hope for a don’t-use-maximal-elements-too-often condition. Whether anything like this can be developed into an argument that gives an interesting bound is of course quite another matter.
grows superpolynomially. So even if we don’t have a distinct-maximal-elements condition we might hope for a don’t-use-maximal-elements-too-often condition. Whether anything like this can be developed into an argument that gives an interesting bound is of course quite another matter.
I think that f(4)=8. What follows is a case-by-case argument; I am not sure that it gives any real insight. I use the dual formulation notations.
First, the case when I(1234) is not empty is settled so we assume the contrary. Moreover, at most three of the I(abc) can be non empty. First consider the case when I(123), I(124), I(134) are non empty. Then by looking for example at the I(1a) we see that the 3 singletons are confined in an interval of length 3. It follows that the I(ab) are confined in an interval of length 5, that the I(a) are confined in an interval of length 7, and we are done because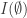 contains at most one more element.
contains at most one more element.
The second case is when exactly two I(abc) are non-empty, I(123) and I(124) say. If their values differ by 2 (which is maximum possible), then I(13) and I(23) are confined in an interval E of length 3, I(14) and I(24) are confined in an interval F of length 3, and F intersects E in only one point (between I(123) and I(124)). Now I(34) can be empty, in which case the I(ab) are confined in an interval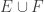 of length 5, or I(34) is a singleton and we only have to show that it is in that same interval.
of length 5, or I(34) is a singleton and we only have to show that it is in that same interval.
But if it where, e.g., on the right of this interval, then I(3) would have at least 2 points not lying in any of I(13), I(23), I(123) nor I(34), a contradiction. If I(123) and I(124) are adjacent or equal, then all of I(ab) where ab is not 34 are confined in a interval G of length 4, which is a union of two intervals of length 3, the first one containing I(13) and I(23), the second one I(14) and I(24). A similar argument than above proves that I(34) must be adjacent to G, so that once again the I(ab) are confined in an interval of length 5.
The third case is when exactly one of the I(abc) is not empty, I(123) say. Then I(12), I(23) and I(13) are confined in a interval E of length 3 around I(123), and I(14), I(24), I(34) are either empty or singletons. Looking at I(1) shows that (if not empty) I(14) is in the 2-neighborhood of E. But looking at I(4) shows that all non-empty I(a4) are at distance at most 2, so that all I(ab) are confined in some interval of length 5. Some of them could be empty, but in any case it is easily checked that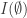 is confined in an interval of length 8.
is confined in an interval of length 8.
For the fourth case, assume that all I(abc) are empty but some I(ab) are not. Any two I(ab), I(ac) must lie at distance at most 2 (look at I(a) ). If for example I(12) and I(34) where at distance 5 or more, then all other I(ab) would be empty (otherwise they should be close to both I(12) and I(34)), so that I(1), I(2) would be confined in an interval E and I(3), I(4) to an interval F, such that E and F are separated by a gap of length 2. We then get a contradiction by looking at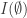 . We conclude that all non-empty I(ab) are confined in a length 5 interval if all 1234 are represented, or confined in an interval of length 3 otherwise. In both cases, we get the desired conclusion.
. We conclude that all non-empty I(ab) are confined in a length 5 interval if all 1234 are represented, or confined in an interval of length 3 otherwise. In both cases, we get the desired conclusion.
Last, consider the case when all I(ab) are empty. Then we have at most 4 points covered by the I(a), and at most 5 by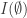 , and we are (finally) done.
, and we are (finally) done.
I moved this to the wiki.
The sentence “at most three of the I(abc) can be non empty”, has the following counter-example:
0
1
12
123
124,134,23
234
34
4
… but the conclusion f(4)=8 is still correct since the sentence “all the I(abc) are confined in an interval of length 3” holds when the four I(abc) are non-empty.
You’re right, I have been a little sloppy here. Thanks for the correction.
I have rewritten the section “on small n” in the wiki. Apart of showing that f(n)=2n for n=1,2,3,4, I included the remark that the function f'(n) (the one obtained when every F_i is a singleton) is always 2n.
(continuing with the dual notation introduced earlier). If we define a summit as a subset A of [n] such that I(A) is a singleton and no superset of A has this property, then we get immediately that the I(B) where B is a subset of A are all confined in an interval of length at most 2|A| centered at I(A).
Moreover, if B is another summit intersecting A, then the singletons I(A) and I(B) are -close, since $I(A\cap B)$ is confined by both A and B. Unless I am mistaken, we can deduce that f(n) is bounded above by
-close, since $I(A\cap B)$ is confined by both A and B. Unless I am mistaken, we can deduce that f(n) is bounded above by 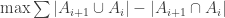 where the max is on all antichains
where the max is on all antichains  such that
such that  for all i (simply consider the left-wise summit, then reading right the last summit not disjoint to him if it exists, otherwise the next summit whatever it is).
for all i (simply consider the left-wise summit, then reading right the last summit not disjoint to him if it exists, otherwise the next summit whatever it is).
If the bound on the distance between two intersecting summits where correct, we could deduce a very good bound (quadratic or linear) on f(n), but it is not. The summits cannot be used to confine the I(B) so easily, so the argument crumbles.
I tend to think that there is something to get from looking at the summits. The case when 12…n appears in one of the families should be somehow generalized.
Maybe I should translate the definition of a summit I gave above in the main definition: it is simply a subset A of [n] that appears in one of the families, but such no superset of A does. In other words, they simply are the maximal sets appearing in the families.
One way one could try something, would be to design a procedure that takes two adjacent summits (appearing in families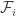 and
and  such that no
such that no 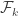 with i < k < j contains a summit) and modify the families so that their union becomes a summit, without decreasing (two much) the number of families.
with i < k < j contains a summit) and modify the families so that their union becomes a summit, without decreasing (two much) the number of families.
Let me give a very weak incentive to do that. If there is only one summit then we are done (by which I mean that m is at most 2n), since by definition all other sets appearing in the families are subsets of this one, and all goes as if 12…n appeared.
I also feel that when there are only two summits A and B, we can still prove that m is at most 2n by controlling the distance between their indices, and add to the intermediate families between them a sequence of sets going up and down from A to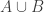 to B, without loosing the convexity condition.
to B, without loosing the convexity condition.
