
So where are we? I guess we are trying all sorts of things, and perhaps we should try even more things. I find it very difficult to choose the more promising ideas, directions and comments as Tim Gowers and Terry Tao did so effectively in Polymath 1,4 and 5. Maybe this part of the moderator duty can also be outsourced. If you want to point out an idea that you find promising, even if it is your own idea, please, please do.
This post has three parts. 1) Around Nicolai’s conjecture; 1) Improving the upper bounds based on the original method; 3) How to find super-polynomial constructions?
1) Around Nicolai’s conjecture
Proving Nicolai’s conjecture
Nicolai conjectured that 
Some role models: I remember hard conjectures that were proved by amazingly simple arguments, like in Adam Marcus’s and Gabor Tardos’s proof of the Stanley-Wilf conjecture, or by an ingenious unexpected algebraic proof, like Reimer’s proof of the Butterfly lemma en route to the Van den Berg Kesten Conjecture. I don’t have the slightest idea how such proofs are found.
More general settings.
In some comments, participants offered even more general conjectures with the same bound which may allow some induction process to apply. (If somebody is willing to summarize these extensions, that would be useful.)
Do you think that there is some promising avenue to attack Nicolai’s conjecture?
Deciding the case d=3.
Not much has happened on the 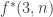
What about f(d,n)?
ERSS do not give a quadratic lower bound for f(d,n) but only such a bound up to a logarithmic factor. Can the gap between sets and multisets be bridged?
And what about f(2,n); do we know the answer there?
Disproving Nicolai’s conjecture
This is a modest challenge in the negative direction. The conjecture is appealing but the evidence for it is minimal. This should be easier than disproving PHC.
2) Improving the upper bounds based on the original method.
Remember that the recurrence relation was based on reaching the same element in sets from the first 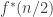
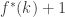
There should be some “tradeoff”: Either we can reach many elements much more quickly, or else we can say something about the structure of our families which will help us.
What will this buy us? If we replace f(n/2) by f(n/10) the effect is small, but replacing it by 
Maybe there is hope that inside the “do loop” we can cut back. We arrived at a common ‘m’ by going 

Maybe looking at the shadows of the families will help. There were a few suggestions along these lines.
What do you regard as a promising avenue for improving the arguments used in current upper bound proofs?
3) How to find super-polynomial constructions?
Well, I would take sets of small size compared to n. And we want the families to be larger as we go along, and perhaps also the sets in the families to be larger. What about taking, say, at random, in 
Jeff Kahn has (privately) a general sanity test against such careless suggestions, even if you force this convexity somehow: See if the upper bound proof gives you a much better recurrence. In any case, perhaps we should carefully check such simple ideas before we try to move to more complicated ideas for constructions? Maybe we should try to base a construction on the upper bound ideas. In some sense, ERSS constructions and even Nicolai’s simple one resemble the proof a little. But it goes only “one level”. It takes a long time to reach from both ends sets containing the same element, but then multisets containing the common ‘m’ use very few elements. What about Terry’s examples of families according to the sum of indices? (By the way, does this example extend to d>3?) Can you base families on more complicated equations of a similar nature?
Anyway, it is perhaps time to talk seriously about strategies for counterexamples.
What do you think a counterexample will look like?

Nick HArvey suggested that a certain method by Seymour will be relevant for improving the upper bound in this comment. https://gilkalai.wordpress.com/2010/10/10/polymath3-polynomial-hirsch-conjecture-3/#comment-3811
Pingback: Tweets that mention Polymath3: Polynomial Hirsch Conjecture 4 | Combinatorics and more -- Topsy.com
Pingback: Polymath3 « Euclidean Ramsey Theory
Sorry if this is an obvious question (I am a graduate student), but I was wondering why for Nicolai’s conjecture showing that f*(d,n)=d(n-1)+1 for the case when the families of monomials actually contain only one monomial each isn’t enough.
If you have a set F_1,…F_t of families of monomials satisfying the given condition then I think you can construct a set a_1,…,a_t of monomials satisfying the given condition (with a_i in F_i):
Take a_1 in F_1 and a_t in F_t arbitrarily.
Then take a_2 and a_(t-1) arbitrarily from F_2 and F_(t-1) such that they satisfy the necessary gcd property given by a_1 and a_t.
Now choose a_3 and a_(t-2) arbitrarily such that they satisfy the gcd conditions from a_2 and a_(t-1). then they automatically satisfy the gcd conditions given by a_1 and a_t.
Thus we have a_1,..,a_t satisfying the gcd property. But this can’t be longer than d(n-1)+1 (I think this has been shown for monomials but if not I think you can show it by a certain lexicographic ordering (depending on a_1,….,a_n) on the variables x_1,….x_n.).
I’m sure I must be missing something but I thought I’d be bold.
In any event thanks a lot for sharing your guys work.
Bon, it is not clear to me why a_2 will cetisfy the gcd condition for a_1 and a_3?
Bon, the reason why that does not work is that you may run out of monomials to be used in the next level because some variables have been abandoned in a previous step.
You may want to look at the following example. It does not have maximal length (Hahnle’s bound here would be 9 instead of 8) but it illustrates the point:
[{11}, {15}, {14, 55}, {12, 35, 44}, {13, 25, 45}, {24, 34}, {23}, {22}]
In the third level you need to choose between 14 and 55. The first choice means that you will not be allowed to use the variable 5 again, the second that you will not be able to use 1 again. You can check that there is no choice leading all the way to the final monomial 22.
The example has been adapted from this example by Jason Conti, but there may be simpler ones.
hum… the funny 8) was meant to be an “8” followed by a “)”…
Since we believe Nicolai’s nice conjecture, we believe that $\latex f^*(d,n) = f^*(n-1,d+1)$. Do we believe this formula has any significance or is it just a coincidence?
Certainly, the number of monomials of degree d in n variables equals the number of monomials of degree n-1 in d+1 variables. But the bijection(s) between monomials do(es) not seem to preserve convexity at all. In fact, the first problem is that in order to set up a bijection you need to order your variables, which do not come naturally ordered.
This is a very curious fact.
Regarding Bon’s question. Perhaps we can generalize Nicolai’s conjecture from disjoint families of monomials to disjoint subspaces in the vector spaces of monomials. And then maybe for the generalized question we can hope that we can always reduce the dimension of the subspaces while keeping the convexity (yet to be defined) condition.
I’ve been thinking about an approach that I’m not sure leads anywhere but for what it’s worth, here it is.
