
This is the 5th research thread of polymath3 studying the polynomial Hirsch conjecture. As you may remember, we are mainly interested in an abstract form of the problem about families of sets. (And a related version about families of multisets.)
The 4th research thread was, in my opinion, fruitful. An interesting further abstraction was offered and for this abstraction a counterexample was found. I will review these developments below.
There are several reasons why the positive direction is more tempting than the negative one. (And as usual, it does not make much of a difference which direction you study. The practices for trying to prove a statement and trying to disprove it are quite similar.) But perhaps we should try to make also some more pointed attempts towards counterexamples?
Over the years, I devoted much effort including a few desperate attempts to try to come up with counterexamples. (For a slightly less abstract version than that of EHRR.) I tried to base one on the Towers of Hanoi game. One can translate the positions of the game into a graph labelled by subsets. But the diameter is exponential! So maybe there is a way to change the “ground set”? I did not find any. I even tried to look at games (in game stores!) where the player is required to move from one position to another to see if this leads to an interesting abstract example. These were, while romantic, very long shots.
Two more things: First, I enjoyed meeting in Lausanne for the first time Freidrich Eisenbrand, Nicolai Hahnle, and Thomas Rothvoss. (EHR of EHRR.) Second, Oliver Friedmann, Thomas Dueholm Hansen, and Uri Zwick proved (mildly) subexponential lower bounds for certain randomized pivot steps for the simplex algorithm. We discussed it in this post. The underlying polytopes in their examples are combinatorial cubes. So this has no direct bearing on our problem. (But it is interesting to see if geometric or abstract examples coming from more general games of the type they consider may be relevant.)
So let me summarize PHC4 excitements and, as usual, if I missed something please add it.
The original abstract problem
Consider t disjoint families of subsets of {1,2,…,n}, 
Suppose that
(*) For every 




The basic question is: How large can t be???
We denote the answer by 


Yuri’s abstraction
Here we want to abstract properties of sequences of sets which are the “support” of such families.
Let’s look at “legal sequences” of subsets of ![[n]](http://l.wordpress.com/latex.php?latex=%5Bn%5D&bg=ffffff&fg=000000&s=0 "[n]")
0. The only legal sequence on 

1. Any legal sequence on 

2. A legal sequence 

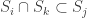
3. A sequence
3a) every proper subsequence is legal (there are two possible versions of this rule: the less restrictive one only requires that intervals are legal, the more restrictive – that all subsequences are. The difference can be demonstrated by the sequence 
and
3b) if an element 



We denote by 
Paco’s example
(Quoting from his comment.)
Hello everyone,
I am afraid I can show that  \ge n y(n)")
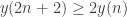




… and so on.
For the first one, we simply observe that the sequence with ")

 \ge 2y(n)")



![[A, A, ..., A, B, B, ...., B]](http://l.wordpress.com/latex.php?latex=%5BA%2C+A%2C+...%2C+A%2C+B%2C+B%2C+....%2C+B%5D&bg=ffffff&fg=000000&s=0 "[A, A, ..., A, B, B, ...., B]")
Now, I increase my set of symbols by two, putting one in 
But if I put one more symbol to 
And so on…
This gives at least  \geq 4^{k(k-1)/2}")
Commutativity(?)
Concluding this part of the discussion Paco said: “One thing we learned is that we can model
Actually, I don’t understand this commutativity so well, so I will be happy if some participants will clarify it further.
“Another thing is that keeping track only of the intervals when individual elements are active will not be enough to prove polynomiality of
Adding another parameter and abstraction for the m-shadow
Suppose we would like to abstract not the support of our families but rather the shadow on sets of size 
We would like to define legal sequences of families of sets of size 

0. The only legal sequence for n=0 is of length 1 and has the empty set as the only member of the family.
1. Any legal sequence on a ground set of
2. A legal sequence 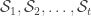
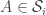
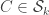


3. A sequence of families of
3a) every proper subsequence is legal
and
3b) if an element 







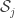
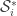
Lets denote by 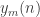

In this case we have a convex sequence of families of pairs. Let me repeat what 4b) says in this case. Suppose that 

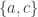
What I propose to discuss in this research thread.
1) Any ideas how to find good upper bounds for
2) What about counterexamples? Can we find superpolynomial examples for
3) Other ideas, no matter how desparate, for counterexamples?

