
Here is the third research thread for the polynomial Hirsch conjecture. I hope that people will feel as comfortable as possible to offer ideas about the problem we discuss. Even more important, to think about the problem either in the directions suggested by others or on their own. Participants who follow the project and think about the issues without adding remarks are valuable.
The combinatorial problem is simple to state and also everything that we know about it is rather simple. At this stage joining the project should be easy.
Let me try to describe (without attemting to be complete) one main direction that we discuss. This direction started with the very first comment we had by Nicolai.
Please do not hesitate to repeat an idea raised by yourself or by other if you think it can be useful.
Thinking about multisets (monomials).
Let 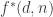

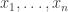
(*) for i < j < k, whenever 


 | u")
Nicolai’s conjecture:

The example that supports this conjecture consists of families with a single monomial in every family.
The monomials are




There are other examples that achieve the same bound. The bound can be achieved by families whose union include all monomials, and for such families the conjecture is correct.
The case d=3.
An upper bound by EHRR (that can be extended to monomials) following works of Barnette and Larman on polytopes is 
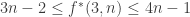
It may be the case that understanding the situation for 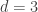
There is another example achieving the lower bound that Terry found


More examples, please…
Various approaches to the conjecture
Several approaches to the cojecture were proposed. Using clever reccurence relations, finding useful ordering, applying the method of compression, and algebraic methods. In a series of remarks Tim is trying to prove Nicolai’s conjecture. An encouraging sign is that both examples of Nicolai, Klas, and Terry come up naturally. One way to help the project at this stage would be to try to enter Tim’s mind and find ways to help him “push the car”. In any case, if Nicolai’s conjecture is correct I see no reason why it shouldn’t have a simple proof (of course we will be happy with long proofs as well).
Constructions
Something that is also on the back of our minds is the idea to find examples that are inspired from the upper bound proofs. We do not know yet what direction is going to prevail so it is useful to remember that every proof of a weaker result and every difficulty in attempts to proof the hoped-for result can give some ideas for disproving what we are trying to prove.
Some preliminary attempts were made to examine what are the properties of examples for d=3 which will come close to the 4n bound. It may also be the case that counterexamples to Nicolai’s conjecture can be found for rather small values of n and d.
Two polls:

Here are two minor observations regarding the results from EHRR
1. In the proof for the bound the recursion goes down to
the recursion goes down to 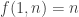 , but since we know that
, but since we know that 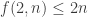 the recursion can be stopped at d=2 instead, thereby reducing the exponent slightly.
the recursion can be stopped at d=2 instead, thereby reducing the exponent slightly.
The recursion also uses instead of
instead of 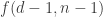 , which should also leave room for a small improvement at the cost of a messier analysis of the recursion.
, which should also leave room for a small improvement at the cost of a messier analysis of the recursion.
2. from EHRR we have both and
and 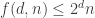 . For
. For 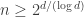 the second, linear in n, bound is better, so in order to have large growth in a construction we must use sets with d at least
the second, linear in n, bound is better, so in order to have large growth in a construction we must use sets with d at least  .
.
The quadratic lower bound from EHRR uses sets of size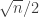 , which is quite a bit larger than the bound above.
, which is quite a bit larger than the bound above.
Klas, I suppose that for monomials you really get .
.
If you redefine the “induction on s” to be
1 Remove all multisets which do not contain s
2.Remove one copy of s from each multiset.
3.Remove empty families
then a straight forward modification of the proof should work for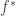 and have
and have  in the induction, rather than
in the induction, rather than 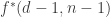 .
.
Here is another simple observation, which applies to both sets and multisets. as a layer in order to avoid having “families of families of sets” )
as a layer in order to avoid having “families of families of sets” )
(I will refer to an
Consider the problem on families such that no symbol is present in more than
such that no symbol is present in more than  layers. Denote the maximum length of such a family
layers. Denote the maximum length of such a family  . In this case we can make an induction by removing all layers which contain a given symbol s. These form a sequence of at most t layers. This gives
. In this case we can make an induction by removing all layers which contain a given symbol s. These form a sequence of at most t layers. This gives  which reduces to
which reduces to 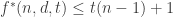
In Nicolai’s example this bound is sharp.
Pingback: Polymath3 « Euclidean Ramsey Theory
Since we have a new thread, I guess this is a good place to mention the three different ways of thinking about the problem that I have detected so far:
1) the original one: we have a ground set [n] and a number t of disjoint families F_1, … , F_t of subsets of [n] satisfying the “convexity condition”: for every i < j < k, if we take an element R of F_i and an element T of F_k then there is an element S of F_j containing the intersection of R and T.
f(n) is the maximum t for which such a “collection of families of subsets” exists. f(d,n) is the same when we restrict the F_i’s to contain only subsets of cardinality d.
2) the “labelled hypergraph” version. This is the one I prefer (i.e., the one I think I understand better). We have a “hypergraph” G on n vertices (which is nothing but a family of subsets of [n]) and label the hyperedges (the individual subsets) with positive integers. The “convexity condition” translates to: For every subset S of [n] the labels used in the “star” of S form an interval. The star of S is the sub-hypergraph consisting of hyperedges containing S. (Note: observe that G itself is the star of the empty set).
That is to say; In this form, f(n) is the “maximum number of labels that can be used in a hypergraph with n vertices so that the labels in every star form an interval”. f(d,n) is the same for d-uniform hypergraphs. E.g., d=2 is the case of (simple) graphs.
3) The “down set” version: A down-set (aka “simplicial complex”) is a family of subsets of [n] that is closed under taking subsets. In the down-set formulation we have t down-sets D_1, …, D_t, with the convexity condition being that: for every subset S of [n] the indices i such that S is in D_i form an interval. For this version to be equivalent to the previous two we need to ask for a second condition saying that “no two of the D_i share a maximal element”. But in this post Tim Gowers proposed dropping the extra condition to get a stronger version of the problem.
As usual, f(n) is that maximum t that can be obtained this way, and f(d,n) is the same when we restrict to all maximal elements in all the D_i’s to have the same cardinality d (that is to say, they are pure (d-1)-dimensional simplicial complexes).
I will not prove the (easy) equivalences, but let me at least give the translations:
1) and 2): G is the union of all F_i’s, and the labelling of each hyperedge S gives the index i for which S was in F_i
1) and 3): D_i is the down-set obtained from F_i by including all subsets of its elements
In the three versions, the subsets of [n] can be allowed to be multisets, giving rise to the functions f*(n) and f*(d,n)
At the moment I’m trying to prove Nicolai’s conjecture when d=3. Something that would be helpful would be an example (if it exists — if it doesn’t then we’re in great shape) of a “difficult” example of some families, where by “difficult” I mean that its length can’t obviously be extended and it is not of maximal length.
Let me try to explain what I mean by “can’t obviously be extended” by considering a simple example. I’ll take n=4 and I’ll start with the following collection of families: 111, 112, {122,123}, 234, 334, 344, 444. Here I’m abbreviating the singleton families by not writing the curly brackets.
Now one immediate observation is that we can remove either of the two sets from {122,123} without violating convexity, so let’s remove 123, leaving ourselves with the following system: 111,112,122,234,334,344,444. Why is removing a good idea? Because it means that if we want to add some new families, there will be fewer constraints.
Next, let us see whether we can indeed add a family or two. For instance, can we insert anything between 122 and 234? If we do, it will have to cover 2, but otherwise there are no constraints, other than negative ones — by convexity it can’t cover 11 or 44. Two possibilities are 222 and 124. In order to make life difficult (that is, less like Nicolai’s example) let us try 124, so that now the families are 111,112,122,124,234,334,344,444.
Now let me try a left-compression, but not the kind of thing I was talking about earlier. I’ll just take the opportunity to reduce elements if I can. A good place to look is at the beginnings and ends of the intervals where given elements occur. For example, the first time 4 is used is at 124, and since 3 is used in the next family we can change it to 123. So now we have 111,112,122,123,234,334,344,444. And now we can change 234 to 233, so let’s do that, giving ourselves 111,112,122,123,233,334,344,444. This allows us to insert 333: 111,112,122,123,233,333,334,344,444.
Now (partly with Nicolai’s example in the back of my mind) I see that what is causing us problems is 123. It won’t allow us to insert anything on either side: on the left we would have to include 12, and none of the options is allowed, and on the right we would have to include 23, and again none of the options is allowed (sometimes because of disjointness and sometimes because of convexity). We would prefer fewer constraints, and it seems that we will have fewer constraints if we change 123 to 223. I’m anxious about that because I’m increasing an element, but 113 and 122 are not allowed. I note that changing 123 to 222 would also work.
That last change is hard to explain in terms of some quantity decreasing, but we could argue that the more “multi” a multiset is the better, because in general it will create fewer constraints (though it will also be less help in sorting out other constraints).
In a new comment I plan to think about whether we can say anything interesting about sequences that can’t be simplified by moves of this type.
I forgot to mention that once we get to the stage I ended up at we can easily insert families until we reach Nicolai’s example.
Does anyone have a simple example of a (preferably 3-uniform) example where not all the families are singletons, and where you can’t remove a set from any non-singleton family without violating convexity. I’ve spent about fifteen minutes failing to find one. I’ll continue to try for a bit longer.
I think the example I gave here have that property
I’ve now found a simple example: 112, {113,124}, {114,123}, 134.
Come to think of it, that’s a silly example: I should have gone for 12,{13,24},{14,23},34. And of course, this kind of example is familiar from the discussion.
However, this example can be made to collapse quite easily. First change 34 to 33 so that we have 12,{13,24},{14,23},33. (Trivially this creates no new convexity constraints.) Now we can remove 14 from the third set, which yields 12,{13,24},23,33. And now we can remove 13 from the second set, which gives us 12,24,23,33. Next, we can simplify 24 to 22, so we have 12,22,23,33. And now we can insert sets to get Nicolai’s example.