But maybe this is a bit speculative.
Hi everyone,
I made this comment on the previous instantiation of the blog, so I just wanted to add it again here. I apologize for spamming if this is a stupid idea, but I feel like it is applicable to the d=2 case that has been the subject of much discussion of late.
My thought is that the set families that have been defined describe the facets of a simplicial complex with the property that all of its faces have connected links. But really, in studying the Hirsch conjecture, we are dealing with simplicial polytopes, which have tons of additional structure. With this thought in mind, suppose we add the following condition on our collection of set families F_i: (I hope the tex-ing works, I don’t really know how to make the blog use math mode)
(**) Each (d-1)-element subset of [n] is active on at most two of the families F_i.
Here, I mean that a set S is active on F_i if there is a d-set T \in F_i that contains S
This condition must be satisfied for polytopes — any codimension 1 face of a simplicial polytope is contained in exactly two facets.
So how does this help us in the case that d=2? Suppose F_1,\ldots,F_t is a family of disjoint 2-sets on ground set [n] that satisfies Gil’s property (*) and the above property (**)
Let’s count the number of pairs (j,k) \in [n] \times [t] for which j is active on F_k. Each j \in [n] is active on at most two of the families F_i, and hence the number of such pairs is at most 2n. On the other hand, since each family F_k is nonempty, there are at least two vertices j \in [n] that are active on each family F_k. Thus the number of such ordered pairs is at least 2t.
Thus t \leq n, giving an upper bound of f(n,2) \leq n when we assume the additional condition (**).
This technique doesn’t seem to generalize to higher dimensions without some sort of analysis of how the sizes of the set families F_i grow as i ranges from 1 to t.
For d=3 I think you have a lower bound of at least 5/3n for this version.
Partition 1…n into disjoint triples {1,2,3}, {4,5,6},….
Create a complete 3-partite 3-uniform hypergraph H with vertex classes (1,4)(2,5)(3,6)
Partition the edge set of this hypergraph into 4 perfect matchings. Each class of H has only two vertices so each 2-tuple will be in exactly two of the prefect matchings.
Use each matching as an F_i between {1,2,3}{4,5,6}
Repeat this for each consecutive pair of triples in the first list.
This gives 5(n/3-1)+1 families.
Actually you have to delete one of the matchings in order to have a correct family, so the bound is 4/3n instead of 5/3n
I do not quite understand this construction. If I am not wrong, your “complete hypergraph” is the set of faces of an octahedron, the (1,4) (2,5) (3,6) being the pairs of opposite vertices. Similarly, your “four matchings” are the pairs of opposite faces of the octahedron. In particular, {1,2,3}{4,5,6} is one of them.
What do you mean then by “Use each matching as an F_i between {1,2,3}{4,5,6}”?
… sorry, I had not read Klas’ and Nikolai’s posts below …
Dear Steve
Your comment is certainly very good and thanks for repeating it. You are correct that we consider a very abstract form of the problem. Our setting is even more general than the class of simplicial complexes with all links connected (where we do not know anything better than a linear lower bound.) I am not sure what happens when you add (**). It is certainly a good question.
Klas, I don’t think your construction works as is. If you want to start with {123} and end with {456}, then what would your second family be? Wlog it could be something like {126,453}, but then already 12 and 45 are the only “surviving” pairs that you can use.
Nicolai, there are many short examples for this e.g.
{{1,2,3}} {{1,2,4}} {{1,4,5}} {{4,5,6}}
I’m in a hurry right now but I can post the explicit example from my earlier post a little later today.
Thank you, that would be much appreciated.
Nicolai you are quite correct. When I tired to write down my example properly I found that I had miscounted an intersection, it got cover three times instead of 2.
Using the example I gave above works, but that only gives the rather dull bound of n-2
After trying out a few constructions for this problem with d=3 I have not been able to get much of a improvement. My first, failed, construction gave n-2. I have another construction which gives a lower bound of n-1.
Start with {1,2,3}, {1,2,4} next take {1,4,5},{1,5,6},…{1,i,i+1}….,{1,n-5,n-4} follow that with this, constant length, sequence of families.
{{{1, n-4, n-2}, {n-5, n-4, n-1}}, {{1, n-3, n-2}, {n-5, n-3, n-1}}, {{1, n-3, n-1}, {n-5, n-3, n-2}}, {{1, n-1, n}, {n-5, n-2, n}}, {{n-2, n-1, n}}}
n has to be at least 7 in order for all sets at the end to be distinct.
Let me try to address Tim’s question about a half systematic way to translate Nicolai’s conjecture to a linear algebra statement.
One think I am a bit confused in Nicolai’s question is what precisely replace condition (*) in the multiset version and definition of f*(d,n). Dear Nicolai can you reexplain?
Anyway we can think about Nicolai’s conjecture but just for sets for now (when we dont know it to be sharp).
Here is one possible suggestion. Consider the space of monomials of degree d in n variables. mod away the monomials which involve two non adjacent variables. This will be the vector space. (But it is all negotiable, of course; you can replace the relation
mod away the monomials which involve two non adjacent variables. This will be the vector space. (But it is all negotiable, of course; you can replace the relation  for j-i>1 by a more complicated relation if needed.)
for j-i>1 by a more complicated relation if needed.)
Now how to associate to families vectors? Here are a few suggestions
1) Suppose that the order in which the elements of {1,2,…,n} appears in sets represented in the families is compatible with the usual ordering 1,2,…,n (namely if i appears in a set in a family F_j(i) but not in a set of a smaller index family then j(1)<=j(2)<=…<=j(n)). Then associate to a
1 a) Associate to each i the variable x_i to each set (or later multiset) the monomial and to each family the sum of monomials.
1 b) The same except you associate to a family a generic linear combination of the monomials associates to sets in the family.
2)a;b the same as you take associate to each element 'j' a genaric linear combination of the variables x_1,…,x_n rather then the rule in 1)
The hope is that for some such vector space (where essentially you built the vector space based on Nicolai's most simple example) you can use (*) (and the facts that the families are disjoint) to imply linear independence.