Hello everyone.
I apologize for not following all of the discussion, so perhaps I may be saying something that is a repetition, but perhaps not. The following may be an interesting (or not) generalization of the abstraction by Eisenbrand, Hahnle, Razborov, and Rothvoss.
It is (maybe) an answer to the question: what other structure obeys the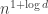 upper bound, but may provide a class of objects for which we could find a bigger lower bound? I say maybe, because it seems to be a bit unsatisfying as an answer, but perhaps you can judge:
upper bound, but may provide a class of objects for which we could find a bigger lower bound? I say maybe, because it seems to be a bit unsatisfying as an answer, but perhaps you can judge:
Fix , and let
, and let  be a connected graph. The vertices of the graph
be a connected graph. The vertices of the graph  are labeled
are labeled  . Fix a map
. Fix a map  defined on the vertices of
defined on the vertices of  to non-empty subsets of
to non-empty subsets of  -subsets of [
-subsets of [ ]. (In other words, for each
]. (In other words, for each  from 1 to
from 1 to  ,
, 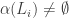 is a set of
is a set of  -element subsets.)
-element subsets.)
First, the function should satisfy the DISJOINTNESS condition. If
should satisfy the DISJOINTNESS condition. If  and
and  are different, then
are different, then 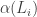 and
and  are disjoint.
are disjoint.
Second, the convexity/continuity condition. If is a subset of [
is a subset of [ ] with cardinality at most
] with cardinality at most  , define the “active set”
, define the “active set” 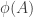 of
of  to be the set of vertices that contain a
to be the set of vertices that contain a  -subset that contains
-subset that contains  . (To be precise,
. (To be precise, 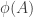 =
= 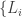 : there is a
: there is a 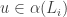 such that
such that  .) Then, the continuity condition is as follows: if
.) Then, the continuity condition is as follows: if 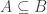 are subsets of [
are subsets of [ ] of cardinality at most
] of cardinality at most  , then $\phi(A)\superseteq\phi(B)$.
, then $\phi(A)\superseteq\phi(B)$.
Third, you need a simple condition for induction. For every of size
of size  or less, the subgraph of
or less, the subgraph of  induced by
induced by 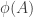 must be a connected subgraph.
must be a connected subgraph.
Question: What is the maximum possible diameter of ?
?
If is a path, this is exactly the connected layer families of Eisenbrand, Hahnle, Razborov, and Rothvoss. It also coincides with their interval evaluation definition if the $d$-element sets are cover every natural in a fixed interval (i.e., there are no gaps).
is a path, this is exactly the connected layer families of Eisenbrand, Hahnle, Razborov, and Rothvoss. It also coincides with their interval evaluation definition if the $d$-element sets are cover every natural in a fixed interval (i.e., there are no gaps).
Remark: the graphs of polyhedra are arguably presented “naturally” here.
Unless I am mistaken, the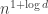 upper bound proof of in the ‘Diameters of Abstraction’ paper works essentially with no changes. But, does the ability to use any connected graph really give you much? To get more out of the diameter, you add extra vertices to
upper bound proof of in the ‘Diameters of Abstraction’ paper works essentially with no changes. But, does the ability to use any connected graph really give you much? To get more out of the diameter, you add extra vertices to  , but maybe by adding the right edges in
, but maybe by adding the right edges in  , the connectivity is easier to satisfy.
, the connectivity is easier to satisfy.
Is there some kind of balance in this family that helps satisfy all the conditions and also yields a better lower bound? I haven’t looked too far at this, but my initial answer is… so far, no.
Dear Eddie, Suppose we have a graph of diameter
of diameter  and v, w are vertices of distance t. We can consider the set of all labellings of vertices of $\Gamma$ of distance
and v, w are vertices of distance t. We can consider the set of all labellings of vertices of $\Gamma$ of distance 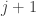 from v. This will give us t families of d-subsets. Wouldnt these families satisfy the original EHRR conditions? (If so maybe you do not describe an actual generalization of their setting?)
from v. This will give us t families of d-subsets. Wouldnt these families satisfy the original EHRR conditions? (If so maybe you do not describe an actual generalization of their setting?)
Gil, that’s right. I think nothing is gained from this (except maybe a new way to present it). Thanks!
Unless we can gain some interesting examples which are based on large graphs (perhaps very symmetric) to start with. So I think your idea Eddie can be rather useful.
(perhaps very symmetric) to start with. So I think your idea Eddie can be rather useful.
Dear Gil, I didn’t see a reply button for your post below, so I put it up here:
Yes, I didn’t necessarily mean to sound so pessimistic over my own idea. It is probably the case that some interesting can be described succinctly in this setting of arbitrary graphs due to symmetry. Perhaps the “same” connected layer family (the one obtained by the procedure you mention above) is difficult to describe.
can be described succinctly in this setting of arbitrary graphs due to symmetry. Perhaps the “same” connected layer family (the one obtained by the procedure you mention above) is difficult to describe.
But so far, it seems to me that assuming the graph is symmetric hurts more than helps. It is easier to create examples that satisfy the combinatorial convexity condition. However, it is hard to keep symmetry and have a large diameter (while minding the requirement that every vertex of
is symmetric hurts more than helps. It is easier to create examples that satisfy the combinatorial convexity condition. However, it is hard to keep symmetry and have a large diameter (while minding the requirement that every vertex of  needs to be assigned a *non-empty* collection of d-sets.
needs to be assigned a *non-empty* collection of d-sets.
For clarification, I should have said earlier that in this slightly-generalized abstraction, there are sort of two things that are vertices: the -subsets of
-subsets of ![[n]](https://s0.wp.com/latex.php?latex=%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) are the “vertices of the combinatorial polytope” and the
are the “vertices of the combinatorial polytope” and the 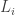 are the vertices of the graph
are the vertices of the graph  .
.
THIS is above my head. will try to go through this tomorrow
will ask isabel-kaif to study this too
thanks a lot
cheers
olga shulman lednichenko
Pingback: Tweets that mention Polynomial Hirsch Conjecture 5: Abstractions and Counterexamples. | Combinatorics and more -- Topsy.com
Pingback: A New Thread for Polymath3 « Euclidean Ramsey Theory
The questions about can be described in a simple way.
can be described in a simple way.
We have legal sequence of graphs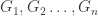 whose vertex sets are taken among {1,2,…,n}.
whose vertex sets are taken among {1,2,…,n}.
Convexity means that if a vertex or an edge appears in and
and  then it appears in
then it appears in 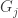 for
for  .
.
We assume that a subsequence of a legal sequence is legal and that if all graphs in a legal sequence contains vertex then we can obtain a legal sequence of graphs by replacing