It occurs to me that some of the general examples we know about will be minimal in the required sense. For example, suppose we take a sequence of disjoint Steiner triple systems. (I don’t know how easy it is to find them, but since I don’t want to attempt to prove that you can’t find them, then I am forced to consider the possibility that whatever isn’t trivially impossible does in fact exist. So I shall assume that you can keep on choosing disjoint Steiner triple systems until you run out of sets.) Since every 2-set is covered exactly once in every family, every set is needed, except possibly in the first family or the last family. But from the first and last families we can remove all sets but one without harming the convexity. And once we’ve done that, we can remove some sets from the second family and the penultimate family, provided we cover all the 2-subsets of the first set and the last set. Suppose we kept the set 123 in the first family. Then from the second family we have to keep the unique set that contains 12, the unique set that contains 23 and the unique set that contains 13. WLOG these are 124, 235, 136. (Note that we can’t add the same element twice or we would cover some pair twice.) Continuing in this way, I would expect to get fairly quickly to the stage where we were no longer throwing away sets — assuming that the growth in the number of sets kept is exponential, as seems highly plausible, we would remove sets only from the first and last
and last 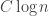 families, and having done so we would have a sequence of highly non-empty families from which it was impossible to remove any sets without violating convexity. And the sequence would have length at most n-2, which is far from maximal.
families, and having done so we would have a sequence of highly non-empty families from which it was impossible to remove any sets without violating convexity. And the sequence would have length at most n-2, which is far from maximal.
This raises two questions. First, note that if we now modify the first family so that it is not the singleton 123 but the singleton 111, then from the second family, which used to be {124,235,136}, we can afford to throw away two sets and just keep one that covers 1. Moreover, if we keep 124, say, then we can change it to 112, so that there is less that we need to keep at the next stage. We have to cover 1 and 12, so it’s enough to cover 12. So we can pick the unique set that contains 12. Let’s suppose that is 123 (after relabelling the ground set). We can change this to 122 so as to lessen the subsequent constraints.
So now our families are 111, 112, 122, followed by the old families. At this stage we are forced to keep the unique set that contains 12 again. To avoid confusion, let us call this set 127. And there seems to be nothing stopping us changing 127 to 222.
It’s clear where this is going, so actually my first question isn’t really a question any more. But my second question definitely is. Somehow the above modifications were a “cheat” because I made heavy use of the fact that none of the sets in the Steiner systems had multiple elements. This allowed me to change sets to multisets without worrying about violating the disjointness condition. So an obvious question is whether we can modify the example so that we have “Steiner systems” that partition all the multisets of size 3. If so, then these replacements will cease to be obviously possible. For example, perhaps the middle family could consist of all triples and a normal Steiner triple system. That would cover all pairs and would make it impossible to use multisets of the form
and a normal Steiner triple system. That would cover all pairs and would make it impossible to use multisets of the form  as replacements.
as replacements.
In fact, I think I can say a bit more. We could ask for each family to include all multisets for some
for some  (addition mod
(addition mod  ), taking the
), taking the 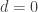 family to be right in the middle. Then the remaining (conventional) sets in each family would cover all pairs that were not of the form
family to be right in the middle. Then the remaining (conventional) sets in each family would cover all pairs that were not of the form 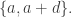
If we do that and then remove sets from early and late families until we can’t do so any more, then I think the result will be rather hard to make local adjustments to.
Let’s say you start with 111,112,122 and then other families covering 12. If you change the wlog 127 of the next family into 222,, then you will no longer have convexity for 12.
Ah yes — my mistake. In that case I don’t have a very clear idea how much an example of this type could be simplified before one got stuck.
I think we have the values of f(1),f(2),f(3) and f(4). Now I am looking at f(5) we have it is greater than or equal to 10 and less than or equal to f(4) + f(2) + f(2) -1 = 8+4+4-1=15. So it is between 10 and 15.
Assume we have an example for f(5) with 15 elements. Let us try to eliminate some cases. For f(5), as before, we can assume no F_i contains 12345.
We look at the number of quadruples used:
If there are 5 or 4 quadruples then we can use the following result:
If 12\ldots n is not used and two subsets A, B of cardinality n-1 appear in families F_i, F_j then |i-j| \leq 2, because every intermediate F_k contains A\cap B.
We thus have the quadruples are in an interval of length 3 and the two element sets are in an interval of length 5. and the single elements sets are in an interval of length 7 and the null set contains at most one more element and we are done because we have at most 8 elements which is less than 15.
So there must be at most 3 quadruplets.
I have to rewrite the last two paragraphs be cause I did not include the triples. So I hope this will work:
We thus have the quadruples are in an interval of length 3 and the triples are in an interval of length 5. and the doubles sets are in an interval of length 7 and the single sets are in an interval of length 9 and the null set contains at most one more element and we are done because we have at most 10 elements which is less than 15.
So there must be at most 3 quadruplets.
If there are three quadruples we proceed much as in the case of four or more.There will be one significant difference in that there is a triple that can intersect with a family that contains no quadruples and with a result that
contains the intersection with the three quadruples. But there is only one way this can happen so the proof used before works with modification.
We use the following result:
If 12\ldots n is not used and two subsets A, B of cardinality n-1 appear in families F_i, F_j then |i-j| \leq 2, because every intermediate F_k contains A\cap B.
We thus have the quadruples are in an interval of length 3.
Now here is where we diverge since one triple can be distance two from the quadruples while the other two can only be at distance 1 so the triples and quadruples are in an interval of length 6 not 5.
Now we can continue much as before so the double elements sets are in an interval of length 8 and the single elements are in an interval of lenght 10 and the null
set contains at most one more element and we are done because we have at most 11 elements which is less than 15.
So there must be at most 2 quadruplets.
As pointed out by Paco Santos on the first thread, more quadruples could appear but they must be contained in a length three interval.
I think I can show the following: if an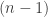 -tuple arises in a convex sequence of subsets of
-tuple arises in a convex sequence of subsets of ![[n]](https://s0.wp.com/latex.php?latex=%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) , then the sequence must have length at most
, then the sequence must have length at most  . (I mean this for every
. (I mean this for every  , not only
, not only  ). I have to leave now but will post the argument this afternoon. This means that to find
). I have to leave now but will post the argument this afternoon. This means that to find 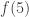 we should concentrate on sequences using sets of at most three elements.
we should concentrate on sequences using sets of at most three elements.
Here I come. I am not *totally sure* I can prove what I say in the post above this, but let me give it a try. First there is the following Lemma, which implies “length at most ”.
”.
Here comes the proof of my claim above. First a lemma:
Lemma: Suppose that a convex sequence of families of sets on![[n]](https://s0.wp.com/latex.php?latex=%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) has an
has an  containing
containing ![[n-1]](https://s0.wp.com/latex.php?latex=%5Bn-1%5D&bg=ffffff&fg=333333&s=0&c=20201002) as one of its sets. Then, for every
as one of its sets. Then, for every  in the sequence we have
in the sequence we have  .
.
Proof: Suppose wlog that . Convexity implies that
. Convexity implies that  has a set
has a set 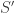 containing
containing ![S\cap [n-1]= S\setminus n](https://s0.wp.com/latex.php?latex=S%5Ccap+%5Bn-1%5D%3D+S%5Csetminus+n&bg=ffffff&fg=333333&s=0&c=20201002) . Such an
. Such an 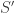 can only be obtained by either removing
can only be obtained by either removing  from
from  or adding one (or more) elements of
or adding one (or more) elements of ![[n-1]](https://s0.wp.com/latex.php?latex=%5Bn-1%5D&bg=ffffff&fg=333333&s=0&c=20201002) to
to  , or both. Repeating this we get a sequence of sets each contained in one of the families
, or both. Repeating this we get a sequence of sets each contained in one of the families  ,
,  , …,
, …,  which is increasing except at some point a decreasing step (removing
which is increasing except at some point a decreasing step (removing  ) is allowed. But convexity also implies that the “removing'' step can be taken only once in this sequence.
) is allowed. But convexity also implies that the “removing'' step can be taken only once in this sequence.
QED
Corollary: The length of such a sequence is at most .
.
Proof: By the Lemma, for every containing a non-empty set we have
containing a non-empty set we have  . Thus, all those
. Thus, all those  ‘s are within an interval of length
‘s are within an interval of length 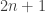 centered at
centered at  . Counting for the empty set gives
. Counting for the empty set gives  .
.
QED
Sorry about the confusion. The sentence “Here comes the proof of my claim above” should have been erased before sending the post above.
Anyway, to contiune *trying* to prove “the claim above”: From the proof of the lemma we see that the only way we can get length greater than is if on both sides of
is if on both sides of  we get subsequences that include the step “delete
we get subsequences that include the step “delete  ”. The typical shape of the sequence we get is something like the following (the example is for
”. The typical shape of the sequence we get is something like the following (the example is for  , the stars represent elements of
, the stars represent elements of ![[4]](https://s0.wp.com/latex.php?latex=%5B4%5D&bg=ffffff&fg=333333&s=0&c=20201002) and are supposed to form a unimodal sequence: increasing from the emptyset to
and are supposed to form a unimodal sequence: increasing from the emptyset to ![[4]](https://s0.wp.com/latex.php?latex=%5B4%5D&bg=ffffff&fg=333333&s=0&c=20201002) then decreasing back to a singleton.
then decreasing back to a singleton.