We study a function . Fix some number
. Fix some number  ,
, 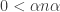 . Then there are three sub-cases:
. Then there are three sub-cases: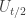 intersects both
intersects both 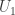 and
and 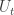 . Let $s$ be the largest index such that the intersection of
. Let $s$ be the largest index such that the intersection of 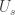 and
and 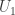 is non-empty. Note that the intersection of
is non-empty. Note that the intersection of  and
and 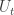 is non-empty too. Therefore,
is non-empty too. Therefore, 
(b1)
(b2)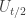 intersects one of
intersects one of 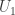 and
and 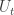 , say
, say 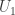 . Then
. Then  .
.
(b3)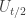 intersects neither
intersects neither 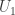 nor
nor 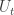 . Let $s$ be the largest index such that the intersection of
. Let $s$ be the largest index such that the intersection of 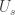 and
and 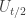 is non-empty. We can assume that
is non-empty. We can assume that  (otherwise we’ll look at the other side of the sequence). So
(otherwise we’ll look at the other side of the sequence). So
 .
.
In all cases we get some upper bound on . One obvious question I don’t have an answer for is what is a good choice of
. One obvious question I don’t have an answer for is what is a good choice of  ?
?
Sorry, a part of my comment has disappeared for some reason. I meant to consider a number (between o and 1), a sequence of length
(between o and 1), a sequence of length  and two cases:
and two cases: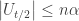 and b)
and b)  . The three sub-cases of the latter case survived in the main comment.
. The three sub-cases of the latter case survived in the main comment.
a)
In the former case, we can deduce that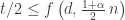 , because one of the two halves of the sequence is supported on at most
, because one of the two halves of the sequence is supported on at most  elements.
elements.
So, you get that f (d,n) is at most the maximum of the following four quantities (I use a instead of alpha to avoid latex):
a) 2 f (d, (1+a)n/2),
b1) f (d-1, n-1) + f (d-1, n-d-1),
b2) 2 f (d-1, n-d-1),
b3) f (d-1, n-d-1) + f (d, (1-a)n/2).
My only observation is that the maximum will always be either (b1) or (a): (b2) is smaller than (b1), and twice (b3) is smaller than (a) + (b2).
Upps, I forgot a factor of 2 in (b3), which gives t is at most 2f (d-1, n-d-1) + f (d, (1-a)n/2). In particular, (b2) is smaller than (b3) and the maximum lies between (a), (b1) and (b3).
Let me try to show the idea in a different setting where it might be more productive. Consider now non-uniform sequence of length on
on  elements, and let’s look at the supports
elements, and let’s look at the supports 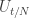 and
and  , where
, where  is some number, potentially depending on
is some number, potentially depending on  . If either of the two supports has size less than or equal to
. If either of the two supports has size less than or equal to  we can conclude that where are at most
we can conclude that where are at most 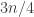 elements on one side of it, and, therefore
elements on one side of it, and, therefore 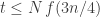 . On the other hand, if both supports have size greater than
. On the other hand, if both supports have size greater than  then they have an element in common and thus
then they have an element in common and thus 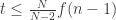 .
.
Now, if we choose to be a constant than the first estimate is polynomial and the second one is exponential which is not interesting. But what if one sets
to be a constant than the first estimate is polynomial and the second one is exponential which is not interesting. But what if one sets 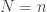 ? Then the second estimate is linear and the first one gives something like
? Then the second estimate is linear and the first one gives something like  , which is much more interesting but still nothing new. There must be a yet better choice for
, which is much more interesting but still nothing new. There must be a yet better choice for  .
.
Well, I guess not. Looks like the best choice for is
is 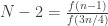 in which case we have
in which case we have  . That’s a worse estimate than what we already had.
. That’s a worse estimate than what we already had.
It’s quite easy to upgrade the inequality to . All one has to do is to look at the union of supports from
. All one has to do is to look at the union of supports from 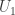 to
to 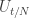 as of course was done in the original argument. So I’m not sure any extra mileage can be extracted form this whole thing.
as of course was done in the original argument. So I’m not sure any extra mileage can be extracted form this whole thing.
My general impression is that we know how to take advantage of a sequence being “thin” (case (a) in Yury’s post this morning) but we don’t know how to take advantage of it being “thick”.
One would expect that if, say, half of the elements are used all the way from t/4 to 3t/4 this fact should imply something stronger then t/2 \le f(n-1), which is implied already by a single element being used all the way from t/4 to 3t/4…
I have looked at the proof of the upper bound for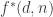 (ie Lemma 1 and Corollary 1 of Polymath3) and I had the following idea which does not quite work but may inspire others:
(ie Lemma 1 and Corollary 1 of Polymath3) and I had the following idea which does not quite work but may inspire others:
As usual, we start with a sequence of -uniform multiset families
-uniform multiset families  .
. into intervals in the following way:
into intervals in the following way: of the support of
of the support of 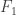 and denote by
and denote by  the interval
the interval ![[1,i_1]](https://s0.wp.com/latex.php?latex=%5B1%2Ci_1%5D&bg=ffffff&fg=333333&s=0&c=20201002) where
where 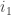 is the last index of an
is the last index of an  containing
containing  .
. in the support of
in the support of  and denote by
and denote by  the interval
the interval ![[i_1+1,i_2]](https://s0.wp.com/latex.php?latex=%5Bi_1%2B1%2Ci_2%5D&bg=ffffff&fg=333333&s=0&c=20201002) where
where 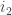 is the last index of an
is the last index of an  containing
containing  . And so on until the end.
. And so on until the end.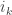 ,
, 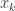 cannot appear anymore since when one element is removed from the support it cannot be added again.
cannot appear anymore since when one element is removed from the support it cannot be added again.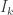 can contain at most
can contain at most  elements.
elements. for
for  by excluding
by excluding 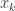 , we get a convex sequence of
, we get a convex sequence of  -uniform multiset families.
-uniform multiset families.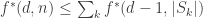 .
.
Let’s partition the sequence
We first pick a random element say
Then we pick a new element
By definition, after
This means that our sequence of intervals
Also, if we restrict the
So we have as in the original proof
Now assume that we would be able to prove that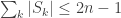 , then together with the fact that we have at most
, then together with the fact that we have at most  intervals, and using the induction hypothesis of
intervals, and using the induction hypothesis of  , then we would obtain
, then we would obtain
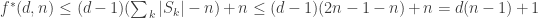 .
.
So this would give exactly the right bound, but there are two things that do not exactly work:
The first one is that this is valid only if we have exactly intervals.
intervals. which is not as easy as in the original proof since we don’t have disjointness for non-consecutive intervals.
which is not as easy as in the original proof since we don’t have disjointness for non-consecutive intervals.