then we can obtain a legal sequence of graphs by replacing  by an arbitrary subgraph
by an arbitrary subgraph 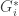 of the graph induced by $G_i$ on the neighbours of a.
of the graph induced by $G_i$ on the neighbours of a.
I believe Paco’s argument works here virtually unchanged. All one has to do is replace the set by the complete graph
by the complete graph  on the elements of
on the elements of  .
.
It looks that we need some construction where the m-shadow will be a construction like Paco’s and on top of it on top of each family which describes the m shaddow some designs a la EHRR’s construction.
(This reminds me that I still not understand the heuristic explanation why we cannot push up Paco’s example to our original problem and the related notion of commutativity.)
I updated the wiki to show that f(5) is either 11 or 12.
Many thanks, Kristal
I think that f(5) is 11 not 12. One idea I am looking at is proving that if it is 12 then there must exist a disjoint subsets of a set of smaller elements satisfying certain properties then show that this cannot happen. Possibly this may involve a computer search.
To be more specific about this get the complete list examples for n=4 of size 7 or 8 then use this to prove that f(5) cannot be 12.
I have been thinking since I wrote this and I am wondering if I could just get a get a complete list of maximal examples for f(4) and then try to use that to show that f(5) is 11..
f(4)=8, I know of at least 2 examples that are of size 8, I don’t know if there are more.
I think I can show that if I have a sequence of length 12 on 5 elements there is a subsequence containing element 5 that is either of length 8, of length 5 but not containing the set containing only the element 5 so that it is a sequence of
length 8 with one element at the end removed, or of length 7 but having one family not at either end consisting only of the set containing only the element 5. The proof is based on methods used to show that the maximal length of a set on 5 elements is at most 12.
Suppose we have a sequence of length 12 on 5 elements. Wlog the first or last level consists only of the empty set, so we have a sequence of length 11 with no empty sets. Then:- F_1 \cup F_2 \cup F_3 already use at least three elements: if not, they form the unique sequence of length three with two elements and no empty set, namely [{1}, {12}, {2}]. But in this case the element {1} has already been abandoned in F_3, so it will not be used again. This means that F_3 … F_12 forms a convex sequence of length 9 in four elements, a contradiction.
With the same argument, F_9 \cup F_10 \cup F_11 use at least three elements. In particular, F_3 and F_9 have a common element, say 5, so restricting F_3,…,F_10
to the sets using 5 we have a sequence of at least length 7 on the other four elements.
Now if the sets using 5 form a sequence of 8 elements then we are done. If not if there are only 7 elements look where the set containing 5 is. If it is not in the set then we can add a null set to the end and get a sequence of length 8 and
this is sufficient for our purposes because we again are dealing with maximal sequences on 4 elements.
Now if the set containing only the element 5 is in the sequence with any other set containing the element 5 we can delete it and the above argument applies.
If the the set containing only the element 5 is at the end of the sequence then we can delete it as it cannot be the only set in that family as then the sequence
would have less than 12 elements. So it can be deleted and we start the whole process over again and we repeat until we cannot go on. The only obstacle that complicates the process is if the element containing only the element 5 is not at
either of the ends of the subsequence containing element 5, In this case we have only a small number of cases.
I can show more assume F_1 \cup F_2 or F_9 \cup F_10 have three or more elements then since F_1 \cup F_2 \cup F_3 and F_9 \cup F_10 \cup F_11 both contain a family with three or more elements then we have a subsequence containing a common element say 5 of length 8 but then it must contain a family containing a set containing the element 5 and nothing else and no other set containing the element 5 if this family has more than one element then the entire sequence is less than 12 and we are done, if the this family contains other elements then we can delete the singleton element 5 and then we can start over and keep deleting these elements and process will eventually end because we have only 5 singleton elements and we will get rid of all examples of this type.
I have been looking at the various cases using the method outlined above. And it looks like all the cases work and f(5) is 11. Let me start going through the cases. It may take a while to work through all of them.
Suppose we have a counterexample that under restriction to sets containing the element 5 contains a set of length 7
which does not contain the set containing only the element 5 but contains a set which under restriction contains all 4 elements then we know that the original set must contain a set which contains all the elements and hence has length 10. So
we can eliminate this case.
For the next case assume that in the restriction to sets containing the the element 5 we don’t have a set with four elements and the element 5 and we don’t
have a set containing the element 5 only and we have three sets containing the element 5 and three other elements. We note 3 or more sets of three elements and the element 5 contains all combinations of two elements and the element 5.
Now the first family and the second family must contain a set containing at least a pair of elements. If not there are only single elements in the first two elements. Then one element will only appear in one single set which cause the entire case to have at most 9 families and we are done. And the last and the second to last family must also contain a set containing a pair of elements by similar reasoning.
And since all pairs are contained in the three sets containing three or more elements and the element 5 the pairs mentioned at the second and first families and those at the other end must be in the sets of three and the element 5. And this means that the third and third to last families must contain sets containing three or more elements. Now if either of these families doesn’t contain the element 5 then they will contain a common element and then we continue this proof with that element replacing the element 5. If it is a previous case we use the previous proof and if it one the cases to come we will deal with it then.
Next we note that the three sets of three elements and the element 5 must lie within three consecutive positions or else the extremal sets of three elements must contain a common pair which must appear four times which is not possible.
Now all the sets of two elements and the element 5 which are contained in the sets of three elements and the element 5 which as we have noted are all the sets
of two elements and the element 5 must appear in the positions containing the the three element sets and the element 5 or the two other positions adjacent to these
which is a total of five positions. But we have two sets of three elements at both ends of the sequence which correspond to a set of two elements and the element 5 which lie on a span of 7 elements and we have a contradiction and we are done.
For the next case assume that in the restriction to sets containing the the element 5 we don’t have a set with four elements and the element 5 and we don’t have a set containing the element 5 only and we have exactly two containing the element 5 and three other elements.