0
*
**
**5
***5
***
****
***
**
**5
*5
*
The goal is to show that such a shape implies not convexity with respect to (5 in this case). This looks obvious in the sequence above but it is not, The initial sequence of families may contain other sets (using 5) in each
(5 in this case). This looks obvious in the sequence above but it is not, The initial sequence of families may contain other sets (using 5) in each  and those sets could in principle restore convexity. I am pretty convinced this cannot happen but I do not have a clean argument for it…
and those sets could in principle restore convexity. I am pretty convinced this cannot happen but I do not have a clean argument for it…
In regards to Benoit Kloeckner’s comment. I have looked at my proof and it seems to work. I am showing that If there are a certain number of quadruples then eventually a large number of elements are confined in a small interval and the remaining families outside the interval will not have enough elements.
If the lemma of Santos holds then I think for the cases 13 to 15 for f(5) we need only look at triples since they are greater then 2n+2 for n=5.
I am pretty sure about the 2n+2 part. I am not so sure about the 2n that I claimed first. (That is, I am not completely sure that every sequence containing an (n-1)-tuple has length at most n).
I added some of the material from this thread to the wiki. One thing I had trouble with is this:
0
*
**
**5
***5
***
****
***
**
**5
*5
*
which I ended up omitting because when I tried to enter it there were problems with spacing.
The following example shows that f(5) is at least 11: [{}, {1}, {15}, {14, 5}, {12, 35, 4}, {13, 25, 45}, {245, 3}, {24, 34}, {234}, {23}, {2}]
Your example is very interesting Jason. Is there some structure in it that can be generalized to bigger examples? Was there a particular strategy you used to find it?
The basic strategy for the above sequence was to generate a random 2-uniform sequence of length 5, such as: [{12}, {13, 25, 34}, {14, 23, 35}, {15, 24}, {45}], then extend it as in Paco’s construction below using the 1-shadow of the families: [{1, 2}, {12}, {1, 2, 3, 4, 5}, {13, 25, 34}, {1, 2, 3, 4, 5}, {14, 23, 35}, {1, 2, 3, 4, 5}, {15, 24}, {1, 2, 4, 5}, {45}, {4, 5}]. At this point, we have a sequence of length 11, but with many repetitions, which can easily be extended to length 12 by adding the empty set family. All that is left is to remove the duplicate sets. It is a bit of trial and error. Sets that aren’t required to preserve the convex property can be removed, such as the 4 in the last family. Sets that haven’t been included yet can be added, such as 134 to the 5th family, since the 4th family contains {13, 34} and the 6th family contains {14}, which deletes {1, 3, 4} from the 5th family. Sets can also be exchanged between families in certain cases. Finally, since all that was desired was a sequence of length 11, one family can be deleted. Unfortunately I don’t yet have a general algorithm for anything after the k-shadow step.
It definitely seems like there is some structure there, but I am unsure how to generalize it. If the above example is relabeled:
[{}, {1}, {12}, {13, 2}, {15, 24, 3}, {14, 23, 25}, {235, 4}, {34, 35}, {345}, {45}, {5}]
and the f(6) example below of length 13 is relabeled, and an unnecessary set removed:
[{}, {1}, {12}, {13, 2}, {16, 25, 3}, {15, 23, 36}, {236, 5}, {26, 35}, {246, 345}, {45, 46}, {456}, {56}, {6}]
the structure appears very similar. The first and last four families are identical with some relabeling. The 5th family has the sets [{1, n}, {2, n – 1}, {3}].
I’m not sure if the f(5) example can be extended any further, there are not any sets of length 1 or 2 leftover. However, the f(6) example has three sets of length 2 leftover and one set of length 1, so it may be possible to extend at least to 14. My best effort so far is: [{}, {2}, {24}, {245}, {25, 45}, {12, 4, 5}, {14, 26, 5}, {1, 23, 34, 56}, {15, 35, 46}, {135, 6}, {13, 16}, {136}, {36}, {3}], which has one duplicate set 5. I am not sure if it will be possible to delete that set.
Thanks for the post. I tried to get some structure from your 5-elements length 5 example and had it relabeled it in the following form (this is almost opposite to your relabeling):
[{2}, {12}, {123}, {13, 23}, {234, 1}, {24, 34, 15}, {3, 14, 25},{4, 35}, {45}, {5}, {}]
In this way your example can be thought of as the gluing of the following two sequences (except the first one is not convex. The 15 in the second sequence makes the first one convex):
[{2}, {12}, {123}, {13, 23}, {234, 1}, {24, 34}, {3, 14}, {4}]
[{15}, {25}, {35}, {45}, {5}, {}]
I tried to use the downset representation combined with intervals and tackle it with the probabilistic method, but I think my approach does not work. I considered the following events:
where![s_U, e_U \in [T]](https://s0.wp.com/latex.php?latex=s_U%2C+e_U+%5Cin+%5BT%5D&bg=ffffff&fg=333333&s=0&c=20201002) are idependent equally distributed random variables.
are idependent equally distributed random variables. ![[s_U, e_U]](https://s0.wp.com/latex.php?latex=%5Bs_U%2C+e_U%5D&bg=ffffff&fg=333333&s=0&c=20201002) is the interval used in the referenced post.
is the interval used in the referenced post.
The unique maximality is covered, because at every time point a new down-set is required to start.
So ensures property (i) and
ensures property (i) and 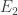 ensures (ii). I do not require
ensures (ii). I do not require  for all sets, because not all sets may be used. But a set is only considered to be active if the condition holds (thats why I check this condition in
for all sets, because not all sets may be used. But a set is only considered to be active if the condition holds (thats why I check this condition in 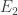 ). If a set
). If a set  is not used, you can simply set
is not used, you can simply set 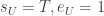 and hence it poses no restrictions for
and hence it poses no restrictions for  .
.
I think it should be clear now, that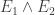 corresponds to the existence of a valid chain on
corresponds to the existence of a valid chain on  elements of length
elements of length  .
.
So we only need to show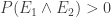 . If we can do this e.g. for
. If we can do this e.g. for 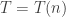 , we have shown, that
, we have shown, that  .
.
The latter inequality is equivalent to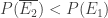 .
.
You can rather easily compute .
.
But I think even showing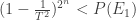 is rather impossible even for small
is rather impossible even for small  . In
. In  you have more than
you have more than 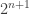 constraints of
constraints of 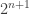 independent variables.
independent variables.
Nah anyways, maybe someone can modify it, to make it work, at least nobody else has to try out this approach anymore.
Uhh, the in the definition of
in the definition of 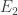 has to be a
has to be a  (GK: fixed)
(GK: fixed)
Another way that one might try to prove Nicolai’s conjecture is by adding sets to families. Indeed, we know that if we can add sets until we use all sets of size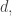 then we can prove the result — this follows from Nicolai’s observation that his conjecture is true if the families partition all the
then we can prove the result — this follows from Nicolai’s observation that his conjecture is true if the families partition all the  -sets.
-sets.
More generally, if Nicolai’s bound of is correct, then it satisfies the recurrence
is correct, then it satisfies the recurrence  for any
for any 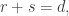 which suggests trying to prove the result by transforming the families so that all families up to some point contain a given set of size
which suggests trying to prove the result by transforming the families so that all families up to some point contain a given set of size  and all families from that point onwards contain a given set of size
and all families from that point onwards contain a given set of size 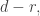 as Nicolai did (using
as Nicolai did (using  but he could have used any
but he could have used any  ) in his proof in the partitions case.
) in his proof in the partitions case.
Consider the following example:
11,12,13
22,33
23
24,34,44
The only multiset that is missing is 14, but there is no way to simply add it. So some other manipulations would also be needed besides simply adding things, if one wants to augment to a complete example.
Following the ideas of Tim, can we somehow reduce any chain of families into some standard form of the same or greater length by basic steps, where a basic step would be one of
1. Removing a (multi)set
2. Multiset-ifying a set, i.e. changing it from a (multi)set to one where elements appear with higher multiplicities
3. Some kind of left shift
Here is a more complicated 2-uniform example where no set can be removed without breaking convexity:
11
13
14,34
1A,3C,4D
1B,2C,3D,4A
1C,2D,3A,4B
2A,3B,4C
AB,AC
BC,
CC
So can we make it feasible to change something into a multi-set so that some set can be removed?
Yes, we can: change 3C into 33 and remove 2C. Then remove 2D. Remove 1C. Remove 1B, 1A, and 14 in that order. Okay, I can also remove 4C and then AC, then 4B, then 3B. Then 4A and 4D can go and I’m left with:
Now I’m left with only singletons:
11,13,34,33,3D,3A,2A,AB,BC,CC
Changing into multi-sets and removing multi-sets was enough in this case to collapse everything down to singletons, and for singleton chains the statement is easy. It would be incredible if that worked always, but what would a counter example look like?
If I do a different sequence of steps on this example, I can reduce it to an example where we can neither turn anything into a multiset nor remove any multiset. So what would be the right kind of “left-shift” to do next to the following?
11
13
14,33
1A,3C,44
1B,2C,34,4A
1C,3A,4B
AA,3B,4C
BB,AC
BC
CC
Here’s another idea for an approach, which doesn’t mean that I’m not still interested in pursuing some of the existing approaches — I definitely am.