1) is cannot work since monomials supposrted on more than 2 variables will vanish. so you need something towards 2). Of course, the more complicated you make the vector space the harder it is to apply the condition (*).
The choice of basis which is essentially powers of is tempting but it’s not clear to me how one would map a single set onto that. The easiest way that avoids the zero-ing is just to treat it as a sum, i.e. a (multi-)set {1,1,2,3} gets mapped to
is tempting but it’s not clear to me how one would map a single set onto that. The easiest way that avoids the zero-ing is just to treat it as a sum, i.e. a (multi-)set {1,1,2,3} gets mapped to 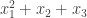 .
.
Ultimately though we want to assign each family a vector, and just taking sums would destroy information about which 2-sets, 3-sets, etc. appear in the family.
Hmm. I’ll read up on some of the linked examples on the Tricki again, maybe inspiration will come then.
It may be easier to think of the multiset version in terms of monomials over the variables x_1, …, x_n. Then f^*(d,n) is the largest number of disjoint families F_1, …, F_t of degree d monomials such that
(*) for i < j < k, whenever and
and 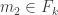 , then there exists a monomial
, then there exists a monomial 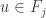 such that
such that 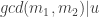 .
.
To get from this formulation back to the equivalent set case, all you do is replace "monomial" by "square-free monomial".
I'll return with more later.
Another idea that goes in the algebraic direction would be to look at algebras of the form![k[x_1,...,x_n]/(J_i)](https://s0.wp.com/latex.php?latex=k%5Bx_1%2C...%2Cx_n%5D%2F%28J_i%29&bg=ffffff&fg=333333&s=0&c=20201002) , where
, where  is some ideal corresponding to the family
is some ideal corresponding to the family  . Then perhaps (*) can be translated into a statement about homorphisms between these algebras, and related to that maybe one can say something about the length of chains of some modules.
. Then perhaps (*) can be translated into a statement about homorphisms between these algebras, and related to that maybe one can say something about the length of chains of some modules.
A first candidate for $J_i$ would be the ideal created by all monomials that do not divide an element of $F_i$.
I don’t have a good candidate for the homomorphisms though, and I have to admit that I’m a bit out of my depth in this field.
I was thinking about padding the sequence without changing its length. For instance if U and V are supports of two consecutive families and there’s an element which is in U but not in V and an element
which is in U but not in V and an element  which is in V but not in U, one can add the subset {u,v} to either of the families.
which is in V but not in U, one can add the subset {u,v} to either of the families.
Moreover, if we have a triple of consecutive supports, U, V, and W and V is a proper subset of both U and W, one can add the subset {u,w} to the middle family (here u is an element of U\V and w of W\V).
The supports of padded sequence are somewhat restricted. For instance, we can’t have a support of size 1 in the middle of such a sequence.
I’ve been trying unsuccessfully to prove a bound of the form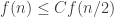 (and hence
(and hence  is polynomial) in the following way. I’ll stick with the down-sets formulation from this comment. Suppose that we have a sequence of down-sets
is polynomial) in the following way. I’ll stick with the down-sets formulation from this comment. Suppose that we have a sequence of down-sets  satisfying the convexity and disjointness conditions. (Recall that in this formulation the convexity condition says that if
satisfying the convexity and disjointness conditions. (Recall that in this formulation the convexity condition says that if  and
and 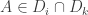 then
then 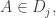 and the disjointness condition says that no two
and the disjointness condition says that no two  share a maximal element.) Now let
share a maximal element.) Now let  and
and  be two sets that partition the ground set, and just to be more specific let’s assume that
be two sets that partition the ground set, and just to be more specific let’s assume that  is even and they both have size
is even and they both have size 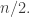 Given any down-set
Given any down-set 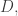 define
define  to be the set of all
to be the set of all  such that
such that 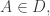 or equivalently to be the set of all
or equivalently to be the set of all 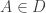 such that
such that 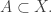 (These are equivalent because
(These are equivalent because  is a down-set.) Then trivially if
is a down-set.) Then trivially if  satisfy the convexity condition, then so do
satisfy the convexity condition, then so do  and
and 
However, these two sequences do not satisfy the disjointness condition (obviously, or else we would have proved the bound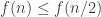 ). So one way we could think about the problem is this. Suppose we are given the down-sets
). So one way we could think about the problem is this. Suppose we are given the down-sets  and
and 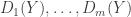 that satisfy the convexity condition. How can we find down-sets
that satisfy the convexity condition. How can we find down-sets  supported in
supported in 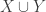 that project correctly and satisfy the disjointness condition as well?
that project correctly and satisfy the disjointness condition as well?
In principle, this can be used to investigate either the lower bound or the upper bound. In the case of the lower bound we might try to take an example for that satisfies both conditions, “stretch” it in two different ways, at the expense of losing the disjointness condition, and then put the two resulting sequences of down-sets together in some way to recover the disjointness condition with a new ground set of size
that satisfies both conditions, “stretch” it in two different ways, at the expense of losing the disjointness condition, and then put the two resulting sequences of down-sets together in some way to recover the disjointness condition with a new ground set of size 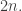 In the case of the upper bound, we might try to prove that if
In the case of the upper bound, we might try to prove that if  is at least 10 times as big as
is at least 10 times as big as  then the disjointness condition fails so badly for
then the disjointness condition fails so badly for  and
and 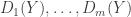 that there is no way to put the two sequences together to get a sequence with ground set
that there is no way to put the two sequences together to get a sequence with ground set 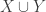 that satisfies the disjointness condition.
that satisfies the disjointness condition.
Note that trying to prove a lower bound this way would be trying to prove something rather strong: it is far from obvious that you can afford to forget all about what the down-sets actually are once you’ve proved a lower bound for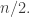 And something similar is true of the upper bound. It could be that some sequences of down-sets are easy to stretch, but then give rise to sequences that are no longer easy to stretch, or something like that.
And something similar is true of the upper bound. It could be that some sequences of down-sets are easy to stretch, but then give rise to sequences that are no longer easy to stretch, or something like that.
Just to end, here are two very simple remarks about stretching. Here are two different ways of taking the sequences supported in
supported in  and
and 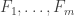 supported in
supported in  and producing a sequence
and producing a sequence 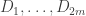 supported in
supported in  (This is supposed to be the trivial bound that one is trying to beat.)
