
Consider the following two scenarios
(1) An experiment tests the effect of a new medicine on people which have a certain illness. The conclusion of the experiment is that for 5% of the people tested the medication led to improvement while for 95% it had no effect. (The experiment followed all rules: it had a control test it was double blind etc. …)
A statistical analysis concluded that the results are statistically significant, where the required statistical significance level is 1%. This roughly means that the probability 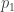

(2) An experiment tests the effect of a new medicine on people which have a certain illness. The conclusion of the experiment is that for 30% of the people tested the medication led to improvement while for 70% it had no effect. (The experiment followed all rules: it had a control test it was double blind etc. …)
A statistical analysis concluded that the results are statistically significant, where the required statistical significance level is 1%. (Again, this roughly means that the probability 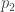
Test your intuition: In which of these two scenarios it is more likely that the effect of the medication is real.
You can assume that the experiments are identical in all other terms that may effect your answer. E.g., the theoretical explanation for the effect of the medicine. Note that our assumption 

I take issue with the language that “This means that the probability that such an effect happend by chance is less or equal 0.01.”
It falls under #2 on the wikipedia list of p-value misunderstandings. (http://en.wikipedia.org/wiki/P-value#Misunderstandings)
The p-value is NOT the probability that a finding is the product of chance alone, it is calculated ASSUMING that the finding is the product of chance alone and thus can’t be used to gauge the probability of that being true. The p value is a probability conditioned on the null hypothesis being true!
I agree, (I tried to make it more precise) Gil
I don’t understand precisely the meaning of the word “Convincing”
If there exist some machine that returns answers “yes” in all time,then i doubt that
‘Can this machine only output the word “yes” ?’
And i think, there exist an another type of people who thinks that,
‘nearness’ of the numerical value of the probability between two reversal events
means “existence of some disorders in determination” and that hurt the confidence of this
experiment for them.
For the people of “nearness hater” , the results like 100-0 ,0-100 are desirable and confident.
If “the medication led to improvement” for any fraction of the people tested, then we know for a fact that the medication works. I guess you mean that a certain fraction (5% or 30%) of the patients “showed improvement”?
Do we need to know what the null hypothesis was?
Also, it’s not clear to me what I can conclude about the experiment based on its “conclusion”. Does concluding a 5% improvement rate mean that under some prior the posterior estimate of the expected percentage of people who will see an improvement is 5%? Or that exactly 5% of those in the study saw an improvement? Or something else?
I read http://en.wikipedia.org/wiki/Frequentist_inference for clues, but I’m left confused: “any given experiment can be considered as one of an infinite sequence of possible repetitions of the same experiment, each capable of producing statistically independent results. In this view, the frequentist inference approach to drawing conclusions from data is effectively to require that the correct conclusion should be drawn with a given (high) probability, among this notional set of repetitions.”
I think there is a valid point regarding the way I described the two scenarios. Perhaps better is to think alternatively about the following scenarios: We have an illness with recovery rate of 20%. In one scenario the medication increases the recovery rate to 23%. In another scenario the medication increases the recovery rate to 40%. In both scenarios the null hypothesis is that the medication had now effect so the recovery rate under the null hypothesis is 20%. In both experiments the effect is shown experimentally, the reguired significance level is 1%, p-values are 0.008 and in any other respect the situation is the same. (With one exception – having the same p-value forces the sample size to be larger in the first scenario.)
The general “test your intuition” question is this: Would you regard it more likely that the claimed effect does not exist in the first case where the claimed effect is smaller, or in the second case where the claimed effect is larger, or you see no difference.
I think it’s more likely that the claimed effect doesn’t exist in the second scenario (with the stronger observed effect and the smaller sample size). Here’s my reasoning, with apologies in advance in case it is non-human-readable or just plain nonsensical.
In the first scenario, when we say the null hypothesis is rejected with p=.008, this roughly means that 0.8% of the normal curve with mean 0.2 and variance (0.2)(0.8)(N) lies to the right of 0.23. (“Roughly” because the correct distribution is binomial, and only approaches the normal curve in the limit.) Now we can only estimate the probability that the null hypothesis is true by assuming a prior distribution on the true recovery rate, so let’s follow tradition and invoke a flat prior. Then the probability that the null hypothesis is true is also “roughly” a tail of a normal curve: it’s the portion of the normal curve with mean 0.23 and variance (0.23)(0.77)(N) which lies to the left of 0.2. Notice that (0.23)(0.77) > (0.2)(0.8), so the probability that the null hypothesis is true is a bit more than 0.8%. Of course, there’s no reason it should be exactly 0.8%, though that is a common misunderstanding of how p-values work!