The second one is that we need to prove that
But the interesting point that this illustrates is that if one can decompose the sequence into exactly intervals with the property that each interval contains at least one common element and that
intervals with the property that each interval contains at least one common element and that  , then we can prove the bound
, then we can prove the bound  . How realistic is such a construction?
. How realistic is such a construction?
Another way to formulate the above is the following: if we can always decompose the sequence![[1,t]](https://s0.wp.com/latex.php?latex=%5B1%2Ct%5D&bg=ffffff&fg=333333&s=0&c=20201002) into intervals such that
into intervals such that  and
and  then we can prove Nikolai’s conjecture (I am using here the notation of Corollary 1 of Polymath3). Note that since the intervals satisfy the condition that the
then we can prove Nikolai’s conjecture (I am using here the notation of Corollary 1 of Polymath3). Note that since the intervals satisfy the condition that the  in intervals
in intervals 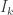 don’t contain the common element in
don’t contain the common element in 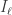 for any
for any 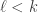 , then
, then  has to be smaller than
has to be smaller than  . So only the sum condition needs to be verified.
. So only the sum condition needs to be verified.
It seems that this is the case (on some simple examples I looked at), provided one can construct the sequence without being forced to start at one end. So in other words, we need to find a decomposition which minimizes , and on some examples this seems to be possible and yield the desired properties.
, and on some examples this seems to be possible and yield the desired properties.
I can now show that f(5) is at most 12. Since we have Conti’s example of length 11, f(5) must be 11 or 12. In fact, as a byproduct of my proof I have also found a second example of length 11: [{}, {1}, {12}, {125}, {15, 25}, {135, 245}, {145, 235}, {35, 45}, {345}, {34}, {4}].
Suppose we have a sequence of length 13 on 5 elements. Wlog the first or last level consists only of the empty set, so we have a sequence of length 12 with no empty sets. Then:
– F_1 \cup F_2 \cup F_3 already use at least three elements: if not, they form the unique sequence of length three with two elements and no empty set, namely [{1}, {12}, {2}]. But in this case the element {1} has already been abandoned in F_3, so it will not be used again. This means that F_3 … F_12 forms a convex sequence of length 10 in four elements, a contradiction.
– With the same argument, F_10 \cup F_11 \cup F_13 use at least three elements. In particular, F_3 and F_10 have a common element, say 5, so restricting F_3,…,F_10 to the sets using 5 we have a sequence of length 8 on the other four elements. So far so good, since f(4)=8.
– But this would imply that in the restriction we can assume wlog that F_3={\emptyset}. Put differently, F_3 contains the singleton {5}. Since F_3 is the first level using 5, this singleton could be deleted from F_3 without breaking convexity. This gets us back to the case where F_1\cupF_2\cup F_3 use only two elements, which we had discarded.
I forgot to mention how I got the “byproduct”. My proof gives quite some information on what a sequence of length 12 with five elements should look like. Leaving aside the level with the empty set, which we assume to be F_12:
– F_1 and F_2 use only two elements and F_2 uses both of them. That is, wlog our sequence starts either [{1}, {12}, …] or [{12}, {1}{2}, …]. In fact, if the second happens we can swap F_1 and F_2 and then remove from F_1 one of the two singletons. So, wlog [F_1,F_2] = [{1},{12}]
– Same argument for F_10 and F_11. Wlog [F_10,F_11]=[{34},{4}]
– All of F_3,…,F_9 use 5 and none of them contains the singleton {5}. That is, restricting them to 5 we have a sequence of length seven with no empty set.
One way of constructing F_3…F_9 (and maybe the only one, although I don’t have a proof) would be a sequence of length seven on four elements that starts with {12} and ends with {34}. I did not find that, but I found (more precisely, we know since some weeks ago) one of length six: [{12}, {1, 2}, {13, 24}, {14, 23}, {3, 4}, {34}]. Joining it to 5 and then adding the head and tail of length two plus the empty set gives the sequence of length 11:
[{1}, {12}, {125}, {15, 25}, {135, 245}, {145, 235}, {35, 45}, {345}, {34}, {4}, {}]
Hum, when I said “maybe the only one” I was too quick. Jason Conti’s sequence was constructed differently. Relabeling it to better match my notation his sequence is
[{1}, {12}, {125}, {15, 25}, {135, 2}, {13, 35, 24}, {5, 23, 14},{3, 45}, {34}, {4}, {}]
The head and tail are indeed as in my proof [{1}, {12}, …, {34}, {4}, {}] (in fact, the arguments in the proof imply every sequence of length more than ten can be easily modified to have precisely that head and tail).
But the restriction to 5 is different and finishes with the singleton 4: [{12}, {1,2}, {13}, {3}, {}, {4}]. Joining this to 5 and simply adding the head and tail does not give a convex sequence, because the subsequence has abandoned the element 3 and we use it again in the tail, but convexity is restored by extra sets in the central part not using 5.
What would be really nice is to use the arguments in the proof of to strengthen the recursion
to strengthen the recursion 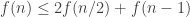 .
.
Part of the argument is that this formula overcounts the empty set not once (which gives the -1 in the wiki) but twice. That is not important asymptotically. The other part vaguely says:
The challenge is to make this vague argument more precise…
Here is some idea in this direction. Lets consider f(d,n) (or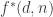 ).
).
Think about n as much larger than d. Our argument is based on reaching the same ‘m’ after maling f(d,n/2) moves from both ends. The point is that the union of all sets in the first s+1 families where s=f(d,u) is larger than u.
Suppose that we want to replace f(d,n/2) by SUM f(d-i, n/1000)
which we can replace by d f(d,n/1000). If we can do it this will decrease the
constant in the exponent n^logd. It sounds appealing. we reach n/1000 m’s then when we fix m and consider only sets containing it we reach n/1000 new m’s and we continue in all possible ways. It seems that in df(d,n/1000) we will reach many more elements of our original ground set unless there is some structure to our family that we can expolit in another way.
I tried to follow Gil’s advice and think about the properties that ensure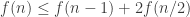 inequality, or the
inequality, or the 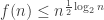 upper bound. Looking at the two proofs (the original one [see Wiki], and mine, which is more complicated but gives the upper bound a bit more explicitly) one can see that we only look at the supports of the families and therefore do not explicitly use the fact that families are disjoint (the supports aren’t). So here’s the idea:
upper bound. Looking at the two proofs (the original one [see Wiki], and mine, which is more complicated but gives the upper bound a bit more explicitly) one can see that we only look at the supports of the families and therefore do not explicitly use the fact that families are disjoint (the supports aren’t). So here’s the idea:
Let’s look at legal sequences of subsets of![[n]](https://s0.wp.com/latex.php?latex=%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) defined inductively as follows:
defined inductively as follows: elements is
elements is 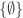 .