(This is supposed to be the trivial bound that one is trying to beat.)
The first method is simply to take the sequence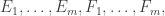 regarded as a sequence of down-sets with ground set
regarded as a sequence of down-sets with ground set  (For convenience let us assume that all the down-sets contain at least one non-empty set.) In other words, the stretching consists in converting
(For convenience let us assume that all the down-sets contain at least one non-empty set.) In other words, the stretching consists in converting  into the sequence
into the sequence 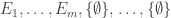 and converting
and converting 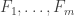 into the sequence
into the sequence  and we then put the new sequences together by simply taking
and we then put the new sequences together by simply taking  to be the union of the ith down-set in the first sequence with the ith down-set in the second sequence.
to be the union of the ith down-set in the first sequence with the ith down-set in the second sequence.
The second method is more complicated but still doesn’t give anything interesting. Following [EHHR], write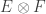 for the set of all
for the set of all  such that
such that  and
and  If
If  and
and  are down-sets, then the maximal elements of
are down-sets, then the maximal elements of 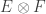 are unions of maximal elements of
are unions of maximal elements of  with maximal elements of
with maximal elements of 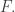 Therefore, if we take any sequence of the form
Therefore, if we take any sequence of the form  with the property that the sequences
with the property that the sequences  and
and  are increasing, and for every
are increasing, and for every  either
either 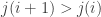 or
or  then we satisfy the disjointness and convexity conditions. Obviously since at least one of
then we satisfy the disjointness and convexity conditions. Obviously since at least one of 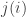 and
and 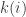 is changing each time, such a sequence has length at most
is changing each time, such a sequence has length at most 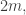 so we don’t get anything non-trivial.
so we don’t get anything non-trivial.
I now see that these two methods are not interestingly different — the first is (almost) the special case of the second where you increase the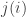 first and then the
first and then the 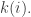
A final remark — in the above construction the “stretching” was simply a duplicating of the ground sets. But it is not necessary to do it that way. One might, for example, duplicate some maximal elements and change others. It is also not necessary to take each to be the maximal down-set that projects to
to be the maximal down-set that projects to  and
and  (which is
(which is  ).
).
(Re-corrected version of the previous comment; sorry I have been trapped by the > symbols. To Gil Kalai: would you be kind enough to erase my two previous comment please?)
I would like to propose an argument that gives a reformulation of the problem with less data. At first, I thought it would lead to , but of course there where a mistake.
, but of course there where a mistake.
I continue to think in terms of summits, but for simplicity I won’t use the dual formalism. Let recall that a summit is a subset![A\subset [n]](https://s0.wp.com/latex.php?latex=A%5Csubset+%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) that appears in one of the families
that appears in one of the families 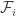 and is maximal with this property with respect to inclusion.
and is maximal with this property with respect to inclusion.
It has been explained already that if![[n]](https://s0.wp.com/latex.php?latex=%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) itself appears (and is, therefore, a summit), then
itself appears (and is, therefore, a summit), then 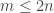 . The key point is to adapt the argument to bound the distance between any two summits.
. The key point is to adapt the argument to bound the distance between any two summits.
Lemma: if and
and 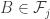 are any two summits, then
are any two summits, then
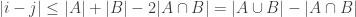 or there is a third summit
or there is a third summit  such that i< k< j and
such that i< k< j and  .
.
Note: if one gets rid of the second possibility, then .
.
We prove the lemma by contradiction. Assume that and
and 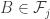 are two summits not satisfying the conclusion. There is some
are two summits not satisfying the conclusion. There is some  between
between  and
and  so
so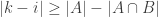 and
and  , and one of the inequality is strict. By convexity, there is some set
, and one of the inequality is strict. By convexity, there is some set 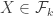 containing
containing  . Moreover, there is no summit such that
. Moreover, there is no summit such that 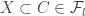 with
with  between
between  and
and  .
.
that
Assume for example that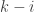 >
> . Then there is a set
. Then there is a set 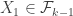 such that
such that 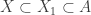 . Inductively, we get a sequence of sets
. Inductively, we get a sequence of sets 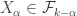 such that
such that  . This sequence has length
. This sequence has length 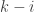 >
> , a contradiction. QED.
, a contradiction. QED.
Note: if there is a third summit such that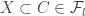 with i<l<j,
with i<l<j,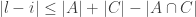 and
and  .
. because
because  can contain a lot of elements that do not lie in
can contain a lot of elements that do not lie in  . This gives at least indication on how to try to design a long convex sequence of families.
. This gives at least indication on how to try to design a long convex sequence of families.
then assuming that $(i,j)$ where chosen minimal in the lexicographic order among possible conterexample indices, we get that
This does not lead to the desired bound on
Reformulation: let where the max is on the following data:
where the max is on the following data:![A_1,\ldots,A_k\subset [n]](https://s0.wp.com/latex.php?latex=A_1%2C%5Cldots%2CA_k%5Csubset+%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) and an non-decreasing integer-valued function
and an non-decreasing integer-valued function  defined on that antichain, such that
defined on that antichain, such that 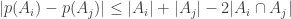 whenever there is no
whenever there is no  between
between  and
and  such that $A_k\supset A_i\cap A_j$.
such that $A_k\supset A_i\cap A_j$.
an antichain
Then $f(n)\leq g(n)$.
Sorry the formating is still not ok. I Give up my attempts to get it right since the comment is readable nonetheless.
I have a slight different perspective to the problem (dunno if it leads to somewhere). It actually simply combines the notion of downsets from gowers with this interval perspective.
Consider the graph G over the vertices![\mathcal{P}([n])](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BP%7D%28%5Bn%5D%29&bg=ffffff&fg=333333&s=0&c=20201002) and edges
and edges  . In this view downsets are just sets D where holds for every
. In this view downsets are just sets D where holds for every 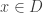 that any shortest path from
that any shortest path from  to x is entirely contained in D.
to x is entirely contained in D.
Then you extrude the graph over some time axis. That will somehow correspond to the chain, but lets don’t care on the how for now.
Next you consider downsets to be active over some time interval.
The basic idea is that you actually only need to stack active downsets on top of each other. (stack on top = the upper downset must contain the lower one). This means if downset D is active, all downsets must be active, too.
must be active, too.