Consider the following slight generalization of Nicolai’s argument concerning the situation where all sets in the families have size and every
and every  -set belongs to one of the families. Suppose that we are trying to get a bound for
-set belongs to one of the families. Suppose that we are trying to get a bound for 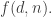 Let
Let  be a set belonging to the first family and let
be a set belonging to the first family and let  be a set belonging to the second family. Suppose that there is a set
be a set belonging to the second family. Suppose that there is a set  that does not equal either $latexs A$ or
that does not equal either $latexs A$ or  and belongs to some family
and belongs to some family  Then
Then 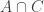 belongs to all the families up to
belongs to all the families up to  and
and  belongs to all the families from
belongs to all the families from  onwards. If
onwards. If  and
and 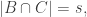 then this implies that the number of families is at most
then this implies that the number of families is at most  Since
Since  this bound, if we can always prove it, implies Nicolai’s conjecture, since his function
this bound, if we can always prove it, implies Nicolai’s conjecture, since his function  satisfies
satisfies 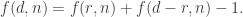
Now there is no reason whatsoever for such a to exist. Indeed, in Nicolai’s basic example (the one that looks like 111, 112, 122, 222, 223, 233, 333 etc.) it does not exist once
to exist. Indeed, in Nicolai’s basic example (the one that looks like 111, 112, 122, 222, 223, 233, 333 etc.) it does not exist once  is at all large. However, if we were content with just a polynomial bound, then we could try for something more general. For example, it would be good enough to find a chain
is at all large. However, if we were content with just a polynomial bound, then we could try for something more general. For example, it would be good enough to find a chain  such that each
such that each  belongs to one of the families,
belongs to one of the families, 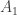 belongs to the first family,
belongs to the first family, 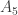 belongs to the last family, and
belongs to the last family, and  Why? Well, every family between the first family and the family containing
Why? Well, every family between the first family and the family containing 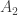 would have to contain a set that contains
would have to contain a set that contains  and restricting to such sets shows that the number of families in this interval is at most
and restricting to such sets shows that the number of families in this interval is at most 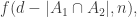 which by our assumption is at most
which by our assumption is at most  The same applies to the other intervals, so we get that the numb er of families is at most
The same applies to the other intervals, so we get that the numb er of families is at most  If that was an upper bound for
If that was an upper bound for  then solving the recurrence would give a bound of the form
then solving the recurrence would give a bound of the form  for some absolute constant
for some absolute constant 
Now Nicolai’s example shows that even finding a chain of well-intersecting sets like this is not always possible. However, if it can’t be done, then that seems to suggest that the families must be somewhat “low-width” in the sense that they don’t use too many elements of the ground set at any one time. Since even a weak bound like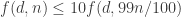 would be enough for a polynomial bound, perhaps we can push this sort of idea to show that either we have a chain of well-intersecting sets or we have low width, and in both cases we get a good recurrence.
would be enough for a polynomial bound, perhaps we can push this sort of idea to show that either we have a chain of well-intersecting sets or we have low width, and in both cases we get a good recurrence.
At the moment, I think the weakest link in the above sketch is getting a sufficiently good width statement from the absence of a chain for it to be possible to prove anything interesting. But perhaps if we also allow ourselves to add, remove and modify (multi)sets, then we can get somewhere.
I’ve just realized that for the chains we can ask for something weaker. All we need is to find sets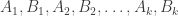 (where
(where  is some absolute constant like 5) such that
is some absolute constant like 5) such that 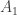 belongs to the first family,
belongs to the first family, 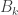 belongs to the last family,
belongs to the last family,  (or some positive absolute constant
(or some positive absolute constant  ), and
), and 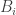 belongs to the same family as
belongs to the same family as 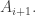 The case I was considering before was when
The case I was considering before was when 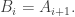
In fact, we can go weaker still. We need only that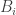 belongs to a family that is not earlier than the family that contains
belongs to a family that is not earlier than the family that contains 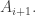 (In fact, it could even afford to be slightly earlier, but only slightly.)
(In fact, it could even afford to be slightly earlier, but only slightly.)
I’m not sure I have the time to motivate the following idea, but it came from thinking about the chains above. Roughly speaking, the problem with finding a short chain of well-intersecting sets that gets you from one end to the other is, or at least can be, that there are very few good intersections around. On the other hand, if the intersections tend to be small, then it feels as though there should be other reasons for the number of families to be small.
Those thoughts lie in the background of the following question. What happens if we generalize the definition of as follows. Define
as follows. Define 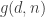 to be the maximum length of a sequence of families if no two distinct sets from the union of all the families intersect in
to be the maximum length of a sequence of families if no two distinct sets from the union of all the families intersect in  or more. If all the sets have size
or more. If all the sets have size 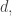 then this condition is satisfied, so
then this condition is satisfied, so  But can anything be said in the reverse direction?
But can anything be said in the reverse direction?
Ultimately, my hope here would be to study a more relaxed quantity. Given a collection of sets, we would identify a such that the
such that the  -shadow is very big, while the
-shadow is very big, while the  -shadow is very small, for some
-shadow is very small, for some  that is not much bigger than
that is not much bigger than  I need to check, but I think there is a result of Bollobás and Thomason that shows, using the Kruskal-Katona theorem, that this kind of sharp threshold happens.
I need to check, but I think there is a result of Bollobás and Thomason that shows, using the Kruskal-Katona theorem, that this kind of sharp threshold happens.
What I would hope for then is that some kind of chainy argument would work, where now is not the size of the sets but something more like the “essential supremum” of the size of the intersections of the sets.
is not the size of the sets but something more like the “essential supremum” of the size of the intersections of the sets.
Let me try to make the strategy suggested in the comment above slightly more precise, by trying to find an inductive bound for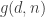 that parallels Nicolai’s bound for
that parallels Nicolai’s bound for  in the case where all
in the case where all  -sets occur. I’m not yet sure what the replacement for that condition should be, so let me just try to prove something and see what condition I need.
-sets occur. I’m not yet sure what the replacement for that condition should be, so let me just try to prove something and see what condition I need.
Take in the first family and
in the first family and  in the last family. Suppose we can find a set
in the last family. Suppose we can find a set  in one of the families such that
in one of the families such that  Then if we confine our attention to the families up to the one that contains
Then if we confine our attention to the families up to the one that contains 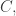 we can restrict so that all sets contain
we can restrict so that all sets contain  which means that the remainder of the intersection of any two of them has size at most
which means that the remainder of the intersection of any two of them has size at most  Similarly for the second half. So we get
Similarly for the second half. So we get 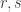 with
with  such that the number of families is at most
such that the number of families is at most 
So a sufficient condition is that the -shadow of the union of all the families contains every set of size
-shadow of the union of all the families contains every set of size  That is a very strong condition if no two intersections can be bigger than
That is a very strong condition if no two intersections can be bigger than  — it tells us we have a design of some kind — but if we are prepared to relax the bound a bit, then I think we can ask for a substantially weaker condition such as the
— it tells us we have a design of some kind — but if we are prepared to relax the bound a bit, then I think we can ask for a substantially weaker condition such as the 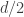 -shadow consisting of all
-shadow consisting of all 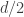 -sets. And I hope that “all” can be replaced by “almost all” in some useful sense.
-sets. And I hope that “all” can be replaced by “almost all” in some useful sense.
One final remark: I’m not quite sure what the right statement should be of the “fact” that I attributed to Bollobás and Thomason. For instance, if we take all -sets that are subsets of
-sets that are subsets of ![[n/2],](https://s0.wp.com/latex.php?latex=%5Bn%2F2%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002) then we ought really to regard it as “large in
then we ought really to regard it as “large in ![[n/2]](https://s0.wp.com/latex.php?latex=%5Bn%2F2%5D&bg=ffffff&fg=333333&s=0&c=20201002) ” rather than “small” (because it has density roughly
” rather than “small” (because it has density roughly  ). Perhaps there is some kind of regularization one can do first. Or perhaps there is some way of weighting the ground set such that almost all sets of a certain weight are covered, and almost no sets of slightly more than that weight are covered more than once.
). Perhaps there is some kind of regularization one can do first. Or perhaps there is some way of weighting the ground set such that almost all sets of a certain weight are covered, and almost no sets of slightly more than that weight are covered more than once.
No more time today, but a quick mention of something I want to pursue. Perhaps instead of looking at we could try looking at
we could try looking at  where
where  is a measure of how spread out the set system is. The easiest measure might be to add the characteristic vectors of the sets and then look at the ratio of the
is a measure of how spread out the set system is. The easiest measure might be to add the characteristic vectors of the sets and then look at the ratio of the  and
and 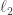 norms (and square it). Then one could try proving that either the set-up is fairly random, in which case we argue one way, or we can partition the families into subintervals where
norms (and square it). Then one could try proving that either the set-up is fairly random, in which case we argue one way, or we can partition the families into subintervals where  goes down, in which case we finish off by induction.
goes down, in which case we finish off by induction.
While getting ready to leave the house this morning I had an idea for what felt like a genuine plan of attack (in the sense of reducing the problem to proving some lemmas that all feel as though they ought to be true). So now I’m going to try to describe it, to see whether it stands up to any kind of scrutiny (partly by myself as I write, and partly by others after I write). Even if it collapses, maybe it will contain some useful observations.
First, let me set out some background philosophy that will underlie what I do. Suppose we have a sequence of families and want to replace it by a new sequence of families that is “better”, but also shorter. Suppose I have a parameter that lies between 1 and
that lies between 1 and 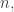 and suppose that I can replace a sequence of families with parameter
and suppose that I can replace a sequence of families with parameter  and length
and length  by a new sequence of families with parameter at most
by a new sequence of families with parameter at most  and length at least
and length at least 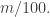 Then I am in good shape, since I can carry out this iteration at most
Then I am in good shape, since I can carry out this iteration at most 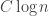 times and end up with a sequence of length at least
times and end up with a sequence of length at least  which is within a polynomial of the original length. And suppose that I can also show that if the parameter
which is within a polynomial of the original length. And suppose that I can also show that if the parameter  cannot be decreased in this way, then something else good happens. Then … er … something else good happens. This last part is rather hard to describe in the abstract, so let me try to say what I have in mind.
cannot be decreased in this way, then something else good happens. Then … er … something else good happens. This last part is rather hard to describe in the abstract, so let me try to say what I have in mind.