. elements is also a legal sequence on
elements is also a legal sequence on  elements.
elements. on
on  elements is legal if and only if
elements is legal if and only if which is legal in the former sense but not the latter)
which is legal in the former sense but not the latter) belongs to every
belongs to every  then there are subsets
then there are subsets 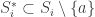 such that
such that  is a legal sequence on
is a legal sequence on  elements.
elements.
1. The only legal sequence on
2. Any legal sequence on
3. A sequence
3a) every proper subsequence is legal (there are two possible versions of this rule: the less restrictive one only requires that intervals are legal, the more restrictive – that all subsequences are. The difference can be demonstrated by the sequence
and
3b) if an element
The upper bound for the length of a legal sequence is proved by the exact same argument. The question is if it’s possible to construct a legal sequence of super-polynomial length.
upper bound for the length of a legal sequence is proved by the exact same argument. The question is if it’s possible to construct a legal sequence of super-polynomial length.
I was sure I forgot something: obviously a legal sequence must be convex.
Here’s a quadratic example in the case where only intervals are required to be legal:

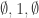
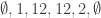
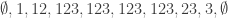

 .
.
The length of such a sequence is
The same idea works for the case when all subsequences must be legal:

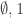

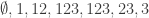

 .
.
The length is
Yuri, I am a little confused. Do you have an example (of sets) showing that f(n) is at least (n+1)(n+2)/2?
To answer Gil’s question: “Do you have an example (of sets) showing that f(n) is at least (n+1)(n+2)/2?”
The answer is “No”. What Yury has is a more general model, hence giving rise to a new function y(n) which is guaranteed to be at least as big as f(n). What Yury’s example shows is that , which does not directly say anything about f(n).
, which does not directly say anything about f(n).
But the hope is that it might be easy(-er) to analyze (and maybe find polynomial upper bounds for) y(n) than f(n), since Yury’s model is based in forgetting -at least partially- the interaction between the different elements used in each level.
I have to say I was very excited when I read his posts. At first it looked obvious to me that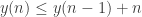 . This lasted until I tried to actually prove this inequality…
. This lasted until I tried to actually prove this inequality…
Dear Yury and Paco, I am not sure I understand what precisely is. And also why f(n) is smallet or equal than y(n). Can you explain again?
is. And also why f(n) is smallet or equal than y(n). Can you explain again?
Dear Gil,
Let me try to give a formal definition. Let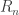 be a collection of sequences of sets
be a collection of sequences of sets 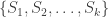 ,
, 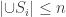 , satisfying following conditions:
, satisfying following conditions: consists of the only sequence
consists of the only sequence  .
.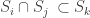 for
for 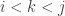
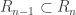 .
.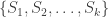 is in
is in 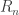 , but
, but 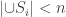 then it is also in
then it is also in  .
.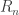 is also in
is also in 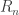 .
. common to all the sets in a sequence
common to all the sets in a sequence 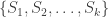 in
in 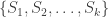 , then there must exist sets
, then there must exist sets 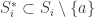 such that
such that 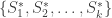 is in
is in  .
.
1.
2. Convexity:
3.
3'. If a sequence
4. Any subsequence of a sequence in
5. Induction: if there's an element
Then is defined as the maximal length of a sequence in
is defined as the maximal length of a sequence in 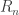 . It is at least as large as
. It is at least as large as  because given a convex sequence of families of subsets of
because given a convex sequence of families of subsets of ![[n]](https://s0.wp.com/latex.php?latex=%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) the sequence of the supports of these families is in
the sequence of the supports of these families is in 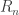 .
.
By definition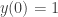 . The upper bound
. The upper bound  is obtained by the argument from the Wiki : one uses properties 3 and 4 to separate opening and closing subsequences on
is obtained by the argument from the Wiki : one uses properties 3 and 4 to separate opening and closing subsequences on  elements, then uses convexity (property 2) to show that the subsequence in the middle has a common element and then uses induction (property 5) to show that its length is bounded by
elements, then uses convexity (property 2) to show that the subsequence in the middle has a common element and then uses induction (property 5) to show that its length is bounded by  recovering the estimate
recovering the estimate 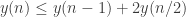 .
.
A quick question before shutting down for the evening. How does this compare to my broken example from the first thread?
1) I have been thinking about Yury’s model and I think the following is true: “there is no loss of generality in assuming that the intervals where the different elements are active are never properly nested to one another”.
The proof is as follows (please Yury, check if I understood things correctly): suppose we have two elements i and j such that i appears strictly earlier than j and disappears strictly later than j (this is what I mean by “properly nested”). Let t_j and t_i denote the last levels where i and j are used. Then it seems to me that changing i to j in all the levels from t_{j+1} to t_i still produces a valid sequence, since the restriction of it to either i or j is a subsequence (actually, an interval) of the original one restricted to i, and for the restrictions to the rest of elements we can use induction.
2) If (2) is true it means the following: there is a natural order of the elements such that they all appear and disappear according (weakly) to this order. I say weakly because two elements may appear and/or disappear at the same time.
3) Now, (2) implies a further simplification of the model. We do not need to remember the actual elements used in each level, but only the number of them. The sequences are no longer sequences of subsets of [n] but sequences of numbers. The actual subsets can be derived from the numbers.
For example, the sequences in Yury’s last example become:
[0]
[0,1]
[0,1,2,1]
[0,1,2,3,3,2,1]
[0,1,2,3,4,4,4,4,3,2,1]
What is not clear is what Yury’s axioms become in this simplified model. (In particular, it is not completely clear that my model is truly a simplification; the sequences are simpler but the definition of validity is more intricate).
Typo: where it says “2) If (2) is true…” it should say “2) If (1) is true…”
My part (3) is not completely true. In the same step some elements may appear and some others disappear from the support, and that is not detected by remembering only the cardinality of the support. Tu give a concrete example, the sequence [0,1,2,3,3,2,1] can represent Yury’s sequence on 3 elements [0, 1, 12, 123, 123, 23, 3] but it may also represent the following sequence on four elements: [0, 1, 12, 123, 234, 34, 4].
But I still believe (1) and (2) are true in Yury’s model. Put differently, I think in Yury’s model there is no loss of generality (or rather, there is no loss of length) in assuming that all the S_i’s are intervals.