Important note: These downsets do not directly correspond to the downsets generated by the . They rather correspond to the intersections of downsets of the downsets generated by
. They rather correspond to the intersections of downsets of the downsets generated by  .
.
None the less you can build a chain from such a stacking (just consider the time points, where a new downset becomes active). And also in reverse get a stacking from each chain (you get intervals and stacking property by convexity).
I think this may be a useful perspective, because it gives you the disjointness property of the chains implicitly (downsets may only become active once and hence the summits of each downset will only be used once).
How does the notion of my above post to apply the method described in [EHRR] which gives you this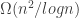 bound?
bound?
What [EHRR] does is the following: They build foundation downsets. On top of each such downset they add
foundation downsets. On top of each such downset they add  little peaks. Because
little peaks. Because  and
and 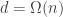 , they get their lower bound.
, they get their lower bound.
The foundation downsets again form a valid chain (of length ) and the peaks only add points on top of the foundation downset and not next to it. Hence the peaks on different foundation downsets do not interfere. Peaks on the same foundation downset, do also not interfere, because they contain just sets containing one element more than the summits of the foundation downsets. This makes the construction work.
) and the peaks only add points on top of the foundation downset and not next to it. Hence the peaks on different foundation downsets do not interfere. Peaks on the same foundation downset, do also not interfere, because they contain just sets containing one element more than the summits of the foundation downsets. This makes the construction work.
PS: This interference analysis is important, because each downset must only be active in one interval (and each peak or foundation downset may activate subset-downsets).
So can we extend the construction of [EHRR] with this perspective?
The formula that does not parse was supposed to be

The rest should be readable 😉
I’m still having trouble understanding the [EHRR] construction. Can you give slightly more detail about the foundation downsets and the little peaks?
Each peak is generated by one layer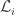 in the definition of a mesh.
in the definition of a mesh.
For the foundation down-sets see the proof of Lemma 3:
 is active on any given layer of the mesh
is active on any given layer of the mesh 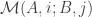 if and only if
if and only if  and
and  .
. .
. (with
(with  ,
, 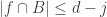 ) are the elements of the j.th foundation down-set.
) are the elements of the j.th foundation down-set.
Each foundation down-set corresponds to one mesh
So these
By the statement above follows directly that each peak (layer) covers its foundation down-set (mesh).
Actually Lemma 2 (from which the above statement of Lemma 3 is derived), says rather directly that the peaks do not cover more than their foundation-down-set. The peaks (layers) are made out of these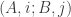 sets.
sets.
I was going to suggest something similar: indeed, I thought it was exactly the same until you said that the downsets were not the downsets generated by the
If you do take to be the down-set generated by
to be the down-set generated by 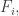 and for each
and for each ![A\subset[n]](https://s0.wp.com/latex.php?latex=A%5Csubset%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) you let
you let  be the interval of all
be the interval of all  such that
such that  then the properties the
then the properties the  must have are as follows.
must have are as follows.
(i) If then
then 
(ii) For each there is at most one
there is at most one  such that
such that  is maximal such that
is maximal such that  (That is, each
(That is, each  is allowed to be maximal at most once.)
is allowed to be maximal at most once.)
This makes sense for multisets too (with the obvious definition of ).
).
I guess this is pretty the same idea with the only difference that I had dropped condition (ii). is maximal for every
is maximal for every ![i \in I_A = [s_A, e_A]](https://s0.wp.com/latex.php?latex=i+%5Cin+I_A+%3D+%5Bs_A%2C+e_A%5D&bg=ffffff&fg=333333&s=0&c=20201002) my idea was to simply look whether
my idea was to simply look whether  is maximal at
is maximal at 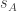 . If I’m not mistaken this should be possible wlog. Yes, because if you have the scenario where
. If I’m not mistaken this should be possible wlog. Yes, because if you have the scenario where  only becomes maximal somewhere in the middle (my chain-conversion would not contain
only becomes maximal somewhere in the middle (my chain-conversion would not contain  which is bad, because smaller) you can also let
which is bad, because smaller) you can also let  start a bit earlier and then it is maximal at
start a bit earlier and then it is maximal at 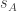 , too.
, too.
Instead of looking if
One thought I had for a way to prove the exact bound for multisets was to try to show that in a sequence of down-multisets satisfying the necessary conditions it must always be possible to pick a sequence of maximal elements that “increase” in a certain sense. Roughly speaking, the meaning of “increase” would be that there is some ordering of the ground set such that you only ever replace elements with larger elements. Note that if you have a sequence of multisets of size d that is increasing in this sense then it will not be longer than the sequence in Nicolai’s example.
Let’s suppose that all the maximal elements have size d, and let’s suppose that the order in which new elements of the ground set are added is the usual order on![[n].](https://s0.wp.com/latex.php?latex=%5Bn%5D.&bg=ffffff&fg=333333&s=0&c=20201002) Is it possible that we could have a maximal element of
Is it possible that we could have a maximal element of  that is lexicographically larger than all the maximal elements of
that is lexicographically larger than all the maximal elements of 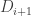 ? Let me try to produce an example with d=5, say.
? Let me try to produce an example with d=5, say.
I’ll start with (meaning the down-multiset generated by the singleton 11111), then jump to
(meaning the down-multiset generated by the singleton 11111), then jump to 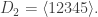 There’s nothing now to stop us taking
There’s nothing now to stop us taking 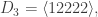 but this isn’t really a counterexample because after renaming the ground set we can think of this as
but this isn’t really a counterexample because after renaming the ground set we can think of this as 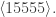 If we do indeed think of it that way, then from now on we will be forbidden to put 1 with any of 2,3,4, so it will be hard to take a step backwards.
If we do indeed think of it that way, then from now on we will be forbidden to put 1 with any of 2,3,4, so it will be hard to take a step backwards.
OK, although I have so far made only the feeblest of attempts to find a counterexample, let me make not exactly a conjecture but more of a statement that would I think prove that Nicolai’s bound is best possible but that is probably way too optimistic. It should be fairly easy to decide whether it is true. The statement is this: if are down-multisets satisfying the given condition then one can select from them a sequence of elements that are lexicographically increasing with respect to some ordering of the ground set.
are down-multisets satisfying the given condition then one can select from them a sequence of elements that are lexicographically increasing with respect to some ordering of the ground set.