As a preliminary observation, let me give an argument that if each family contains just a single -set and
-set and  is small, then the bound is of the form
is small, then the bound is of the form 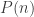 for some polynomial
for some polynomial 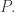 (In fact, we know that Nicolai’s bound is sharp for this situation, but I want to use a more flexible argument.) We can argue as follows. Let
(In fact, we know that Nicolai’s bound is sharp for this situation, but I want to use a more flexible argument.) We can argue as follows. Let  be the set of elements in the ground set that appear in one of the first
be the set of elements in the ground set that appear in one of the first  families (where
families (where  is the number of families) and let
is the number of families) and let  be the set of elements that appear in one of the last
be the set of elements that appear in one of the last  families. Since the middle family contains just
families. Since the middle family contains just  elements, the convexity condition implies that
elements, the convexity condition implies that  so at least one of
so at least one of  and
and  has size at most
has size at most  If
If  is at least
is at least  then this is at most
then this is at most  Therefore,
Therefore, 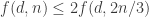 in this case. And after we iterate this a few times we get down to the case where
in this case. And after we iterate this a few times we get down to the case where 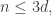 at which point we can revert to the elementary argument and get a bound of the form
at which point we can revert to the elementary argument and get a bound of the form 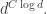 Assuming that
Assuming that  is at most
is at most 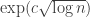 for the original
for the original 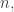 this is polynomial in
this is polynomial in 
If isn’t small, then there are other possibilities that I don’t want to go into in depth. But the kind of thing I have in mind is this. If
isn’t small, then there are other possibilities that I don’t want to go into in depth. But the kind of thing I have in mind is this. If 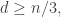 then the average intersection of two sets in any of the families will be at least
then the average intersection of two sets in any of the families will be at least  and with a bit of care one will be able to find two sets from families that are not too close together (say
and with a bit of care one will be able to find two sets from families that are not too close together (say  apart) that intersect in at least
apart) that intersect in at least 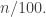 But then we can look at the interval of families between those two, all of which will contain some given set of size
But then we can look at the interval of families between those two, all of which will contain some given set of size 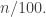 So now we will have reduced
So now we will have reduced  to at most
to at most  while still not reducing the length of the sequence too much.
while still not reducing the length of the sequence too much.
Note that as we do this second sort of reduction, the size of the ground set does not increase, and when we reduce the size of the ground set, the sizes of the sets in the families remains unchanged. So it looks to me as though we can do at most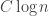 reductions before the argument finishes, which implies a polynomial bound.
reductions before the argument finishes, which implies a polynomial bound.
In a new comment I’ll try to explain how I hope to generalize this argument (so that there is some hope of proving something when the families are not singletons).
Sorry — this comment is just to say that I’m feeling less optimistic about the approach that I was about to outline. At some point I’ll try to explain it anyway.
Dear Tim, you raised quite a number of lines for attack. Which of them do you regard as most promising and you would like others to think about?
I don’t know if this leads anywhere, but maybe one could also try to bound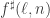 , defined as the maximal length of a convex sequence of families of subsets of [n], where each family contains at most
, defined as the maximal length of a convex sequence of families of subsets of [n], where each family contains at most  subsets. We already know that
subsets. We already know that 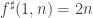 (this is denoted by
(this is denoted by  in the wiki).
in the wiki).
It seems at first that this quantity is less relevant than f(d,n), since can a priori be exponentially large in n. But it feels like a polyedron with great diameter should be more or less linear, which should imply that one could bound
can a priori be exponentially large in n. But it feels like a polyedron with great diameter should be more or less linear, which should imply that one could bound  .
.
Moreover, to attack the polynomial Hirsh conjecture one could consider the graph formulation, and by looking at each subgraph induced on the set of vertices corresponding to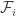 , try to make a recursion on
, try to make a recursion on 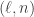 .
.
I tried to look at a linear algebra approach to Nicolai’s conjecture. I did not reach the stage of a viable idea but maybe I will try to write later about some thoughts in this direction (which are not so different, it seems from a purely combinatorial attack.)
We have a very concrete extremal combinatorial problem and a very neat suggestion for its solution: d(n-1)+1 so I would like to share you with some rather general thoughts I had regarding a possible algebraic attempt. Suppose you have a collection X of degree d monomials with a certain property, (or, what is more common, a collection of sets of size d from an n element set with a certain property P). You want to show that the size of X is at most t where you have a very clear and simple example T satisfying this property with |T|=t.
Of course, one can try to show that every maximal family with property P is a subfamily of T, or a subfamily of a family equivalent to P. We can try to give a construction that gradually takes us from X to T while keeping the property P, and we can try to find an inductive proof.
Consider a matrix M whose rows and columns are labeled by monomials of degree d
We can try to show that if we take a submatrix with rows corresponding to X and columns corresponding to T then the rows are linearly independent. Here are some possibilities.
1) Take M to be a completely generic matrix. In this case the linear algebra statement is equivalent to |X| <= |T|. So it does not seem that the algebra will give us anything.
2) Take M to be a completely generic triangular matrix. The ordering may depend on the family X. Here you rely on some order relation on the set of all monomials (or subsets). So what you are trying to prove is stronger than the inequality but it seem to express a combinatorial property related to this ordering; so the argument showing linear dependence appears to be a (unneeded) translation to linear algebra of some combinatorial property based on the ordering. In our question there all all sort of ordering (also on the variables themselves and low degree monomials related to X,) And the "convexity assumption" suggests some natural ordering and they appeared in some of the comments. Still we do not know how to use them.
3) Start from an n by n matrix L which corresponds to a linear change of variables and let M be the compound (induced) matrix for the monomials. You may take L to be a generic n by n matrix.
Here, the good news is that the linear algebra statement is really a stronger statement compared to the inequality between sizes of the sets. There is more interesting things that can be said about it.
The bad news are that I know only a handful examples where this idea leads to proofs of extremal examples, and a couple more examples where a combinatorial argument can be translated to the (stronger) linear algebra statement.
Also here sometimes taking L to be triangular (which will make M triangular) is sometimes a good idea. Also, sometimes you like the coefficients of L to be non generic to allow the linear algebra exploits some of the combinatorics.
This is sort of a general discussion. In our case, we don't talk about a family of monomials but rather about a family of families of monomials. To overcome this, when we have our favorite M we can associate to each family a generic linear combination of the rows corresponding to sets in the family and then continue to show that if we take the columns that correspond to Nicolai's example these vectors are linearly independent.
I thought about the variation that M is depending on L (so M represent a base change for the variables) and tried to make L triangular (where the ordering depends on the specific sequence of families) and somehow hoped that the convexity property will allow to show linear independence. But this did not work.
I have been playing with small examples to understand (no multiset here), and there is some irregularity in it. Namely, we have easily
(no multiset here), and there is some irregularity in it. Namely, we have easily  and
and 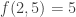 , but
, but 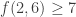 thanks to the example 12 {13 23} {14 26 35} {24 36 15} {34 16 25} {46 45} 56.
thanks to the example 12 {13 23} {14 26 35} {24 36 15} {34 16 25} {46 45} 56.
Maybe, if we are more interested in the multiset version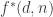 , it could worth it checking its small values further?
, it could worth it checking its small values further?
That was done here
I think case is pretty much dealt with in this remark: https://gilkalai.wordpress.com/2010/09/29/polymath-3-polynomial-hirsch-conjecture/#comment-3538
case is pretty much dealt with in this remark: https://gilkalai.wordpress.com/2010/09/29/polymath-3-polynomial-hirsch-conjecture/#comment-3538
One question which is not directly related to Nicolai’s conjecture is about methods available to show that huge graphs have small diameter. Our role model is the graph of the d-cube that has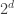 vertices and diameter d. One such method is to show an expansion property. Another possibility is that the graph has a sort of “balanced” tree structure. The question is what kind of property will the “convexity” condition on the graph lead to.
vertices and diameter d. One such method is to show an expansion property. Another possibility is that the graph has a sort of “balanced” tree structure. The question is what kind of property will the “convexity” condition on the graph lead to.
Pingback: Test Your Intuition (13): How to Play a Biased “Matching Pennies” Game « Combinatorics and more
Thinking about Tim’s approach of saying either there is a chain where
where 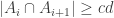 or the sequence is somehow of “low width”.
or the sequence is somehow of “low width”.
I think there is a third possibility where all families contain (almost) all elements from [n], but where sets from different families don’t have a large intersection. What can be said about the number of such families?
To make things concrete: say you want families of d-sets (not necessarily satisfying convexity), each family covers all of [n], but when you take two sets from different families, their intersection is at most some constant. What is the maximum number of families that you can get in this way?
Consider the extreme case that the constant is 1. Here we can reach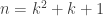 families of size
families of size 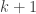 by letting each family consist of the lines through a given point in a finite projective plane with
by letting each family consist of the lines through a given point in a finite projective plane with 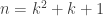 points.
points.
I don’t think it works – each line will be a member of several families.
True, this just gets the intersection and partitioning right. We have to pick a subset of the lines which form a parallel class, and then there will be only lines forming the family.
lines forming the family.
This morning I thought I had a proof of Nikolai’s conjecture that . Although I have found an error in my proof let me post it anyway to see if someone gets inspired by it.
. Although I have found an error in my proof let me post it anyway to see if someone gets inspired by it.
As a warm-up, and to set the layout for the non-proof, let me isolate the crucial property from which the Larman-EHRR recursion follows:
Lemma 1: Let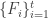 be a convex and
be a convex and  -uniform sequence of families of multisets in the alphabet
-uniform sequence of families of multisets in the alphabet ![[n]](https://s0.wp.com/latex.php?latex=%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) . Then, there is a partition of
. Then, there is a partition of  into disjoint intervals
into disjoint intervals 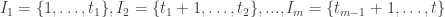 with the following properties:
with the following properties:
1) For every k, is not empty.
is not empty.
2) Each![a\in [n]](https://s0.wp.com/latex.php?latex=a%5Cin+%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) is in the support of at most two of the
is in the support of at most two of the 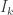 ‘s.
‘s.
3) If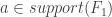 then
then  is not in the support of any
is not in the support of any 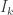 other than
other than  .
.
In parts (2) and (3) we call support of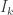 the union
the union  .
.