This is easy to deal with. If an element disappears on the same step when an element
disappears on the same step when an element  appears in the set, we can simply add
appears in the set, we can simply add  to this set. When doing restriction by
to this set. When doing restriction by  we trim the last set down to
we trim the last set down to  and vice versa.
and vice versa.
Another observation is that if only appears together with
only appears together with  one can add
one can add  to all the sets that contain
to all the sets that contain  . That’s a slightly easier way to show that the intervals are not nested – if they are, they can actually be assumed to coincide. So if two elements appear in the sequence at the same time, they also disappear at the same time.
. That’s a slightly easier way to show that the intervals are not nested – if they are, they can actually be assumed to coincide. So if two elements appear in the sequence at the same time, they also disappear at the same time.
On a second thought, Paco’s way of getting rid of properly nested elements is better than mine because it survives restriction. The property of not having one elements appear and another one disappear in the same step also survives restriction.
That gives some hope for Paco’s proposed simplification. Validity remains convoluted though: one has to say that the sequence has height if the sum of all up-jumps is
if the sum of all up-jumps is  (that corresponds to the number of elements in the original formulation). Then we need to require that any subsequence between an up-jump and the corresponding down-jump (appearance and disappearance of an element) strictly dominate a legal sequence of height at most
(that corresponds to the number of elements in the original formulation). Then we need to require that any subsequence between an up-jump and the corresponding down-jump (appearance and disappearance of an element) strictly dominate a legal sequence of height at most  .
.
Example: height 3 sequence [0,1,2,3,3,2,1] is good because subsequences [1,2,3,3] and [2,3,3,2] strictly dominate a good 2-sequence [0,1,2,1] and subsequence [3,3,2,1] strictly dominates another good 2-sequence [1,2,1,0].
The (emerging) understanding that there is (without losing generality) some natural ordering on the elements, and perhaps also (that we may assume without losing generality) that this (weak) ordering is respected by restrictions look to me as giving hope for better upperbounds. (But I cannot explain why I think so.)
(By restrictions I mean: moving to legal sequence after we deleted a common element in a certain interval. I am not sure this is what Yuri means and I am not sure if we indeed can assume that the ordering respect restrictions.)
Gil said: “I am not sure this is what Yuri means and I am not sure if we indeed can assume that the ordering respect restrictions.” I think the answer to both parts is “yes”. Let me prove the second (only Yury can prove or disprove the first).
Let us call a valid sequence of sets (valid in the sense of Yury) *monotone* if it satisfies my additional axiom that the elements appear in order and disappear in order. Put differently, if every $S_i$ is an interval of the form $[l_i, r_i]$ and both the sequences of $l_i$’s and $r_i$’s are (weakly) monotone. Of course, implicit in the definition of monotone is a prescribed ordering of the elements.
“Respected by restrictions” means:
Lemma: If a sequence is valid and monotone, then the valid restrictions of it with respect to every element can be chosen monotone.
Proof. If the original sequence $S$ is monotone, the operation of “taking only the sets containing a certain k and removing k from them” gives a (perhaps not valid) monotone sequence, which I will denote $S/k$. The original sequence being valid means this monotone sequence $S/k$ contains a valid sequence $T$ (“contains” in the sense of Yuri’s axiom 5).
Suppose $T$ is not monotone. Then, there are indices $i<j$ such that either $j$ appears or disappears before $i$. Do the following:
– if both things happen, exchange $i$ and $j$ all throughout $T$.
– if $j$ appears before $i$, add $i$ to all the sets from the appearance of $j$ to the appearance of $i$ (or change all $j$'s to $i$'s in those sets, both operations work).
– if $j$ disappears before $i$, add $j$ to all the sets from the disappearance of $i$ to the appearance of $j$ (or change all $i$'s to $j$'s in those sets, both operations work).
All these operations preserve validity and give sequences contained in the "monotone envelope" of $T$, which means they are still contained in $S/k$. Doing them on and on will eventually lead to a monotone sequence contained in $S/k$. QED
Incidentally, in this post I stated that “monotone” was equivalent to “every $S_i$ is an interval”. That is not enough, as the sequence [2,12,23] shows. We need the extra condition that the sequences of extrema of the intervals are monotone.
This is vey interesting, Paco. As I said, having a natural ordering on the elements which is preserved under restrictions looks useful to me for improving the upper bounds. But I cannot really justify this feeling.
I found a way to transform another example of f(5) that is easy to generalize to any n (of length 2n) into the example for f(5) of length 11. I think we may be able to use a variation to generate longer sequences with larger n.
Start with the family with n symbols generated by:
F_1 = {}
F_i for 2 >= i >= 2n
* contains {j, k} for j + k = i, 1 <= j, k = i
For n = 5:
[{}, {1}, {12}, {2, 13}, {23, 14}, {3, 15, 24}, {34, 25}, {35, 4}, {45}, {5}]
Merge(8)
[{}, {1}, {12}, {2, 13}, {23, 14}, {3, 15, 24}, {34, 25}, {345}, {45}, {5}]
Add({35}, 7)
Remove({25}, 7)
[{}, {1}, {12}, {2, 13}, {23, 14}, {3, 15, 24}, {34, 35}, {345}, {45}, {5}]
Add({25}, 5)
Swap(5, 6)
[{}, {1}, {12}, {2, 13}, {3, 15, 24}, {23, 14, 25}, {34, 35}, {345}, {45}, {5}]
Insert({235, 4}, 7)
[{}, {1}, {12}, {13, 2}, {15, 24, 3}, {14, 23, 25}, {235, 4}, {34, 35}, {345}, {45}, {5}]
The reason I think this may help, is that as n gets larger, more opportunities open up to add additional families. For n = 7, the procedure above can be performed on both ends of the sequence, yielding a sequence of length 16:
[{}, {1}, {12}, {123}, {13, 23}, {134, 2}, {14, 25, 34}, {15, 24, 3}, {17, 26, 35, 4}, {37, 46, 5}, {36, 45, 47}, {457, 6}, {56, 57}, {567}, {67}, {7}]
(I still think an example of f(6) of length 14 exists, but the above procedure didn’t quite work) My hope is that this can be improved on as n gets larger, by including longer sets in the families.
Another idea, that is somewhat related, is to take a sequence with length > 2n, duplicate, mirror, replace the symbols with a disjoint set and remove the empty set family, and then joining them together with a sequence of families containing symbols from both. This is related if one considers a general form of sequences of length 2n + 1:
[{}, {1}, {12}, {13, 2}, {15, 24, 3}, {14, 23, 25}, {235, 4}, {34, 35}, {345}, {45}, {5}, {56}, … , {(n-1)n}, {n}]
Duplicate, mirror and join it with the family {n(n+1)}, and the interior families can be converted to a set of families that is similar to the initial sequence at the start of this post (using the leftover subsets), that may be possible to extend with the above operations (working on an example for f(14), but got sidetracked).