We note two sets of three elements and the element 5 contains all but one combinations of two elements and the element 5. We also note that this combination consists of the two elements which are only in one of the sets of three elements and the element 5. Call these elements a and b.
We now look at two cases one in which the pair a,b occurs with the element 5 and one where it does not. In this post we will only deal with the case where it does occur.
If it does occur then we must have a set containing the double with two or more elements and the element 5. But by what came before that set can’t contain four elements and the element 5 or three elements and the element 5. So it must
contain only a and b and the element 5 but then we have 3 or more elements containing two elements and the element 5 which gives a contradiction.
So we have that the elements a and b can’t occur with the element 5.
There is a mistake in the last section of the proof. What I am going to do is to move all the pieces to the wiki and if all goes well post the remaining parts there. As to the mistake I believe that I can fix that.
I have now added the material to the wiki. If all goes well I will be adding more there as I complete the proof.
I have added another case of this proof to the wiki. It needs more work but right now
it looks like f(5) is 11.
How many 9 dim. in 13 dim. ?
Let me try to say something about commutativity. In Yury’s set of axioms, we have a sequence of subsets of [n], and one of the conditions that a sequence must satisfy to be considered valid is that there is a valid restriction for every element![j\in[n]](https://s0.wp.com/latex.php?latex=j%5Cin%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) . Now a restriction means that we take the subsequence of sets that contain
. Now a restriction means that we take the subsequence of sets that contain  , and remove it from all those sets. The sequence that results from this may not itself be valid, but the condition is that by taking subsets, we get a valid sequence, which we call the restriction to
, and remove it from all those sets. The sequence that results from this may not itself be valid, but the condition is that by taking subsets, we get a valid sequence, which we call the restriction to  .
.
Now let us start with a valid sequence containing the elements i and j. Because of this last step of taking subsets, there is no unique restriction to : if you first take the restriction to i, and then the restriction of the resulting valid sequence to j, you might end up with something that is different from if you had first taken the restriction to j, and then the restriction of that to i.
: if you first take the restriction to i, and then the restriction of the resulting valid sequence to j, you might end up with something that is different from if you had first taken the restriction to j, and then the restriction of that to i.
The additional condition of commutativity simply requires that the order of taking restrictions must not matter. Paco’s observation was that Yury’s axioms + commutativity is actually equivalent to the original f(n) set of axioms (what we called connected layer families in our paper).
Paco’s construction for Yury’s set of axioms depends on the observation that y(n) copies of [n+1] form a valid sequence: for any element, we can find a restriction to that element by taking an appropriate mapping of the other n elements to the n elements used in the maximum valid sequence of length y(n) of n elements.
It seems to me that this observation holds also in the m-shadow setting. Take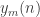 copies of the complete m-regular hypergraph on n+1 elements. Now as restriction to any element – let’s say the element n+1 – we simply take the maximum sequence for n elements. This is a subset, and the m-1 shadows also form a subset of those m-sets that contain n+1.
copies of the complete m-regular hypergraph on n+1 elements. Now as restriction to any element – let’s say the element n+1 – we simply take the maximum sequence for n elements. This is a subset, and the m-1 shadows also form a subset of those m-sets that contain n+1.
From that observation on, I believe the exact same argument should work going forward, which would be (a) disappointing and (b) contradict the intuition that the m-shadow axioms should provide for a way to “interpolate” between f(n) and y(n). What I mean by the latter statement is that I would like to have a simple proof that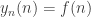 .
.
One idea that just came to my mind is to change the condition on restrictions in the following way. We could require that the (m-1)-shadows that appear in the restriction (in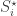 ) are exactly those sets A such that
) are exactly those sets A such that  are contained in
are contained in  . The difference is that if
. The difference is that if 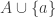 is in
is in  , then we now require that
, then we now require that 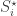 contains a superset of A.
contains a superset of A.
Hmm, that leads me to think that something bizarre is going on… what if m=n? I think instead of sequences of families of m-subsets, we should have sequences of families of subsets at most m, closed under taking subsets (i.e. abstract simplicial complexes, or whatever you want to call them). This needs more thought, but I have to run.
Let me suggest a modified abstraction of m-shadows. Again we are looking at sequences of families of subsets, but in this formulation I want all families to be non-empty and downward closed (i.e. closed under taking subsets). Let’s call such a sequence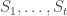 over a groundset X valid if it satisfies the following three axioms:
over a groundset X valid if it satisfies the following three axioms:
(1) It is convex in the usual sense, i.e. for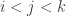 we have
we have 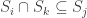 (keep in mind that the families are downward closed!)
(keep in mind that the families are downward closed!)
(2) The family containing only the empty set appears at most once.
(3) For every there exists a valid restriction in the following sense. Let a and b be the index of the first and last family containing x, respectively. Then there exists a valid sequence
there exists a valid restriction in the following sense. Let a and b be the index of the first and last family containing x, respectively. Then there exists a valid sequence 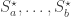 over the groundset
over the groundset  such that:
such that: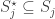 , and
, and if and only if
if and only if  .
.
(a)
(b) a set A of size at most m-1 is contained in
For m=1, this is Yury's set of axioms, because the condition 3(b) becomes empty. For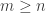 , the condition 3(b) forces restrictions on x to be exactly the families of sets containing x, with x removed. So then by taking the inclusion-wise maximal sets of each family in the sequence, we get a sequence of disjoint families that satisfies the original convexity condition, if I haven't missed anything.
, the condition 3(b) forces restrictions on x to be exactly the families of sets containing x, with x removed. So then by taking the inclusion-wise maximal sets of each family in the sequence, we get a sequence of disjoint families that satisfies the original convexity condition, if I haven't missed anything.
So I believe that with this definition, we have and
and 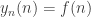 . Right?
. Right?
The next step would be to figure out a way of extending Paco's construction to the case m=2 with this definition, and then for constant m, and see how far we can push it.
This is interesting, I will try to think about it.