Proof: This is how the bound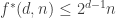 was proved in the first place. I have modified section “f(d,n)” in the wiki to explicitly include this statement. QED
was proved in the first place. I have modified section “f(d,n)” in the wiki to explicitly include this statement. QED
One thing I like about the Lemma is that it not only serves to show but also the slightly refined bound
but also the slightly refined bound  for the case where multisets are not allowed. The improvement, if not significant, has the nice feature of giving a tight bound for the case
for the case where multisets are not allowed. The improvement, if not significant, has the nice feature of giving a tight bound for the case  .
.
This “minor” improvement (and the improvement from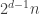 to
to  in
in 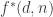 ) uses part (3) of the lemma (the idea is not mine, it was for example in the first sentence of this post by Tao). What I thought is that this part (3) could also be used to recursively prove the following more general Lemma:
) uses part (3) of the lemma (the idea is not mine, it was for example in the first sentence of this post by Tao). What I thought is that this part (3) could also be used to recursively prove the following more general Lemma:
Conjectural lemma 2: Let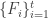 be a convex and
be a convex and  -uniform sequence of families of multisets in the alphabet
-uniform sequence of families of multisets in the alphabet ![[n]](https://s0.wp.com/latex.php?latex=%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) and let
and let  . Then, there is a partition of $latex\{1,\dots,t\}$ into disjoint intervals
. Then, there is a partition of $latex\{1,\dots,t\}$ into disjoint intervals 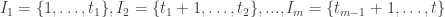 with the following properties:
with the following properties: there is a
there is a  -subset
-subset  of
of ![[n]](https://s0.wp.com/latex.php?latex=%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) in the
in the  -shadow of every
-shadow of every  in
in 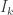 . That is,
. That is, 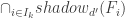 is not empty. (Remember that the
is not empty. (Remember that the  -shadow of
-shadow of  is the family of
is the family of  -tuples contained in elements of
-tuples contained in elements of  ).
).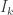 ” the support of the sequence obtained from
” the support of the sequence obtained from 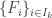 by first restricting to the subsets containing $S$ and then deleting $S$ from all of them (geometrically, the restricted support is the support of the link of
by first restricting to the subsets containing $S$ and then deleting $S$ from all of them (geometrically, the restricted support is the support of the link of  in
in 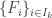 ).
).![a\in [n]](https://s0.wp.com/latex.php?latex=a%5Cin+%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) is in the restricted support of at most
is in the restricted support of at most  of the
of the 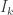 's.
's. is in the restricted support of $F_1$ then
is in the restricted support of $F_1$ then  is not in the restricted support of any
is not in the restricted support of any 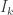 other than
other than  .
.
1) For every
Let us call “restricted support of
2) Each
3) If
From this “conjectured lemma” the bound (or a variation of it) follows easily taking .
.
Attempted proof: By induction on , the case
, the case  being the previous lemma. In the inductive step, we first partition
being the previous lemma. In the inductive step, we first partition  using the lemma, and then partition again each
using the lemma, and then partition again each 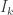 obtained using the “conjectured lemma” with
obtained using the “conjectured lemma” with  . Properties (1) and (3) carry through without problem, and for property (2) my argument was as follows:
. Properties (1) and (3) carry through without problem, and for property (2) my argument was as follows:
A certain![a\in[n]](https://s0.wp.com/latex.php?latex=a%5Cin%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) can only be in two (consecutive)
can only be in two (consecutive) 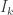 's, say
's, say 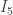 and
and 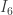 and only in
and only in  of (the restricted supports of) the finer intervals in which each of those two
of (the restricted supports of) the finer intervals in which each of those two 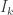 's are subdivided. But, if
's are subdivided. But, if  is indeed in both
is indeed in both 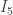 and
and 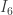 , convexity implies that it is in the restricted support of the first
, convexity implies that it is in the restricted support of the first  in
in 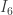 , and property (3) of the partition constructed for
, and property (3) of the partition constructed for 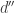 implies that
implies that  is only in one of the subintervals of
is only in one of the subintervals of 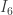 . This one plus the possible
. This one plus the possible  in
in 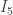 give the total of
give the total of  that we want. QED
that we want. QED
Where is my error? Since the supports are “restricted”, convexity does no longer imply what I claim in the last part.
And why do I want to restrict my supports? Because otherwise property (3) does not carry over. The common element in, say will be in all the subintervals in which we divide
will be in all the subintervals in which we divide  .
.
Any ideas?
Apart of some latex that appears as source rather than typeset, the last sentence in the non-proof of the conjectural lemma has a typo. It should read “This one plus the possible in
in 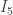 give the total of
give the total of  that we want.”
that we want.”
Let me also mention a related line of attack that I explored (unsuccessfully) the last couple of days. It also revolves about trying to make the Lemma in my post stronger so that we get a better recursion.
The “true” Lemma gives (more or less) the recursion ; but in order to get Nikolai’s bound we would like a recursion of the form
; but in order to get Nikolai’s bound we would like a recursion of the form 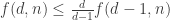 . One way to get that would be to modify the lemma so that:
. One way to get that would be to modify the lemma so that:
1) In part 1 we have partitions rather than one. Put differently, we want to have a family of intervals
partitions rather than one. Put differently, we want to have a family of intervals 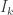 which cover
which cover ![[t]](https://s0.wp.com/latex.php?latex=%5Bt%5D&bg=ffffff&fg=333333&s=0&c=20201002) not once but
not once but  times.
times.
2) In part 2 we allow each![a\in [n]](https://s0.wp.com/latex.php?latex=a%5Cin+%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) to be in the support of
to be in the support of  of the intervals
of the intervals 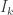 , rather than two.
, rather than two.
Part 3 would be irrelevant for this approach, as a first approximation.
Of course, I do not need to remind people that both in the “conjectural lemma” and in this other approach, having the proof for the case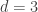 would already be great. In the “conjectural lemma”,
would already be great. In the “conjectural lemma”, 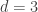 implies that only the case
implies that only the case  needs to be considered.
needs to be considered.
A small observation. I wrote before about the following padding transformation: if we have three consecutive families with the supports and two elements
and two elements  and
and  such that
such that  ,
,  ,
,  then we can add a pair
then we can add a pair  to the middle family. Just wanted to mention that Nicolai’s and Terry’s
to the middle family. Just wanted to mention that Nicolai’s and Terry’s  examples are equivalent modulo padding.
examples are equivalent modulo padding.
I was wondering if it’s possible to show that any sequence is equivalent to a sequence that has a family whose support is the entire set $\latex [n]$. That would of course imply the
sequence is equivalent to a sequence that has a family whose support is the entire set $\latex [n]$. That would of course imply the 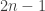 bound.
bound.
One can probably do something similar for . Say, if
. Say, if  and
and  but
but 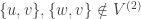 , then we can add a triple
, then we can add a triple  to the middle family.
to the middle family.
I think you will need a condition on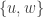 as well, in order to not add new intersections.
as well, in order to not add new intersections.
A concrete example of what Klas means is the following:
uv*
v**, u**
wv*, u**
uw*
is convex and has uv in the first family, uw in the third, none of them in the second. But you cannot add uvw in the second since uw is in the fourth. The stars may represent elements different from one another and different from u, v, w, so that they don’t interfere with convexity.
Yes, that’s right. Thanks. Have to be more careful with the stuff we add.
The observation though is that you can move from Nicolai’s example to Terry’s example by adding one set at a time even for .
.
Do you really mean “that has a family whose support is the entire set $\latex [n]$”, or rather “`that has a family containing the entire set $\latex [n]$ as one of the sets in it”? (The support of a family is the union of the sets in it).
We’re talking about the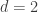 case so it’s not really possible to have the entire set
case so it’s not really possible to have the entire set ![[n]](https://s0.wp.com/latex.php?latex=%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) as an element of the family. I do mean the support.
as an element of the family. I do mean the support.
It implies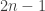 bound because such a family would have common elements both with the first and the last families. Restriction to common elements gives the bound.
bound because such a family would have common elements both with the first and the last families. Restriction to common elements gives the bound.
Thanks for the clarification. Now I see.
Pingback: Budapest, Seattle, New Haven « Combinatorics and more
I have a question, somehow related to this post by Gowers, although my motivation is (I think) different.
Suppose that we remove the condition that F_i and F_j are disjoint for all i,j and require only that F_i and F_{i+1} are. That is, we allow repeating sets but not in consecutive layers.
As an example, consider the following convex sequence on four elements and of length 10 (greater than ):
):
0
1, 2
12
1, 2
13, 24
1, 2, 3, 4
14, 23
1, 2, 3, 4
34
3, 4
My question is, does this affect significantly the functions and
and  ? It certainly does not affect
? It certainly does not affect  and
and 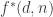 (in the uniform case, convexity implies disjoint layers).
(in the uniform case, convexity implies disjoint layers).
My impression is the functions do not change too much. More precisely, denoting the function with repetitions allowed, it seems to me that the following inequality holds:
the function with repetitions allowed, it seems to me that the following inequality holds:
The idea behind the inequality (for which I don’t have a proof) is that two sequences with (not too many) repetitions can be “merged” to one without repetitions and of about the sum of lengths. Merging a family F_i from the first sequence with a family G_j of the second means considering the family
Merging two sequences {F_1,…,F_s} and {G_1,…,G_t} means merging F_1 with as many of the G_j’s as we can (the only restriction is you take the G_j’s in their sequence order and you cannot merge F_1 with two G_j’s that have a repetition), then switching to F_2, “and so on”. For example, from the above sequence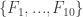 on the symbols 1234 and the same sequence
on the symbols 1234 and the same sequence  on the symbols 5678, I get the following sequence:
on the symbols 5678, I get the following sequence:
F_1*G_1
F_1*G_2
F_1*G_3
F_2*G_3
F_3*G_3
F_3*G_4
F_3*G_5
F_4*G_5
F_5*G_5
F_5*G_6
F_5*G_7
F_6*G_7
F_7*G_7
F_7*G_8
F_7*G_9
F_8*G_9
F_9*G_9
F_9*G_{10}
F_{10}*G_{10}
This sequence has no repetitions, because repetitions in the F_i’s and the G_j’s happen only for even i or j and I have been careful to (a) only merge an even i with an even j once, and (b) never merge the same i with two even j’s, or vice-versa.