Using the example for f(5) of length 11, and just the basic family {n(n+1)}, the above will yield a sequence length of 11n/5, for n=5,10,20,40, …, which really isn’t great. Perhaps modifying the end of the first sequence, the start of the second sequence, and a clever choice of joining families that increase with n each iteration could improve it.
This comment is in reply to Yury’s explanation of the new even more abstract version which abstrat the properties of supports of our families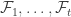 .
.
Dear Yuri, I see, this is very interesting!! I will also think about the version of Paco. This looks like it should be an easier question. (But we often had this feeling before.)
I discovered that can be larger than
can be larger than  . For
. For  there’s a sequence of length
there’s a sequence of length 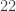 . Here it is
. Here it is



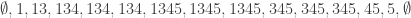


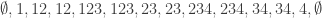 .
.
The reductions are:
1:
2:
3:
4:
2:
That’s sort of interesting since I was for some reason pretty sure that the quadratic upper bound should work. It still might but I’m not so sure anymore.
Another question (I didn’t have time to think about it) is whether it’s possible to give an upper bound for in terms of
in terms of  , where
, where  is a polynomial.
is a polynomial.
How can you have two empty sets in your sequence? This is forbidden by axiom 4, (together with 3′ and 1) unless you are using the version of axiom 4 that says “subintervals” rather than “subsequences”, as mentioned in your initial post…
Yes, that’s the version I’m using – somehow it seems more convenient, although I don’t think there’s an essential difference between the two. The upper bound appeared in the context of that version too.
upper bound appeared in the context of that version too.
I am not sure this helps, but in Yury’s model there is an analogue of d-uniform sequences: Define collections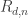 rather than
rather than 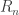 , and modify the induction axiom 5 to read something like “The restriction of a sequence in
, and modify the induction axiom 5 to read something like “The restriction of a sequence in  to any element $k$ is a sequence in
to any element $k$ is a sequence in  “. Put also the additional axiom “6. Every $S_i$ has at least d elements”. (This extra axiom may not be strictly necessary to get something sensible, but it seems natural).
“. Put also the additional axiom “6. Every $S_i$ has at least d elements”. (This extra axiom may not be strictly necessary to get something sensible, but it seems natural).
If we denote y(d,n) the maximal length of sequences in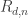 so obtained it is pretty easy to show that:
so obtained it is pretty easy to show that:
– (if d=1, no element can appear in two different S_i’s; on the other hand, the sequence [1, 2, 3, …, n] is valid).
(if d=1, no element can appear in two different S_i’s; on the other hand, the sequence [1, 2, 3, …, n] is valid).
–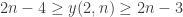 . The upper bound is as in the f(d,n) case and the lower bound follows from the sequence: [12, 123, … , 123… n-2, 123 … n-1 n, 123 … n-1 n, 3…n-1 n, … , n-2 n-1 n, n-1 n]. I think that
. The upper bound is as in the f(d,n) case and the lower bound follows from the sequence: [12, 123, … , 123… n-2, 123 … n-1 n, 123 … n-1 n, 3…n-1 n, … , n-2 n-1 n, n-1 n]. I think that  .
.
sequence so obtained it is pretty easy to show that y(1,n)=n
This looks helpful. I suppose we would like to think about strategies for proving better upper bounds for y(n) and y(d,n), perhaps even proving that y(d,n) is at most d(n-1)+1 (say) or just a similar bound for y(n) (or for similar functions extended to monomials/multisets; which we did not look at) .
It certainly looks to me that the best way to bound y(n); y(d,n) would be some clever direct combinatorial argument. (But I dont know what it will be.)
Still going back to the linear-algebraic suggestion and Nicolai’s basic example, we may think of something like that: Yury and Paco defined (reccursively) what is a d-legal sequence of an n element sets; we have an example of a d-legal sequence of subsets of {1,2,…,n} and we want to bound its length t.
(A reminder: the translation from families to such d-legal sequences is done by looking at the supports of the ith families i=1,2,…,t. Yury formulated a set of axions for these supports which still leads to the upper bound that we knew, and this setting look much more abstract and general, and Yury also showed some examples.)
We also may assume (I think this is what Paco demonstrated) and use that the ordinary ordering 1,2,…, n is compatible with the ordering of this legal sequence and all restrictions.
So we start with n variables x_1,…,x_n and consider n linear combinations of the x_i’s
called y_1,…,y_n
We consider the d(n-1)+1 special monomials in the x_i s that came from Nicolai’s example; just all monomials of degree d involving 2 consequtive variables. Lets call them N-monomials.
The claim we would like to have is this: we can chose degree d monomials , the ith supported on the variables corresponding to S_i such that expressed in terms of the N-monomials (and neglecting all other terms) we get linearly independent polynomials.
Somehow, I feel that taking the matrix transforming the x_i sto the y_j s to be triangular (w.r.t. the natural ordering of the x_i s that we talked about) will give an inductive argument for linear independence a better chance.
We had a few days of silence. Personally, I am very encouraged by the new level of abstraction that Yury considered and the subsequent observations by Yury and Paco and I hope some people are thinking about it. I plan not to wait for 100 comments on this post but rather to write this weekend a new post briefly describing these developments.
As Gil, I feel quite optimistic that Yury’s simplified model might lead to something new. One idea that comes to my mind is to try to understand the “maximal” sequences [S_1,…,S_t] valid in Yury’s context. By maximal I do not mean that $t$ is maximal (within the sequences with a given number $n$ of symbols) but rather that no element can be added to any $S_i$. Observe that inserting an element $k$ to an $S_i$ “helps” the restriction with respect to every element other than $k$ to be valid, so the only problem for insertion is the restriction to $k$ itself.
For example, some of the things Yury and I have said so far imply:
1) In a maximal valid sequence, if the symbols {1, 2,…,n} are permuted so that they appear in weak monotone order (that is, the first appearance of each $k$ happens before or at the same time as that of $k+1$) then the symbols also disappear in order. That is, every maximal sequence is “monotone” in the sense of this post (modulo permutation of the symbols). Even more so, if two elements appear at the same time in a maximal sequence then they also disappear at the same time, and vice versa.
2) In a maximal valid sequence each $S_i$ either contains or is contained in the next $S_{i+1}$. This follows from this argument of Yury.