I’ve been trying to think about m=2 in terms of graphs, and let me just throw some constructions out there. I feel like I have something that could lead to a construction, but it’s easy to run into false trails. I just want to fix things I can say for certain.
First claim: adding a completely connected stable set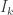 of k vertices. Given a valid sequence
of k vertices. Given a valid sequence 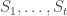 of undirected graphs, the sequence
of undirected graphs, the sequence  is also valid, where
is also valid, where 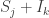 is the graph that one gets by adding the k vertices of the independent set and connecting each new vertex to all original vertices with an edge.
is the graph that one gets by adding the k vertices of the independent set and connecting each new vertex to all original vertices with an edge.
“Proof”: Convexity follows from convexity of the original sequence, and the empty graph appears nowhere. So it remains to see about restrictions. First case: restriction on a vertex of the independent set. Then the original sequence is a restriction, and it is valid. Second case: restriction on a vertex of the original family. If the restriction of the original family was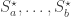 , then
, then  is a valid restriction of the new family, using some sort of induction on the size of the family.
is a valid restriction of the new family, using some sort of induction on the size of the family.
Second claim: the sequence of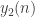 cliques
cliques  is a valid sequence.
is a valid sequence.
“Proof”: Convexity is clear, so let’s talk about restrictions. For every vertex, I want to define the restriction in the following way. Divide the remaining 2n vertices arbitrarily into two cliques A and B. Now let
in the following way. Divide the remaining 2n vertices arbitrarily into two cliques A and B. Now let 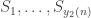 be a maximal sequence on n vertices. For both cliques A and B, define a 1:1 mapping of clique vertices to the n vertices of that maximal sequence. Now connect a vertex of clique A in
be a maximal sequence on n vertices. For both cliques A and B, define a 1:1 mapping of clique vertices to the n vertices of that maximal sequence. Now connect a vertex of clique A in  to every vertex of clique B that appears in
to every vertex of clique B that appears in 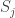 (keeping the 1:1 mapping in mind), and vice versa connect a vertex of clique B to those vertices of clique A that appear in
(keeping the 1:1 mapping in mind), and vice versa connect a vertex of clique B to those vertices of clique A that appear in  . The sequence of
. The sequence of  thus defined satisfies the requirements 3(a) and (b), but it remains to show that it is a valid sequence.
thus defined satisfies the requirements 3(a) and (b), but it remains to show that it is a valid sequence.
Convexity follows from the convexity of the 1-shadow of the sequence. We have to explain how the restrictions should look. In fact, if we restrict to a vertex in clique A, then the restriction of
sequence. We have to explain how the restrictions should look. In fact, if we restrict to a vertex in clique A, then the restriction of  will be those vertices and edges in B that appear in
will be those vertices and edges in B that appear in  , plus an independent set on the n-1 remaining vertices of A (we are forced to keep the vertices of A, but we are allowed to throw away all the edges). This restricted sequence is valid by the first claim. Of course, restriction to a vertex in clique B is done symmetrically.
, plus an independent set on the n-1 remaining vertices of A (we are forced to keep the vertices of A, but we are allowed to throw away all the edges). This restricted sequence is valid by the first claim. Of course, restriction to a vertex in clique B is done symmetrically.
I hope I didn’t miss any bugs in the “proofs”, since they are a bit subtle. I’m not totally happy about having to double the vertices, but if the next part of Paco’s construction idea can be transported without paying too much, we can still get a super-polynomial construction. The important point of this part was to prove that quite long sequences of cliques are valid, because those can then be used as easy-to-manage building blocks.
There seems to be a problem with the second claim. If we restrict on a vertex in A that represents a vertex that appears in , then in fact this vertex is connected to all other vertices, and so all other vertices need to appear in the restriction. Can this be fixed somehow? Am I missing something?
, then in fact this vertex is connected to all other vertices, and so all other vertices need to appear in the restriction. Can this be fixed somehow? Am I missing something?
I’m a bit busy right now, but I will continue to think about this.
At least this problem should not invalidate the construction itself. In fact, we can simply start with a sequence of K blocks only, and then on the first restriction let the first and last block become P and Q blocks, respectively. In fact, this should improve the construction somewhat. If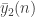 is the maximum length sequence of complete graphs on n vertices that is valid, then we should get something like
is the maximum length sequence of complete graphs on n vertices that is valid, then we should get something like 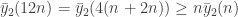 .
.
Let me try my hands at a complete, super-polynomial construction for m=2.
Basically, the idea is to start with 4 sets of (2n+1)+k vertices. Let’s call those sets A, B, C, and D. We use three types of graphs on these sets. First of all, we use the complete graph, denoted Type K. Then there are Type P and Type Q. In Type P, A and B are cliques and C and D are stable sets. Furthermore, every vertex of A is connected to every vertex of C, and every vertex of B is connected to every vertex of D. In Type Q, A and B are stable and C and D are cliques. Furthermore, A is connected to D and B is connected to C. So the picture you should have before you is of a bipartite graph on four vertices, and two different matchings on them.
We now start with a sequence of k+1 blocks, in the sequence P, K, …, K, Q. Each block contains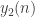 graphs of the indicated type, for a sequence of total length
graphs of the indicated type, for a sequence of total length 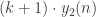 . Convexity is clear, so what about restrictions?
. Convexity is clear, so what about restrictions?
A K block can remain a K block or turn into a P or Q block according to our choosing (of course, the parameter k needs to be reduced).
For a P block, we need to do a case distinction based on whether the restricting vertex is in A, B, C or D. If the vertex is in C or D, then we can simply restrict to a clique on A or B, respectively, with no other remaining vertex. If the vertex is in A or B, then both A and C or both B and D, respectively, must remain due to the constraint (3b) in the requirements for restrictions. This can be thought of as keeping one edge in the bipartite meta-graph on 4 vertices. We call a graph that results of such an operation a P* graph. Similar, a Q block turns into a Q* block.
The crucial thing to note is that when we restrict a P block and a Q block on the same vertex, then the resulting 1-shadows (i.e. the supporting vertices) of the resulting P* and Q* blocks are disjoint. So when we then restrict on the next vertex, either the P* block or the Q* block disappears.