[My main motivation for this question is to use merging as a tool for constructing long sequences. For example, is it easier to get quadratic examples if repetitions are allowed? If so, merging those should lead to quadratic examples without repetitions].
Let me point out that my still obeys the Kalai-Kleitman inequality
still obeys the Kalai-Kleitman inequality  , with the same proof as $f$.
, with the same proof as $f$.
Paco, won’t the inequality follow if one uses your merging construction and alternatingly increase
follow if one uses your merging construction and alternatingly increase  and
and  until the one with the smaller range reaches its maximum and then only increases the other index?
until the one with the smaller range reaches its maximum and then only increases the other index?
As I say in my post, this worfs “if F and G do not have too many repetitions”.
As a sort of stupid example, suppose the sequence F is the following sequence on eight symbols
1, 2, ab
12, a, b
1, 2, ac, bd
13, 24, a, b, c, d
1, 2, 3, 4, cd
34, c, d
and G is the same sequence, in a disjoint set of symbols. Then the longest merge I can think of is
F_1 * G_1
F_2 * G_1
F_2 * G_2
F_3 * G_2
F_3 * G_3
F_6 * G_3
F_6 * G_6
which has length seven instead of 6 + 6 -1 = 11. In the “greedy” merging, after the first four terms I cannot merge G_2 with F_4 or F_5 because I have already merged it with F_2 and F_3. I could merge F_6 * G_2 instead of F_3 * G_3, but that leads to a sequence of the same length.
… but I really don’t think that *proving* the inequality is important. I see two ways in which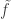 can be helpful:
can be helpful:
a) the function might be better behaved for recursion purposes (that was Tim Gowers motivation for allowing repetitions) and someone might prove that it is polynomial. In that case the only inequality we need is the obvious one .
.
b) allowing repetitions might help in the task of producing long sequences (quadratic or even worse). In that case we are only interested in showing that *those* sequences can be merged, which should be easier to prove (if true) than the general inequality. I have an idea of how to do that (I mean the “quadratic”, not the “even worse”), coming in a separate post.
I must be missing something, what goes wrong with
F_1 * G_1
F_2 * G_1
F_2 * G_2
F_3 * G_2
F_3 * G_3
F_4 * G_3
F_4 * G_4
and so on?
WordPress is eating my comments again!
Paco,
what I wanted to ask was why you could not use F_4 * G_3 in your example?
because I have already used F_2 * G_1, and I have a repeated set in F_4 from F_2 and another one in G_3 from G_1
Ah thanks, I kept on thinking about sequences with repetitions allowed on both sides in the inequality.
Here is an idea on how to use sequences with repetitions to produce new examples of sequences of quadratic length.
Start with a d uniform sequence on n elements, F_1,…,F_t. From it construct the following sequence F’_1,…, F’_{2t+1} with repetitions, of length 2t+1:
– for every i=1,…, t let F’_{2i} = F_i
– for every i=0,…,t let F’_{2i+1} =(d-1)-shadow of F_i\cup F_{i+1} (with the convention that F_0 and F_{t+1} are empty).
Remember that the k-shadow of a family F is the family of all sets of size k contained in some set of F.
The sequence F’ has the following properties:
– it is “quasi-uniform”: all sets in even-indexed families have size d and all sets in odd-indexed families have size d-1.
– it is convex.
– it has repetitions, but only in the families with an odd index.
Now let G’ be the same sequence, in a disjoint set of symbols, and merge them as in my first example (switching the role of the even and odd symbols). That is, construct the sequence:
F’_1 * G’_2
F’_2 * G’_2
F’_2 * G’_3
F’_2 * G’_4
F’_3 * G’_4
F’_4 * G’_4
F’_4 * G’_5
F’_4 * G’_6
F’_5 * G’_6
F’_6 * G’_6
…
F’_{2t} * G’_{2t}
F’_{2t+1} * G’_{2t}
This new sequence:
– has length 4t-2 and uses 2n symbols.
– is convex and has no repetitions.
– it is “quasi-uniform” again. All sets in even-indexed families have size 2d and all sets in odd-indexed families have size 2d-1.
Now comes the part where “a miracle happens”: suppose that we can turn this family into a uniform one by introducing a small number c of extra symbols. We need to add one of these symbols to each of the sets of size 2d-1, and insert some new sets of size 2d into some of the families to restore convexity. This problem has the same flavor as (in fact, it seems easier to me than) that of adding symbols to turn multisets into true sets, so I think it should be doable.
Let c be the number of extra symbols needed in the process. Then we have the recursion
f(2n + c, 2d) \ge 4 f(n,d) -2
from which a quadratic (or almost) lower bound for f(n) follows, if c is small enough I am not saying that c is a constant (although it might well be), but I would expect/hope it to be at most logarithmic.
There is a typo in my last formula. The formula I meant is, of course:
f( 2d, 2n + c) \ge 4 f(d,n) -2
Also, regarding the “miracle”: the reason why I say c should be at most logarithmic is this post by Gabor Tardos. There he claims/conjectures that multisets can be turned into sets by adding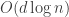 symbols, the factor $d$ coming from the fact that some sets may have O(d) repeated symbols. In my case I only need to add one symbol to each set, so I wouldn’t expect that factor to arise.
symbols, the factor $d$ coming from the fact that some sets may have O(d) repeated symbols. In my case I only need to add one symbol to each set, so I wouldn’t expect that factor to arise.
In a second reading I am not sure whether my construction is clear: I start with a honest sequence F, without repetitions. From it I construct a (non-uniform) sequence F’, now with repetitions, of essentially double length. Then merging F’ with itself I get a sequence four times longer than the original one, and again without repetitions. The only problem is that the final sequence is not uniform, while the original one needs to be uniform in order for the first step of the construction to work. The “miracle” is intended to restore uniformity.
I am not claiming that in every sequence we can restore uniformity with a logarithmic number of new symbols. That would be too much to hope since f(n/2,n) is probably much smaller than f(n). But the sequence I obtain is “quasi-uniform”: it uses sets of only two consecutive sizes.
I have a feeling that making this sequence uniform by adding a logarithmic number of extra symbols could be very difficult if not impossible. The problem is that if one wants to add the same extra symbol to the families
to the families  and
and  , one also has to add
, one also has to add  to
to  . With just one additional element and without changing the support it’s impossible – we’d need to add a set of the type
. With just one additional element and without changing the support it’s impossible – we’d need to add a set of the type  with
with  in the
in the 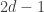 shadow of
shadow of  but all sets like that are already used up in the two surrounding families. So one’d have to do something much more creative.
but all sets like that are already used up in the two surrounding families. So one’d have to do something much more creative.
A bit more on turning multisets into sets by adding extra symbols. I understand completely how it works for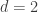 . If we add an extra symbol
. If we add an extra symbol  to
to
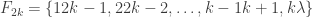
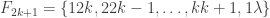




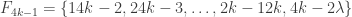
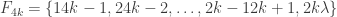


 ?
?
we can then keep it going for a long time
….
….
so that one extra symbol covers a lot of space so we only need logarithmically many. Did anyone do it for
Dear Paco, I think it will be very interesting to find even more abstract and general settings for which the recursion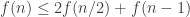 holds. Perhaps for sufficiently general setting we can indeed approach the upper bounds or at least go beyond Nicolai’s conjecture.
holds. Perhaps for sufficiently general setting we can indeed approach the upper bounds or at least go beyond Nicolai’s conjecture.
It’s a bit funny how I realized that my function satisfies the recursion. It is not obvious why is always finite; if you are allowed to repeat sets you may as well get infinite sequences. I spent some time trying to prove finiteness. The recursion is not the first proof that came to my mind, but it was the simplest.
is always finite; if you are allowed to repeat sets you may as well get infinite sequences. I spent some time trying to prove finiteness. The recursion is not the first proof that came to my mind, but it was the simplest.
I have a technical question: I want to move from threads of depth 3 to threads of depth 2. But of course I do not want the existing comments in depth 3 to disappear. Will it be ok?
I wonder if we can develop some tentative intuition at what ranges of d and n it will be “easier” to find examples wih many families. (Baring also in mind that we can change the size of the sets.) There are some extra reccurence relations when n is a constant times d, but those lose their power when n is larger.
I allways thought about n being a power of d as a useful place to think about examples. But maybe taking n to be much larger say exp (sqrt d) or exp (d/log d) is better. So maybe we should start in the first family with a few sets of small size and then as the index of the family grows have more and larger sets. Maybe this will help us gaining convexity somehow.
I think no one has mentioned the d-step theorem yet. It gives an answer to Gil’s question, although I am not completely sure whether it is a useful answer or a misleading answer. Anyway, what I call d-step theorem is:
Theorem for every d and n.
for every d and n.
Corollary If is polynomially bounded then so is
is polynomially bounded then so is  .
.
The reason why this may be misleading is that I do not see how to bound from
from 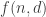 , taking into account that, as Gil says, we are allowed to use sets of different sizes in our sequences.
, taking into account that, as Gil says, we are allowed to use sets of different sizes in our sequences.
Proof of the theorem: By induction on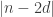 with the cases
with the cases 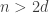 and
and  treated separately.
treated separately.
If then every d-uniform sequence on n symbols has a symbol in the common support of every
then every d-uniform sequence on n symbols has a symbol in the common support of every  , so its length is bounded by
, so its length is bounded by 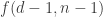 .
.