Sorry, I realize I don’t quite mean lexicographically increasing. I want something a bit stronger than that. I define a partial order (with respect to the usual ordering of the ground set) as follows: given two submultisets![A,B\subset [n]](https://s0.wp.com/latex.php?latex=A%2CB%5Csubset+%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) I say that
I say that  if there is a “bijection”
if there is a “bijection”  from
from 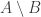 to
to  such that
such that  for every
for every 
For example, but it is not the case that
but it is not the case that 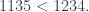 I think if we have multisets of different sizes then we might also say that a multiset increases if you remove one of its smallest elements and increases if you add an element that is maximal once added. (I’m not sure if this is the right definition — I need to mess around with trying to disprove the conjecture.) For instance,
I think if we have multisets of different sizes then we might also say that a multiset increases if you remove one of its smallest elements and increases if you add an element that is maximal once added. (I’m not sure if this is the right definition — I need to mess around with trying to disprove the conjecture.) For instance,  would be less than
would be less than 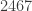 and
and 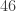 by this definition but would not be less than
by this definition but would not be less than 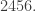
Even if none of this quite works, I don’t see an immediate reason that there couldn’t be a proof that follows this general strategy, which I’ll spell out once more.
1. Define a partial order on all multisets.
2. Prove that no strictly increasing sequence in this partial order can be longer than Nicolai’s example.
3. Prove that if satisfy the conditions of the conjecture, then we can select a strictly increasing sequence from them.
satisfy the conditions of the conjecture, then we can select a strictly increasing sequence from them.
Let’s see what can be proved if all maximal elements have size 2. If I write something like {12,34} I’ll mean the down-set generated by 12 and 34.
WLOG the first down-set is {12} (since making the first one smaller cannot harm anything). Now let’s do a case analysis. If the next down-set does not use either 1 or 2, then we are done by induction. If it uses 1 but not 2, then WLOG the next down-set is {13}, since the only reason we need it to be large is so that it will cover intersections with 12, and if 2 is not used we just have to cover 1.
Hmm. Suppose we keep going for as long as possible choosing a set of the form 1r from each down-set. We can reorder the ground set so that we choose 12, then 13, then 14, etc. Eventually we reach 1t and can no longer find a set of the form 1r that has not been used already. But the disjointness condition means that we cannot find any maximal element that involves 1, so at this point we need to find a maximal element that is bigger (in the strange ordering) than 1t. If there is any maximal element in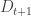 that involves a number
that involves a number  that is at least
that is at least  then we are done, since its other element is bigger than 1. If we can’t, then … well, to see what happens let me try it out with some small numbers.
then we are done, since its other element is bigger than 1. If we can’t, then … well, to see what happens let me try it out with some small numbers.
Suppose, then, that we’ve chosen 12, 13, 14, 15 and have then found that the next down-set is supported in {2,3,4}. If it contains 34, say, then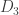 and
and 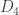 must contain something that involves 3. Let us suppose they contain something like 37 and 39. So what we know so far is that the
must contain something that involves 3. Let us suppose they contain something like 37 and 39. So what we know so far is that the  contain {12}, {13}, {14,37}, {15,39}, {34}. But we also know that
contain {12}, {13}, {14,37}, {15,39}, {34}. But we also know that 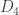 must involve 4, so I’ll add something to that too, so that now we have {12}, {13}, {14,37}, {15,39,48}, {34}.
must involve 4, so I’ll add something to that too, so that now we have {12}, {13}, {14,37}, {15,39,48}, {34}.
Oh dear, I think that is a counterexample to my hypothesis. However we order things we must have 1<3<4. Ah, but I have the choice of making 7<4. So let me rewrite this example with such a reordering: {12}, {13}, {15,34}, {16,39,58}, {35}. No, that doesn’t help. The problem is that all of 16, 39 and 58 are provably not smaller than 35 (since 5 appears before 6 and 9, and 3 appears before 8).
It still feels as though something is increasing too fast here, but I’m not sure what it is.
Another thought occurs to me, which is that perhaps compressions could help.
As a complete guess, let me see what happens if we try a so-called ij-compression. The basic idea of an ij-compression is to take some pair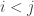 and replace every set
and replace every set  in a set-system by
in a set-system by 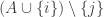 unless that already belongs to the set-system, in which case you do nothing. For example, if you apply a 12-compression to the set-system
unless that already belongs to the set-system, in which case you do nothing. For example, if you apply a 12-compression to the set-system  you get the set-system
you get the set-system 
Typically what you want to prove is that some quantity of interest goes down when you compress, so if you want to minimize that quantity you can assume that your set-system is unaltered by any ij-compression. But perhaps we could find a way of simultaneously compressing the families and preserving the convexity and disjointness properties.
and preserving the convexity and disjointness properties.
This is incredibly unlikely to work, but let me see whether we preserve these properties if we compress the families by taking their union, doing an ij-compression on that, and keeping track of which set belonged to which family. That is, we replace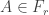 only if that doesn’t destroy the disjointness property by hitting some
only if that doesn’t destroy the disjointness property by hitting some 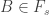 (where
(where  could equal
could equal  ).
).
Since this is set up so that the disjointness property is trivially preserved, the problem will presumably be with the convexity property. So let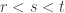 and let
and let 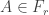 and
and  Then we know that there is
Then we know that there is 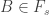 such that
such that  Given any set
Given any set 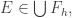 let
let  stand for the set you get by replacing
stand for the set you get by replacing  by
by  if
if  and the resulting set does not already belong to
and the resulting set does not already belong to 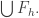
If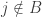 then
then  and
and 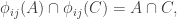 so we are fine. In fact, we can say more: if
so we are fine. In fact, we can say more: if  then removing … actually, there might be a problem. OK, here’s an example:
then removing … actually, there might be a problem. OK, here’s an example:  Then if we do an ij-compression as described above, the intersection of
Then if we do an ij-compression as described above, the intersection of  and
and  changes from being empty to being the singleton
changes from being empty to being the singleton  and there is absolutely no reason for any set in
and there is absolutely no reason for any set in  to contain either 3 or 4.
to contain either 3 or 4.