To recap, we start with a sequence of blocks like P, K, K, K, Q. After the first restriction, we get a sequence P*, K, K, K, Q*. After the second restriction, we drop either the P* or the Q* block. This allows us to change one of the K blocks, to get (say) P*, K, K, Q. After the third restriction, the Q block becomes a Q* block, and the P* block may or may not disappear. Let’s say it disappears, which allows us to convert another K block, resulting in P, K, Q*. After a while, we end up at P*, Q*. Now whichever vertex we restrict on, we are left with either a P* or a Q* block. But those are valid sequences (if they are not too long), because they are simply a clique, possibly connected to a stable set.
If we want to start with k+1 blocks in total, we need to start with (2n+1)+2k vertices in each of A, B, C, and D, because perhaps we always restrict on vertices in the same set, and we can only guarantee the disappearance of a block every other restriction, and we do need at least 2n+1 vertices per set at the end. What we get is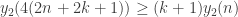 . Setting k+1 = n, this gives
. Setting k+1 = n, this gives 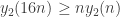 , which is super-polynomial, though with worse constants than for
, which is super-polynomial, though with worse constants than for 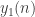 .
.
I hope I didn’t make a silly mistake somewhere. But if not, this is quite interesting. New questions would be: can we get better constants for m=2? And what about m=3?
This is very interesting!
Nicolai, is it easy to state the modified shaddow property just for m=2 in terms of graphs? (somehow like the nonmodified version https://gilkalai.wordpress.com/2010/11/28/polynomial-hirsch-conjecture-5-abstractions-and-counterexamples/#comment-4150 which turned out not to be interesting.) Maybe we need two parameters m for the shaddow and d for the size of the sets. So that we can have a gradual intermediate functions y_m(d,n) leading to f(d,n) where we can have d be rather small compared to n. Anyway, your construction seems very promising…
The way I have been thinking about the case m=2 – in particular the restrictions – is as a kind of back-and-forth game on undirected graphs.
Player A (who wants to define a valid sequence) produces a convex sequence of undirected graphs. A vertex is contained in the graph if the corresponding 1-set is contained in the family corresponding to that graph, and an edge exists in the graph if the corresponding 2-set is contained in the family.
Player B, who wants to check the validity, can now choose one vertex v. For each graph in which that vertex appears, Player A must return a new graph which is a (not necessarily induced) subgraph of the original graph on exactly those vertices that are connected to v in the original graph.
As you pointed out elsewhere, the “exactly” part is what distinguishes my variation from the original one, and this is what makes it interesting.
There is a different view on the problem. Instead of working with sets one can consider working with numbers, where the element ‘k’ present in a set denote the ‘1’ present in binary number at position k. For example, ‘ ‘ translates to ‘0..0’, {1,3} translates to ’00…101’= 5. The family is the set of numbers. Then the problem is translated to the maximum height of stack of families with certain constraints. In every column (binary position) there is a subset of numbers with the signature of only the following form ’00..001..10..0′ with possibly omitted leading or trailing zeros. In other words no zeros can appear in-between ones. Another constraint is all the numbers are different.
‘ translates to ‘0..0’, {1,3} translates to ’00…101’= 5. The family is the set of numbers. Then the problem is translated to the maximum height of stack of families with certain constraints. In every column (binary position) there is a subset of numbers with the signature of only the following form ’00..001..10..0′ with possibly omitted leading or trailing zeros. In other words no zeros can appear in-between ones. Another constraint is all the numbers are different.
The following construction is possible (consider only even ‘n’): numbers. This is left part of the number
numbers. This is left part of the number are obtained by vertically cyclically rotating right part
are obtained by vertically cyclically rotating right part
1. one divides the number into 2 halves.
2. one construct ladder for lower half.
’00..00|000..001′
’00..00|000..011′
….
’00..00|001…111′
’00..00|011…111′
’00..00|111…111′
this is upper part of the stack. ~n/2 numbers (families)
3. one construct flipped version of the ladder on the higher half.
’11..11|000…000′
’11..10|000…000′
’11..00|000…000′
…
’10..00|000…000′
’00..00|000…000′
This is bottom part of the stack. ~n/2 numbers
4 one can fill the middle with the following construction
4.1 write down all the binary numbers of size n/2 except 0 –
’00…001′
’00…010′
’00…011′
’00…100′
…
’11..111′.
4.2 form families (and insert then in the middle of stack) by adding right parts in the following manner
4.2.1 Family 1
’00…001|00…001′
’00…010|00…010′
’00…011″00…011′
’00…100|00…100′
…
’11..111|11..111′.
4.2.3 Families 2..
Family 2
’00…001|11…111′
’00…010|00…001′
’00…011″00…010′
’00…100|00…011′
…
’11..111|11..110′.
Family 3
’00…001|11…110′
’00…010|11..111′
’00…011″00…001′
’00…100|00…010′
…
’11..111|11..101′.
…
Satisfaction of constraints:
2 and 3 are certainly satisfy the condition of conjecture.
4.2.3 are also satisfying the conditions since all the numbers are present in all families.
4.2.3 – 2/3 are also satisfying the conditions, since it is always possible to find the the number from the family with the same right or left part. This set will have desired properties of the signature.
All the numbers are different by construction.
The construction is not quite working after second thought.
In particular there are complimentary numbers either on the right or left side (logical and =0), that does not have representation in the numbers. There are additional constraints in on the middle set of numbers, that lower the number the height of the stack.
Hi everyone,
I thought I would share some thoughts on improving the upper bound on f(d,n). I did not yet read all the previous posts, so some of what I will say might have been pointed out already.
The current upper bound is based on the relation:
f(d,n) \le f(d-1,n-1) + 2f(d,n/2)
Note that if we only have such inequalities and we maximize f(d,n) over d for a fixed n, then d should be close to n. I will prove the additional inequality:
f(d,n) \le \sum_{i=0}^{d} f(d-i,n-d)
which by itself gives a worse bound, but now d should be fairly small compared to n. When combining the two inequalities there is a tradeoff between d being large and d being small, and this seems to significantly improve the bound.
Let F_1, F_2, … , F_t be a sequence of disjoint families of subsets of {1,2,…,n} satisfying the convexity constraints. Assume that for all 1 \le i \le t and S \in F_i, |S| = d.
Pick some set T \in F_t. We partition {1,…,t} into d+1 disjoint intervals I_0 = {1,…,t_0}, I_1 = {t_0 + 1,…,t_1}, … , I_d = {t_{d-1} + 1, … , t}, such that for all 0 \le m \le d and all i \in I_m we have for all S \in F_i, |S \cap T| \le m, and there exists S \in F_i such that |S \cap T| = m. It follows directly from the convexity that such a partition always exists. More precisely, if for some i and S \in F_i, |S \cap T| = m, then for all i < j < t there exists R \in F_j such that S \cap T \suseteq R, and, hence, |R \cap T| \ge m.
Next, consider some interval I_m, and let l be the lowest index within the interval. Pick S \in F_l such that |S \cap T| = m. Consider the sequence of families G_l, … , G_{t_m} defined by for all l \le j \le t_m, G_j = {R \in F_j | R \cap T = S \cap T}. Then G_l, … , G_{t_m} is itself a legal sequence satisfying the convexity constraints. Indeed, assume that G_l, … , G_{t_m} is not a legal sequence. Then there exist l \le i < j < k \le t_m such that there exist A \in G_i and C \in G_k, such that for all B \in G_j, A \cap C is not contained in B. Since F_1, … , F_t is a legal sequence there exists B' \in F_j \setminus G_j such that A \cap C \subseteq B'. Since j \in I_m and S \cap T \subseteq B', it follows that B' \cap T = S \cap T. Hence, R'_j \in G_j, and we get a contradiction.