If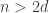 , we have to use the “wedge” operation, which works perfectly in our framework: Let
, we have to use the “wedge” operation, which works perfectly in our framework: Let 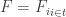 be a sequence in
be a sequence in  symbols. The wedge of F on a symbol
symbols. The wedge of F on a symbol  is the sequence, of the same length, obtained by using two elements
is the sequence, of the same length, obtained by using two elements  and
and 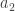 replacing
replacing  as follows:
as follows:
– each set originally not containing
originally not containing  is replaced by the two sets
is replaced by the two sets 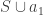 and
and  .
.
– each set originally containing
originally containing  is replaced by a single set
is replaced by a single set  . That is, the element
. That is, the element  is replaced by the pair
is replaced by the pair 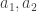 in that set.
in that set.
This operation preserves convexity, it increases by one the size of every set, and introduces no repetition, so . QED
. QED
Historical remark: the d-step theorem for polytopes was proven in 1967 by Klee and Walkup. It shows the case $n=2d$ to be the “worst one” one if we only look at uniform sequences, which is no loss of generality in the case of polytopes. The name “d step” comes from the fact that the original Hirsch conjecture, for the case n=2d, says “you can reach any vertex from any other vertex in d steps”.
In fact, you don’t need the “wedge” for the d-step theorem in our context. In the above proof, all the text between “If ” and “QED” can be changed to:
” and “QED” can be changed to:
“To see that , take any d-uniform and convex sequence of families on the symbols
, take any d-uniform and convex sequence of families on the symbols ![[n]](https://s0.wp.com/latex.php?latex=%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) and add a new symbol
and add a new symbol  to every set in every family. QED”
to every set in every family. QED”
I see two possible meanings to “Will it be OK?”, for which I have two different answers:
“Will wordpress make the change to subsequent posts respecting what is already there in previous posts?” My answer is “I don’t know, but I would hope it will”.
“Will the change be OK with you?” I tend to use nests a lot (as I tend to use parenthetical comments a lot when I write (which several coauthors of mine have criticised me for)) but I admit nests make it a bit more difficult to keep up with what others have posted. Specially nested comments put much after their parent, such as this one. And there are other ways
of referring to a previous post, such as the one I have used in the previous sentence. So, yes, the change would be OK with me.
Oh my. This post was meant to be nested to this one.
Since we like reformulations (?): The notion of convexity for a sequence of families looks “slightly more natural” under complementation. The question, in naked form, is:
Let be a family of subsets of
be a family of subsets of ![[n]](https://s0.wp.com/latex.php?latex=%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) (aka a hypergraph on
(aka a hypergraph on  vertices). I say that a map
vertices). I say that a map  is “coconvex” if for every
is “coconvex” if for every ![S \subset [n]](https://s0.wp.com/latex.php?latex=S+%5Csubset+%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) , the subsets of
, the subsets of  appearing in
appearing in  are mapped to an interval. Put differently, if
are mapped to an interval. Put differently, if  maps every induced sub-hypergraph of
maps every induced sub-hypergraph of  (in particular,
(in particular,  itself) to an interval.
itself) to an interval.
Question: how large can the image of a coconvex map on a hypergraph with vertices be?
vertices be?
Answer: the largest it can be is precisely . Proof: Consider the hypergraph of complements. That is, let
. Proof: Consider the hypergraph of complements. That is, let ![G'=\{[n]\setminus S : S \in G\}](https://s0.wp.com/latex.php?latex=G%27%3D%5C%7B%5Bn%5D%5Csetminus+S+%3A+S+%5Cin+G%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002) . Consider the “same” map
. Consider the “same” map  defined by
defined by ![F'([n]\setminus S):= F(S)](https://s0.wp.com/latex.php?latex=F%27%28%5Bn%5D%5Csetminus+S%29%3A%3D+F%28S%29&bg=ffffff&fg=333333&s=0&c=20201002) . Then, saying that
. Then, saying that  is coconvex is equivalent to saying that
is coconvex is equivalent to saying that 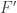 is convex. (Remark: a hypergraph with its hyperedges labelled by positive integers is the same as a sequence of hypergraphs; when I say
is convex. (Remark: a hypergraph with its hyperedges labelled by positive integers is the same as a sequence of hypergraphs; when I say 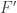 is convex I mean “the sequence of families of subsets of
is convex I mean “the sequence of families of subsets of ![[n]](https://s0.wp.com/latex.php?latex=%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) induced by
induced by 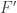 is convex”. See part 2 of this post.
is convex”. See part 2 of this post.
Exercise: Prove the d-step theorem in this complementary setting.
Paco said: “I think no one has mentioned the d-step theorem yet. It gives an answer to Gil’s question, although I am not completely sure whether it is a useful answer or a misleading answer. Anyway, what I call d-step theorem is:
Theorem for every d and n.
for every d and n.
Corollary If f(d, 2d) is polynomially bounded then so is f(d,n).
The reason why this may be misleading is that I do not see how to bound f(n) from f(n,d), taking into account that, as Gil says, we are allowed to use sets of different sizes in our sequences. ”
It is certainly useful to remember the d-step theorem that Paco quoted. Indeed a deep extension of this theorem is the basis for Paco’s counterexample for the Hirsch conjecture.
However, the point of my comment was different. When we try to make some example based on some random construction (or perhaps some geometric construction) we can still ask what is the values of d and n where this is most likely to succeed. (Once we have the construction we can then use the reduction which is rather robust to the d,2d case.)
So we can ask what are the values of d and n which it will be most “easy” to find an example where f(d,n) is large. There are reasons not to take n=Cd because it is known that , where
, where 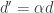 and
and  depends on C. (Unfortunately, C’ is larger than C). This suggests that it will be useful to take n to be larger than d and perhaps much larger for an example. (Indeed this is also the lesson from Paco example where we start with d=5 and n in the forties.
depends on C. (Unfortunately, C’ is larger than C). This suggests that it will be useful to take n to be larger than d and perhaps much larger for an example. (Indeed this is also the lesson from Paco example where we start with d=5 and n in the forties.
I’m trying to find an alternative proof of the bound for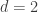 case by attempting to count the number of available edges. Denote by
case by attempting to count the number of available edges. Denote by 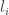 the number of elements in the support of the
the number of elements in the support of the  th set and by
th set and by 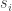 the number of unused edges connecting these elements times 2. There are three possible scenarios:
the number of unused edges connecting these elements times 2. There are three possible scenarios: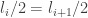 new edges so
new edges so  ;
; ;
;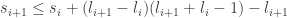 .
.
(i) on the next step the number of elements doesn’t change. Then we need at least
(b) the number of elements drops. We can assume that the elements that drop out are already connected to everything else in the support (otherwise there’s no reason for them to drop out) . Therefore the number of available edges changes in the same way
(c) finally some vertices can be added to the support in which case
If we introduce the notation we can write these inequalities as
we can write these inequalities as  . Note that
. Note that  needs to stay positive,
needs to stay positive,  has to be non-negative, and
has to be non-negative, and  . Purely arithmetic question: what’s the longest sequence subject to these conditions?
. Purely arithmetic question: what’s the longest sequence subject to these conditions?
Pingback: A New Appearance | Combinatorics and more
Using Paco’s construction above for a new sequence with repetitions from a d-uniform sequence and then fixing the repetitions by hand, I think I may have a sequence that shows that f(6) is at least 13: [{}, {1}, {15}, {13, 5}, {14, 3, 56}, {16, 34, 35}, {345, 6}, {25, 36, 45}, {236, 245}, {24, 26}, {246}, {46}, {4}]. This is the first sequence I have found that is greater than 2n, if it is correct. Do we have any other examples, perhaps for larger n, where f(n) > 2n?
Well we have the quadratic family from EHRR, which is given by an explicit construction. But I don’t think anyone has actually written down any examples based on that construction. It would be interesting to see an example from that family for d=3.
There are also the examples from the first post with length proportional to 3n
I have checked that your sequence is convex.
I’d like to propose an epsilon-baked idea which could conceivably yield an improved diameter bound. Perhaps Gil could comment on whether he’s thought in this direction before, as it is a fairly natural way to try strengthening the Kalai-Kleitman argument.
I should preface my comment with the caveat that I haven’t had time to digest all the comments so far, or to internalize the combinatorial framework, so I’m just going to talk about polyhedra.
For simplicity, let’s consider d-dimensional polyhedra with poly(d) facets. Kalai-Kleitman shows a diameter bound of exp( log^2 d ). In my interpretation, one of the log d factors is due to the depth of the recursion that decreases the dimension down to 2. The other log d factor is due to the number of steps we must take in order to reach the facet where we recurse.
There is one analysis technique which, on a few occasions, has been used successfully to handle recursive situations where the factor you pay at each level is the same as the factor you pay for recursing. The technique I’m thinking of is from Paul Seymour’s “Packing Directed Circuits Fractionally” paper. In vague terms, he gives a way to pay more before recursing, that helps offsets the cost of recursion.
If Seymour’s trick is applicable to this problem then, in the most hopeful of outcomes, it could give a diameter bound of exp( log(d) log log d ), which would certainly be interesting. It’s not immediately clear how the technique could be applied here, but there are enough superficial similarities that it seems worth a try, and one can imagine a few approaches.
In the spirit of Polymath, and since I don’t have as much time to think about this as I’d like, I thought I’d mention the idea in case others can shoot it down or become motivated to try pushing it further.
Dear Nick,
I did not think about this direction before and I am not aware of Paul Seymour’s trick from the paper you cited. More thinking about this idea or more information about Seymour’s technique will be most welcome. Paying more before recursing, in order to offset the cost of recursion could be great!
Dear Nick
Can you say a little more about Seymour trick? And perhaps the similarities you see in our case and approaches we can imagine? A little more informtion can be very helpful for others to start thinking about this idea.
A new thread have started