Nevertheless, it might be worth trying to come up with ways to transform existing examples into more canonical ones of the same length.
Dear Gil and others,
I’ll probably make a fool out of myself with this comment, but this problem is way too cute to not be wrong about at least once.
We are trying to maximize by just making as many families as possible, family by family; Assume, WLOG, that
by just making as many families as possible, family by family; Assume, WLOG, that 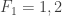 . Then:
. Then:
1) ‘introduces’ exactly
‘introduces’ exactly  new element, say
new element, say  . Why? Because, unfortunately, it’s not possible to _not_ introduce a new element and it’s not necessary (for the moment I can’t make ‘it’s not necessary’ completely rigorous, but it feels so supertrue that I can’t imagine the proof of it being anything but trivial)
. Why? Because, unfortunately, it’s not possible to _not_ introduce a new element and it’s not necessary (for the moment I can’t make ‘it’s not necessary’ completely rigorous, but it feels so supertrue that I can’t imagine the proof of it being anything but trivial)
Furthermore, 1 of the following is true:
2a) We kill off a number, say and, WLOG, we may assume
and, WLOG, we may assume 
 a family of more subsets;
a family of more subsets;  .
.
2b) We do not kill off a number, but in effect we have to make
Now we repeat; also introduces exactly 1 new element, and we again have the choice (assuming we went with 2b); do we want to kill off 1 (or 2) numbers (implying that
also introduces exactly 1 new element, and we again have the choice (assuming we went with 2b); do we want to kill off 1 (or 2) numbers (implying that 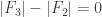 (or
(or  )), or do we want to keep every element alive which demands
)), or do we want to keep every element alive which demands  to consist of 3 sets.
to consist of 3 sets.
In general: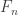 introduces exactly 1 new element. Further we can kill off
introduces exactly 1 new element. Further we can kill off  numbers, with
numbers, with  being non-negative and smaller than
being non-negative and smaller than  implying
implying 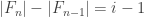
So after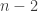 of these ‘introduce an element and kill some others’-procedures we killed, say, k of them and we may see that:
of these ‘introduce an element and kill some others’-procedures we killed, say, k of them and we may see that:
And we can no longer do anything. So should equal
should equal  .
.
Woett, if you check the earlier posts you will find that there are several constructions which give lower bounds larger than .
.
Sorry again, the parameters in my first post were all wrong. Let me start over. (Gil, feel free to delete my previous two posts):
For example, I have found the following easy construction showing that f(2,2k) is at least 3k -2. (I have not seen this posted before; sorry if I missed it):
By inductive hypothesis, f(2,2k-2) is at least 3k-5 (induction starts with the trivial statement f(2,2)=1). Let G be a graph that achieves that bound, and let uv be an edge labelled with 2k-5 in that graph. We introduce two new vertices x and y and five new edges: the cycle uxvy with edges alternating the labels 2k-4 and 2k-3, and the edge xy with label 2k-2.
Needless to say, what this construction really shows is the formula
f(2, n+2) \ge f(2,n) + 3
To prove the statement f(2,n) \ge 2n – c for a constant c it would suffice a similar argument showing that you can increase f by 2k introducing only k new vertices…
Now I see my construction was already posted by Klas in the first thread (although he stated it gives 3n/2 and I still think it gives 3n/2 -2): https://gilkalai.wordpress.com/2010/09/29/polymath-3-polynomial-hirsch-conjecture/#comment-3485
Paco, i stated 1+3(n/2-1), which simplifies to 3n/2-2
Ah, I see it now. The reason I couldn´t prove the crucial part was that it wasn´t true 🙂 Still, I feel that the idea makes sense in some way. Let me ask something;
Can anyone give me an example where it is necessary to ‘introduce’ 3 new elements?
Because if this is never a necessity, we immediately have the bound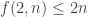 . Although this might be wishful thinking of course
. Although this might be wishful thinking of course
(To Klas) I see. sorry.
Paco, nothing to be worry about. It had been worse if there was a real disagreement 🙂
Alright, I tried to correct my post a badrillion times now, hopefully wordpress allows me this time. Corrections:
(at 2a)
(at 2b)
The following sentence:
Why? Because, unfortunately, it’s not possible to _not_ introduce a new element and it’s not necessary (for the moment I can’t make ‘it’s not necessary’ completely rigorous, but it feels so supertrue that I can’t imagine the proof of it being anything but trivial)
should become
Why? Because, unfortunately, it’s not possible to _not_ introduce a new element and it’s not necessary (for the moment I can’t make ‘it’s not necessary’ completely rigorous, but it feels so supertrue that I can’t imagine the proof of it being anything but trivial) to introduce more than 1 new element. For example, there is no reason to add, say,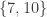 to
to  as we can just as well put that set in the first family which contains
as we can just as well put that set in the first family which contains 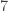 or
or 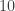
I had a thought about a statement that generalizes what we are trying to prove and that might serve as a better inductive hypothesis (if we are trying to bound and know all about
and know all about  whenever
whenever  ).
).
What I propose is that we get rid of the disjointness condition, but measure the length of the sequence differently. Let us say that is a maximality interval if there is some
is a maximality interval if there is some ![A\subset[n]](https://s0.wp.com/latex.php?latex=A%5Csubset%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) such that
such that  is maximal in
is maximal in  whenever
whenever 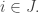 (Alternatively, in terms of the
(Alternatively, in terms of the 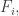 we could define it to be an interval of the form
we could define it to be an interval of the form 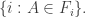 ) Now define a sequence
) Now define a sequence  to have “length” at most
to have “length” at most  if it is possible to write
if it is possible to write  as a union of at most
as a union of at most  maximality intervals. Now I’d like to conjecture (without having thought about it at all, so there might be a small counterexample, but then I’d want to modify the conjecture rather than abandon it completely) that in the multisets case this modified length is still at most the length of Nicolai’s example.
maximality intervals. Now I’d like to conjecture (without having thought about it at all, so there might be a small counterexample, but then I’d want to modify the conjecture rather than abandon it completely) that in the multisets case this modified length is still at most the length of Nicolai’s example.