Since all sets in G_l, … , G_{t_m} are identical with respect to the elements of T we can ignore these elements and focus on the remaining n-d elements of which there are d-m in each set. It follows that t_m – l + 1 \le f(d-m,n-d). Summing over all intervals we get the inequality:
f(d,n) \le \sum_{i=0}^{d} f(d-i,n-d)
I did not yet work out exactly how much better the bound gets, but I wrote a small program that computes the function:
f(0,n) = f(d,0) = 1, and
f(d,n) = min[ f(d-1,n-1) + 2f(d,n/2) , \sum_{i=0}^{d} f(d-i,n-d) ]
The first column is the original bound, and the second column is the improved bound. The value of d shown in the parentheses is the d that maximizes f(d,n) for that particular n.
n=0: 1 1 (max d=0)
n=1: 2 2 (max d=1)
n=2: 6 3 (max d=1)
n=3: 14 5 (max d=2)
n=4: 26 7 (max d=2)
n=5: 46 10 (max d=2)
n=6: 74 14 (max d=3)
n=7: 114 20 (max d=3)
n=8: 166 27 (max d=3)
n=9: 238 36 (max d=4)
n=10: 330 48 (max d=4)
n=11: 450 64 (max d=4)
n=12: 598 80 (max d=4)
n=13: 786 105 (max d=5)
n=14: 1014 125 (max d=5)
n=15: 1294 157 (max d=6)
…
n=99: 6792254 207226 (max d=24)
n=100: 7183914 217459 (max d=24)
n=101: 7595230 228091 (max d=24)
…
n=499: 258939150786 2104046350 (max d=90)
n=500: 262849417686 2132218328 (max d=90)
n=501: 266812361442 2160701752 (max d=90)
…
n=1499: 2047247790745374 6409615527648 (max d=227)
n=1500: 2059352717668682 6443724136334 (max d=228)
n=1501: 2071522378901262 6478023449463 (max d=228)
…
n=2999: 1270357198360926690 2155121235152081 (max d=413)
n=3000: 1274475903796264054 2161466320066430 (max d=413)
n=3001: 1278606778892833998 2167827661771383 (max d=413)
This is interesting. We can also use that f(d,2d-i)<=f(d-i,2d-2i). There are also some useful other relations when n is not too large w.r.t. d. is at most
is at most 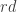 then
then 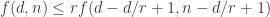 .
.
Another inequality we can try to add is: If
The first inequality only seems to slightly improve the bound. For instance, for n=1500 we get 3073645233959 instead of 3078181661959. I did not attempt to apply the inequality when it increases n, though.
I do not immediately see how to prove the second inequality, in order round d/r correctly, and I think I’ll go to bed now 🙂
If anyone is interested in playing around with the program I wrote, I have uploaded it here:
http://www.cs.au.dk/~tdh/misc/Count.java
Forget this part: “I did not attempt to apply the inequality when it increases n, though.” Of course i should be positive…
I now use the version of the original inequality that has been slightly tightened (as shown in the wiki):
f(d,n) \le f(d-1,n-1) + f(d,n/2) + f(d,(n-1)/2) – 1
where all divisions are rounded down. It turns out that the inequality I suggested is only better for d=1 and n=3, which gives the seemingly constant factor improvement. The two inequalities you suggest do not give further improvements.
Furthermore, it is actually the original inequality that causes d to be smaller than n. When I started thinking about the problem I thought about sets where the maximum cardinality was d, not where all sets have cardinality d, which caused the confusion.
I still like the idea of partitioning {1, … ,t} into intervals and use monotonicity in some form. It needs to be strenghened before being useful, though.
It would be convenient with a way of editing posts… I keep messing up 😦
Since there there is no empty set for d > 0, the tightened version of the inequality is:
f(d,n) \le f(d-1,n-1) + f(d,n/2) + f(d,(n-1)/2)
My bound is then better for d=2 and n=2, and for d=1 and n>2. It doesn’t really change anything, though.
When calculating the numbers I used f(d, n) = f(min(d,n), n), when, in fact, f(d,n) = 0 for d > n. The improvement is much smaller for the correct numbers, something like a constant factor, so the inequality might not be very useful. The best choice of d is smaller than n/2, however, so the question is if we can construct a better inequality that decreases the choice of d further.
I will check the additional inequalities you suggested, Gil.
The correct numbers are:
n=0: 1 1 (max d=0)
n=1: 2 2 (max d=1)
n=2: 5 3 (max d=1)
n=3: 8 4 (max d=1)
n=4: 12 5 (max d=1)
n=5: 20 8 (max d=2)
n=6: 28 11 (max d=2)
n=7: 37 15 (max d=2)
n=8: 50 20 (max d=3)
n=9: 65 26 (max d=3)
n=10: 83 32 (max d=3)
n=11: 104 40 (max d=3)
n=12: 132 50 (max d=4)
n=13: 165 62 (max d=4)
n=14: 201 75 (max d=4)
n=15: 241 91 (max d=4)
…
n=99: 276826 105582 (max d=22)
n=100: 290241 110708 (max d=22)
n=101: 304149 116022 (max d=22)
…
n=499: 2656781211 1013419743 (max d=87)
n=500: 2692172777 1026924340 (max d=87)
n=501: 2727952776 1040577063 (max d=87)
…
n=1499: 8031555623839 3061878344311 (max d=225)
n=1500: 8074328707406 3078181661959 (max d=225)
n=1501: 8117296557588 3094559223510 (max d=225)
…
n=2999: 2697415820357114 1028479798595979 (max d=411)
n=3000: 2705362677941314 1031509406930277 (max d=411)
n=3001: 2713330310552611 1034546783968586 (max d=411)
I’m trying to read EHRR, and have problem connecting it to the present discussion. I may be missing something trivial.
Consider a single mesh on the support U1 that contributes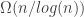 layers. Consider another mesh with support U2 of the same size,
layers. Consider another mesh with support U2 of the same size, 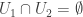 . Take Kroneker product of layers in 2 meshes, since ordering of layers irrelevant the final set of layers is connected layer family. This lead to recursion
. Take Kroneker product of layers in 2 meshes, since ordering of layers irrelevant the final set of layers is connected layer family. This lead to recursion 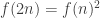 , which is exponential. To get the positive construction one needs mesh with, say, 3 layers. This way it is easy to check that layers ordering irrelevant. That requires, say,
, which is exponential. To get the positive construction one needs mesh with, say, 3 layers. This way it is easy to check that layers ordering irrelevant. That requires, say, 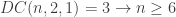 , according to Theorem 4.1, i.e. minimum support of size 12.
, according to Theorem 4.1, i.e. minimum support of size 12.
The construction contradicts the assumption of theorem about f(n) upper bound. The meshes have full cumulative support in all layers, therefore, no such s or r exist. The same is for Kroneker product.
Does anyone know a software package to generate (disjoint) covering designs to generate an example of recursion step for the construction above?
I have access to matlab and therefore mupad, or anything open source. It is painful to do it by hands.
The ordering of layers is not irrelevant, unfortunately. I’m not sure I understand exactly what you mean by Kronecker product, but I do not see how your construction could satisfy convexity?
Let’s say your original families are regular, meaning all sets have size d. If you just bunch sets from two families together, you are no longer guaranteed that subsets of size d are present in a contiguous sequence of families. That is likely where convexity is not preserved in your construction.
I apologize, if the following is unparsable.
I’m looking at EHRR Lemma 4.1. and it seems to me that the particular pairing they provided is sufficient, but not necessary. Any pairing with the following properties are satisfying Lemma 4.1. writing down the indexes for the sets, we can rewrite EHRR mesh as