As a corollary from (1) and (2), a maximal valid sequence can be completely recovered from the sequence of cardinalities of the $S_i$’s.
One problem with this approach is that it is not clear whether maximality is preserved by restriction. That is: can the restrictions of a maximal sequence with respect to all the elements be taken maximal? Probably not…
I find it convenient to work in the world according to Paco’s simplification where you replace a set by a single number, the cardinality of the set. That allows a geometric interpretation where instead of a sequence you consider the graph of the cardinality function , which is the cardinality of the
, which is the cardinality of the  th set of the sequence. The restriction (induction) condition means that you can nest smaller graphs inside the big one.
th set of the sequence. The restriction (induction) condition means that you can nest smaller graphs inside the big one.
It looks like it could be interesting to study symmetric graphs. For instance, my first example for

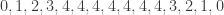 .
. .
.
in Paco’s notation would look like
All 4 restrictions could be made the same, given by the sequence
Here’s a bit more convoluted example: consider a legal sequence


 can be chosen to be either
can be chosen to be either  or its mirror image.
or its mirror image.
of height 5 and length 21 and another sequence
of height 6 and length 29. The interesting thing is that all the restrictions of
If I’m right (I haven’t fully convinced myself yet) a similar construction exists for larger heights and it improves the lower bound from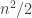 to
to  .
.
To give a bit more color: is the smallest sequence that covers
is the smallest sequence that covers  . It starts with
. It starts with  , then it grows every time
, then it grows every time  grows and stays level when
grows and stays level when  stays level or drops. The first time
stays level or drops. The first time  drops is when
drops is when  ends (that corresponds to the first element leaving the support). Then we make our descent from 5 back to 0 symmetric to ascent from 0 to 5 in the beginning of the sequence.
ends (that corresponds to the first element leaving the support). Then we make our descent from 5 back to 0 symmetric to ascent from 0 to 5 in the beginning of the sequence.
On the path of simplifying the model again and again, but keeping the proof of valid, I would propose Yury’s axiom 5 (recursion) to read simply:
valid, I would propose Yury’s axiom 5 (recursion) to read simply:
5′. Induction: if there’s an element common to all the sets in a sequence, then the length of the sequence does not exceed the maximum length of a sequence on elements.
elements.
Put differently, the interval on which a certain $k$ is active cannot be longer than $y(n-1)$.
This is even more general. Maybe this will allow an example of non polynomial length?
That might be the case, but it would be interesting. In a sense, what we are doing with these iterated generalizations/simplifications is exploring the “limit of abstraction”. What I like about the new model is it seems more suited to computer experimentation; to compute s(n+1) (if I may denote this way the function obtained with this model) you do not need to remember all the valid sequences you got for s(n), just the actual value of s(n).
It seems to allow a rather trivial superpolynomial construction. The sequence of length whose every element is
whose every element is ![[n]](https://s0.wp.com/latex.php?latex=%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) is legal. So is the sequence of length
is legal. So is the sequence of length  whose first
whose first  elements are
elements are ![[n]](https://s0.wp.com/latex.php?latex=%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) and the rest are
and the rest are ![[2n+1]](https://s0.wp.com/latex.php?latex=%5B2n%2B1%5D&bg=ffffff&fg=333333&s=0&c=20201002) . Finally by adding to this sequence
. Finally by adding to this sequence  elements of the form
elements of the form ![[2n]\setminus [n]](https://s0.wp.com/latex.php?latex=%5B2n%5D%5Csetminus+%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) we get a legal sequence on
we get a legal sequence on 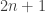 elements of length
elements of length  . Am I missing something?
. Am I missing something?
I think you are right.
At least this clarifies a point. In my attempts to prove that your y(n) is polynomial I think I have always been using your axiom 5 in my simplified form. Now I know that this could not work…
I’ve been trying to wrap my head around Yury’s proposed y(n)-abstraction. I think I understand it, but let me just write out some things that have been bothering me. In particular, given a sequence of subsets of [n], how does one check whether that sequence is valid? Let me try to write it out in some form of pseudo-code.
Input: sequence S_1, …, S_t,
Output: Yes or No
1. If U is empty (corresponding to n=0), output Yes if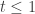 , else output No.
, else output No. . For all sequences that can be obtained by taking (not necessarily proper) subsets of
. For all sequences that can be obtained by taking (not necessarily proper) subsets of 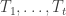 , perform the check recursively. If all of these recursive checks return No, return No.
, perform the check recursively. If all of these recursive checks return No, return No.
2. If the sequence is not convex, output No.
3. For all proper sub-sequences, perform the check recursively. If any of the recursive checks return No, return No.
4. If there is an element x common to all sets S_j, then create
5. If we reach this point, all tests have passed and we return Yes.
It seems that instead of checking all possible combinations of subsets in step 4, we can “annotate” sequences of sets by the reduction induced by each element. Then we can simply check in step 4 whether the “annotated reduced sequence” is valid. This simplifies the checks a lot.
Is it correct that those reduced sequences can be chosen to be “commutative”? What I mean by this is that it should not matter whether we do “induction” first on x, then on y, or first on y, then on x.
I was thinking whether the linear algebra approach could work for this new abstraction. It seems much more reasonable to hope that we can associate some object to each element of the sequence, and the quadratic bound makes me think of associating matrices to the sets in the sequence.
I’ve tried some approaches of associating matrices with sets in the reduced sequences, and then combining those matrices somehow to get to matrices associated with the sets in the entire sequence. I would like to then find some statement of the form: if I have a non-trivial combination of the matrices yielding 0, then the same should be true for one of the reduced sequences. I was not successful so far, perhaps because I didn’t find a good way to use convexity.
A couple quick comments:
– In point 3, I think you do not need all the sub-sequences. It seems to me it is enough to check the maximal sub-sequences containing each x, plus checking that you don’t have too many occurrences of the empty set. (Too many means: only one empty set if you take the full “sub-sequence” axiom, no two consecutive empty sets if you only take the “sub-interval” axiom).