This is a stronger statement, and becomes equivalent if we insist that any two maximality intervals are either the same or disjoint. The reason it might be useful is that if we construct an example with -sets, we know that the
-sets, we know that the  -shadow satisfies the convexity condition, but it doesn’t satisfy the disjointness condition. If we could nevertheless have a bound for its modified length, we would then have a much clearer idea of what we had to do with the
-shadow satisfies the convexity condition, but it doesn’t satisfy the disjointness condition. If we could nevertheless have a bound for its modified length, we would then have a much clearer idea of what we had to do with the  -sets to increase the modified length. Note that the overlapping of the maximality intervals seems very much to happen with the shadows, so this is an attempt to say something strong about them anyway.
-sets to increase the modified length. Note that the overlapping of the maximality intervals seems very much to happen with the shadows, so this is an attempt to say something strong about them anyway.
To continue this line of thought, let me discuss some extreme cases when we go from d=1 to d=2. If we want to maximize the number of maximality intervals needed when d=1, then the best we can do, writing for the interval of all
for the interval of all  such that
such that 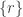 is an element (and hence a maximal element) of
is an element (and hence a maximal element) of 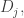 is to have intervals
is to have intervals  such that for every
such that for every  there is at least one
there is at least one  that belongs only to
that belongs only to  So in order to be as general as possible, let us assume that there are a few
So in order to be as general as possible, let us assume that there are a few  that belong to
that belong to  only, then some that belong to
only, then some that belong to  and
and 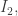 then some that belong to
then some that belong to  only, and so on.
only, and so on.
Now let’s assume that these intervals are telling us the lower shadow of a system formed by 2-multisets. How can we increase the number of intervals?
For each we find that we either have one available element of the ground set or two consecutive available elements. So the only possible multisets involve two equal or consecutive elements. So the most general thing we can do is have an interval of 11s, then a (possibly overlapping) interval of 12s, then a (possibly overlapping, but not with 11 if we want to maximize the minimum cover) interval of 22s, and so on.
we find that we either have one available element of the ground set or two consecutive available elements. So the only possible multisets involve two equal or consecutive elements. So the most general thing we can do is have an interval of 11s, then a (possibly overlapping) interval of 12s, then a (possibly overlapping, but not with 11 if we want to maximize the minimum cover) interval of 22s, and so on.
In other words, Nicolai’s example arises if we build up d and are as greedy as possible at each stage.
Now let’s go to the opposite extreme and see what happens if we can cover everything with just one interval at the d=1 stage. That is, let’s suppose that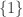 is contained in the lower shadow of every single family. Now if we want to cover with as few intervals as possible, we might as well restrict attention to sets of the form
is contained in the lower shadow of every single family. Now if we want to cover with as few intervals as possible, we might as well restrict attention to sets of the form 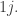 But then we clearly get a bound of
But then we clearly get a bound of 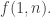
That wasn’t very interesting, so let’s try a situation where we have a large interval of families (with d=2) that use 1 but not n, then a large number that use both 1 and n, and finally a large number that use n but not 1. Can we cover with a small number of intervals?
Yes we can. Let be the interval of families that use 1 and let
be the interval of families that use 1 and let  be the interval of families that use
be the interval of families that use  By looking at the d=1 case we see that we can cover
By looking at the d=1 case we see that we can cover  with at most
with at most  maximality intervals, and the same for
maximality intervals, and the same for  But we cannot use
But we cannot use  twice (except consecutively) by the convexity condition, so we get a bound of
twice (except consecutively) by the convexity condition, so we get a bound of  which is the correct bound. Note that this situation can occur, and does occur in Terry’s example where you take the collection of all pairs with sums
which is the correct bound. Note that this situation can occur, and does occur in Terry’s example where you take the collection of all pairs with sums  Also, for what it’s worth, it’s not hard to prove that if this situation occurs then it’s actually forced to be Terry’s example.
Also, for what it’s worth, it’s not hard to prove that if this situation occurs then it’s actually forced to be Terry’s example.
I’m starting to feel as though this is a fruitful way to think about the problem. I’m going to think a little bit about what happens if the 1-shadow can be covered by three overlapping intervals but not two, and I’ll report back.
I did indeed go away and think about it, but it soon led to something not too interesting: the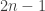 upper bound by an argument that was basically the usual elementary argument. So I cannot really claim that this is a fruitful way of thinking about the problem unless something comes out for d=3, which so far it hasn’t.
upper bound by an argument that was basically the usual elementary argument. So I cannot really claim that this is a fruitful way of thinking about the problem unless something comes out for d=3, which so far it hasn’t.
I can’t stop thinking that ; here is one bold conjecture that would imply it, and to which I have no counter example.
; here is one bold conjecture that would imply it, and to which I have no counter example.
Conjecture: if one defines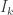 to be the interval of indices i such that k is contained in at least one of the elements of
to be the interval of indices i such that k is contained in at least one of the elements of 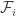 , then every
, then every ![\ell\in[m]](https://s0.wp.com/latex.php?latex=%5Cell%5Cin%5Bm%5D&bg=ffffff&fg=333333&s=0&c=20201002) is either the first element of one of this intervals, or the last element of one of this intervals.
is either the first element of one of this intervals, or the last element of one of this intervals.
Of course, since there are only n intervals one gets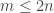 if the conjecture holds.
if the conjecture holds.
Can anyone produce a convex sequence of families such that the conjecture does not hold?
Benoit, vertices in each part. Let
vertices in each part. Let  be a sequence of edge disjoint perfect matchings in $G$.
be a sequence of edge disjoint perfect matchings in $G$.
Take a complete bipartite graph G with
The sequence of families is convex, as has been observed earlier, and they all have the same support. However they are not a maximal family for d=2.
is convex, as has been observed earlier, and they all have the same support. However they are not a maximal family for d=2.
Ok, thanks for the example, I think I now know what was wrong in my way to think about the problem.
If we’re talking about the same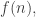 then the [EHRR] quadratic lower bound will certainly be a counterexample.
then the [EHRR] quadratic lower bound will certainly be a counterexample.
Hum, sure it will. I was not aware of this bound; I will try to have a look at [EHRR].
Maybe this bound could be included in the wiki? I feel uncomfortable writting in the wiki myself until I understand all this a bit better.
Dear all, I started a new thread of comments.
I can’t find it …