….
with the meaning of the 2 digit number “\alpha,\beta” =
So, Lemma 4.1. works when in each row (layer) all digits appear on the first place and all the digits appear on the second place, and all the numbers in the mesh are different.
Therefore, the following mesh is also fine.


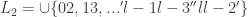
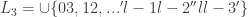 .
.
where second elements are exchanged.
Then cyclically shifted couple of layers
Translating it to many groups will read



which is f(n)/2 sub-layers from each layer.
and then cyclical shift such that there are no repeating pairs.
I agree with your point that it is sufficient if every pair of numbers appears only once in total, and every “digit” as you call it appears at least once in every position. This allows some variants of the proof of Lemma 4.1, and the reason we chose that particular variant is simply that it can be written down in a nice and clean way.
What I do not understand, however, is how you want to go from there to something that is more than quadratic? In particular, I’m not sure what you mean by translating to many groups. Are you thinking of something like taking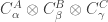 for three groups?
for three groups?
In that case, be aware that the condition becomes stronger. If you write your numbers as triples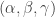 , then for all pairs
, then for all pairs 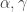 and for all layers there has to be a
and for all layers there has to be a  such that
such that 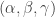 is on that layer. In other words, if you have at most
is on that layer. In other words, if you have at most  choices for each “digit”, you can create at most
choices for each “digit”, you can create at most  layers in that way, i.e. you don’t get a quadratic number of layers out of that construction.
layers in that way, i.e. you don’t get a quadratic number of layers out of that construction.
Right.
I think there is more freedom, than stated in the paper. In particular, it seems that the following mesh stack
M(A, d-1, B, d-1)
M(A, d-2, B, d-2)
….
M(A, 1, B, 1)
is also convex. It is again less beautiful, than in the paper. On the other hand for this stack it seems to be sufficient that any sets from previous layer are covered, e.g. are covered by all layers in M(A, i, B, j), and therefore active. Only those elements appear in previous mesh, and it is not necessary to all proper subsets to be active. Correct me if I’m wrong. By the Theorem 4.1. this lead to at least
are covered by all layers in M(A, i, B, j), and therefore active. Only those elements appear in previous mesh, and it is not necessary to all proper subsets to be active. Correct me if I’m wrong. By the Theorem 4.1. this lead to at least 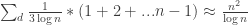 , still almost quadratic.
, still almost quadratic.
If this is correct it opens possibility to arrange more that 2 groups in a connected layer family, with the requirements that all unions of proper subsets of (A, i, B, i, C, i) are active in all layers of corresponding mesh.
Nicolai’s construction looks very promising but I am still a bit confused about the abstractions we have for m-shadows.
We have an abstraction suggested by Nicolai giving a function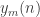 and possibly also
and possibly also  . This is described in terms of convex downward closed families which satisfies certain properties described by Nicolai. (Perhaps we can add the parameter d by assuming all sets in all families have size at most d). We have to be careful how m is changed when we move to the restricted families. But I suppose that m is kept unchanged. (While if we add the parameter d it is reduced by 1).
. This is described in terms of convex downward closed families which satisfies certain properties described by Nicolai. (Perhaps we can add the parameter d by assuming all sets in all families have size at most d). We have to be careful how m is changed when we move to the restricted families. But I suppose that m is kept unchanged. (While if we add the parameter d it is reduced by 1).
If m is at least n then . (And probably when m is at least d $ latex y_m(d,n)=f(d,n)$.)
. (And probably when m is at least d $ latex y_m(d,n)=f(d,n)$.)
What confuses me is that I do not see the difference (say for m=2) with my graph definition in this remark. And therefore, I am not sure about Yury’s remark asserting (like another remark by Nicolai) that you can take Paco’s example and just replace a set by the complete graph (or hypergraph) of it.
Nicolai’s new example is more complicated and give different bounds.
So what’s the difference between these abstractions for the shadow (say for m=2)?
Maybe I can answer my own question: The original requirement was
3b) if an element a belongs to the union of sets in every then there are legal sequences of families on the ground set X\{a} of elements, such that
then there are legal sequences of families on the ground set X\{a} of elements, such that  is a family m subsets of X\{a}, and a subfamily of
is a family m subsets of X\{a}, and a subfamily of 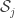 , whose (m-1)-shadow is included in the set of all subsets so that adding to them gives us a set in
, whose (m-1)-shadow is included in the set of all subsets so that adding to them gives us a set in 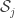 .
.
And the correct definition is to replace “included in” by “is the”. When you take the complete graphs on the sets described by Paco example then I suppose but I dont see it precisely this will not work under the new definition.
Exactly. This is how I understand it as well.
Let me try to produce some intuition on what the problem is with Paco’s construction and m=2 while traveling through snow-covered landscapes.
The problem with complete graphs is that when you start with a complete graph on n vertices, then any restriction has to be on n-1 vertices. And then recursively, one has to produce a valid restriction for each of those n-1 vertices, and so on.
However, the way to get examples of super-polynomial valid sequences is to have families that do not contain many vertices, because then those families can be dropped entirely when a restriction on one of the other vertices is requested.
I.e. in Paco’s construction, every time you restrict to one element (vertex), one entire block of y(n) families can be dropped, simply because at both ends of the sequence there are y(n) families that do not contain half of the elements. The important part is that when one of the end blocks disappears, we also remove elements from the block that now becomes the new end block, to maintain the property that at any time there are y(n) families at either end that can easily be dropped by restriction.
This removal of elements is not possible in the case m=2 when everything is on complete graphs, because of the property that all vertices that are connected to the restricting vertex must still be present.
This is why my construction (which is complicated and hopefully can be simplified) does this removal of vertices in a two-stage process, where first all vertices remain, but edges are removed to reduce connectivity, and then in a second step, vertices can be dropped.
The somewhat complicated setup with four disjoint sets of vertices A, B, C, D is how I ensure that the 1-shadows of the end blocks are disjoint, and that is what guarantees that a block can be dropped.
Pingback: 2010년 TCS 분야 연말 결산 « P 는 NP
Pingback: 507- Problem list (III) « Teaching blog
Pingback: 507- Problem list (III) « A kind of library
Eureka 7,