– Concerning “Is it correct that those reduced sequences can be chosen to be “commutative”? What I mean by this is that it should not matter whether we do “induction” first on x, then on y, or first on y, then on x.” I think the answer is: If you assume commutativity you recover the original model that gives f(n). My argument: if you assume commutativity, for each subset![S\subseteq[n]](https://s0.wp.com/latex.php?latex=S%5Csubseteq%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) you can define the “active interval” of $S$ to be the interval where the sequence annotated to $S$ happens. Define then $R_i$ to be the family of maximal subsets $S$ that are active at time $i$. The $R_i$’s so obtained form a convex sequence of families of sets, except a priori some set $S$ may appear repeated in two different $R_i$’s. Now, if that happens, then the sequence annotated to that set $S$ contains the empty set two (or more) times, which is impossible (with the strong form of the sub-sequence interval).
you can define the “active interval” of $S$ to be the interval where the sequence annotated to $S$ happens. Define then $R_i$ to be the family of maximal subsets $S$ that are active at time $i$. The $R_i$’s so obtained form a convex sequence of families of sets, except a priori some set $S$ may appear repeated in two different $R_i$’s. Now, if that happens, then the sequence annotated to that set $S$ contains the empty set two (or more) times, which is impossible (with the strong form of the sub-sequence interval).
Dear Paco,
yes, I agree that far too many checks are applied in what I originally wrote.
The observation about the “commutative” is very interesting! Your argument looks good to me. Seems like commutativity bites itself with your monotonicity property though. I think one can make a valid commutative sequence monotone while keeping the commutativity, but I believe there will be conflicts if one tries to get monotonicity in the recursions. Or can these be fixed?
I was considering the following line of attack – which I am much less optimistic about now because of this conflict, but I’m going to write it down anyway.
Build a directed acyclic graph on vertices s, n, n-1, …, 2, 1, t with all possible arcs going from left to right. Assign to every set an s-t-path in this DAG in the following way. The first arc is from s to the largest element of the set. The next arc is from there to the largest element in the “recursed” set, etc., until the empty set is reached, which is indicated by an arc to t.
The nice property here is that the dimension of the space of s-t-flows is exactly the number of sets in Yury’s examples, and I was looking for ways to prove linear independence. It is clear that the same path cannot occur twice, because then we would have a way to recurse down to a sequence containing two empty sets (I am assuming the stronger formulation of all subsequences, not just subintervals). To argue that other sequences of paths are impossible I wanted to use commutativity.
The question is whether commutativity or monotonicity is the more helpful property for proofs. Strictly speaking, commutativity must be stronger if it allows to recover f(n) (which we already know to be strictly smaller than y(n), if I remember the case n=3 correctly).
You remember correctly about the $n=3$ case. We know f(3)=6, achieved by the sequence [0,1,12,123,23,3], and we know y(3)=7, achieved by the sequence [0,1,12,123,123,23,3].
This is actually a nice example of why commutativity cannot be assumed in the y model. Starting with this length seven sequence, the only valid restriction at 1 is [0,2,23,3] and the only valid restriction at 3 is [1,12,2,0]. Restricting the first at 3 gives [2,0] while restricting the second at 1 gives [0,2].
After a good sleep, I realized that my DAG idea doesn’t work in the y(n) model, even with monotone sequences. Consider the sequence [12,12,123,3], with restriction [0,2,23] at 1, [0,1,13,3] at 2, and [12,2] at 3, I would assign paths s-2-t, s-2-1-t, s-3-2-1-t, s-3-2-t, and those paths are linearly dependent.
Hello everyone,
I am afraid I can show that , which implies a super-polynomial lower bound. The exact inequalities I prove, which eventually give the one above, are:
, which implies a super-polynomial lower bound. The exact inequalities I prove, which eventually give the one above, are:
y(2n+2) \ge 2 y(n),
y(2n+4) \ge 3 y(n),
y(2n+6) \ge 4 y(n),
y(2n+8) \ge 5 y(n),
y(2n+10) \ge 6 y(n), …
… and so on.
For the first one, we simply observe that the sequence with copies of [n+1] is valid on
copies of [n+1] is valid on  elements, and use two blocks of it to show
elements, and use two blocks of it to show  . Since this “blocks” idea is crucial to the whole proof, let me formalize it a bit. I consider my set of
. Since this “blocks” idea is crucial to the whole proof, let me formalize it a bit. I consider my set of  symbols as consisting of two parts
symbols as consisting of two parts  and
and  of size
of size  , and my sequence is
, and my sequence is ![[A, A, ..., A, B, B, ...., B]](https://s0.wp.com/latex.php?latex=%5BA%2C+A%2C+...%2C+A%2C+B%2C+B%2C+....%2C+B%5D&bg=ffffff&fg=333333&s=0&c=20201002) , with a first block of
, with a first block of  ‘s of length
‘s of length  and a second block of
and a second block of  ‘s of the same length.
‘s of the same length.
Now, I increase my set of symbols by two, putting one in and one in
and one in  . Then I can construct a valid sequence with *three* blocks of length
. Then I can construct a valid sequence with *three* blocks of length  each: a first block of
each: a first block of  ‘s, a second block of
‘s, a second block of 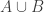 ‘s and a third block of
‘s and a third block of  ‘s.
‘s.
But if I put one more symbol to and to
and to  , so that I now have
, so that I now have 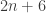 in total, I can build a valid sequence with *four* blocks of length
in total, I can build a valid sequence with *four* blocks of length  : a first block of
: a first block of  ‘s, a second and third blocks of
‘s, a second and third blocks of 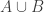 ‘s and a fourth block of
‘s and a fourth block of  ‘s.
‘s.
And so on…
Very nice!!!
nice construction!
This is quite remarkable, Paco! If I am not mistaken, this gives at least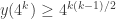 or
or 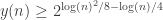 if one starts at
if one starts at 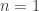 . That is quite close to the upper bound.
. That is quite close to the upper bound.
Yes; this settles the complexity of y(n) to be .
.
So I guess this means we go back to $\latex f$ and $\latex f*$, and the question is what did we learn from $\latex y$.
One thing we learnt is that we can model $f(n)$ by Yury’s axioms together with commutativity of the restrictions. Another thing is that keeping track only of the intervals when individual elements are active will not be enough to prove polynomiality of $f(n)$.
At least one thing is true. Something in the vein of my construction will not work for $f$, since the “blocks” will have a lot of fine structure inside and you cannot glue them to one another so freely.
We can maybe formulate intermidiate problems regarding the ith shaddows of our families, namely the i sets contained in sets in family i. Suppose that all sets are of size d. Abstracting the 1 shaddow is what Yury did and there we now know we cannot improve the upper bounds. We may try larger values of i between 1 and d.
Pingback: Emmanuel Abbe: Erdal Arıkan’s Polar Codes | Combinatorics and more
Pingback: Polynomial Hirsch Conjecture 5: Abstractions and Counterexamples. | Combinatorics and more
A new thread has started: https://gilkalai.wordpress.com/2010/11/28/polynomial-hirsch-conjecture-5-abstractions-and-counterexamples/
This paragraph will help the internet people for setting up new website or even a weblog from start to end.|