In the second scenario, roughly 0.8% of the normal curve with mean 0.2 and variance (0.2)(0.8)(N) lies to the right of 0.4, and the probability that the null hypothesis is true is roughly the portion of the normal curve with mean 0.4 and variance (0.4)(0.6)(N) which lies to the left of 0.2. And again, the probability that the null hypothesis is true is more than 0.8%, since (0.4)(0.6) > (0.2)(0.8). But moreover, (0.4)(0.6) is larger than (0.23)(0.77), so even after normalization, the uncertainty in the second scenario is higher than in the first, which means that the null hypothesis is more probable in the second scenario.
Out of curiosity, I got out my z-score table and estimated that the null hypothesis has a 1.1% chance of being true in the first scenario, and 2.4% in the second. So there’s a very substantial difference! Of course, you can probably arrive at the opposite conclusion if you start with a weird prior.
What is the “claimed effect”? Is the claimed effect for the first case that the drug improves the recovery rate to 23%, and the claimed effect for the second case an improvement to 40%? Or is it (in each case) that there is any improvement at all?
(Perhaps I should say “improves to *at least* 23%, etc. …)
Dear Tom, The 23% snd 40% are the observed recovery rates.The claimed effect is that there is an improvment. (As mentioned, the two p-values being equal requires a larger sample in the first case.)
Because of the medication used here is identical,there is no difference.
Whether the claimed effect is exist or not is a substantial fact.
It seems at first that the first scenario must be less convincing, because it is far easier to be convinced of effective treatment with a large (probabilistic) effect.
But on second thought – that is exactly the nub if the matter. The single most relevant size is in fact not mentioned – the sample size. Now, the first experiment, must have a sample much larger than the second, in order to get the same p-value for lower success.
When the question is “what are the chances there is any effect at all” (rather than the quantitative statement the experiment is based upon – and that the p-value is measuring), it seems that the first must be more convincing.
Not having significant (or, in fact, any) knowledge in statistics, I hope my intuition didn’t make a total mess of it.
If the null hypothesis of zero effect were true, then the probability of getting the data we got in experiment 1 is exactly the same as the probability of getting the data we got in experiment 2 – that is what p1=p2 means. So the two experiments are equally convincing about the likely falsity of the null hypothesis of zero effects.
However, the two experiments give us different estimates of the size of the treatment effect and thus about the likelihood that the treatment effect is, say, stronger than 10%. Assuming symmetry, the first experiment has larger sample size and precision and would suggest that it is very unlikely that we would have observed those data if the real effect were stronger than 10%, while the data in the second experimental data do not provide any evidence against stronger-than-10%-effects (quite the contrary, in fact).
So my answer would depend on what you mean by “real effect”: if you mean “something larger than zero effect” then the answer is “same”; if you mean “something large enough that people would pay attention” then the answer is “the second experiment”.
Dear Valter, I meant “something larger than zero effect”.
Gil,
I have few comments.
1) the way you describe the results does not make sense. You say, for example, that in the first experiment 5% responded to the treatment. What does it tell us about the treatment effect? There is no way to know, if we do not know what happened in the control group.
2) your interpretation of the p-value is wrong. The probability thathis means that an effect happens by chance (under the “null hypothesis” ) is the significance level, which is 1% in your example. A possible interpretation of the p-value is that the p-value is the probabulity to obtain the same evidence or even more convincing evidence to suuport the alternative hypothesis is you redo the experiment.
3) The question you ask to test the intuition does not make sense to me, as I am a classical statistician (aka frequentist). The null hypothesis is either true or false, and no probabilty is assigned to it. As a consequence, the treatment is either effective or non-effective, and asking how likely it is that the effect is real is meaningless. To me, both experiments provided convincing evidence to the treatment effect. As a pharmaceutical statistician, I would also say that the larger study is a waste or resources.
4) Even if I was a Bayesian statistician, i.e. believe that a probability can be assigned to each of the hypotheses, the whole story would not make sense to me, since Bayesian statistics denies the concept of a p-value. Instead, a Bayesian statistician will use Bayes theorem to calculate the posterior probability (given the data collected in the experiment) the the hypothesis of no effect is true. In that case, the answer to your question is straightforward.
Dear Yosi
Thanks a lot for your comments. Of course to make matters simple I did not mention all possible issues (like control tests). The crux of the question is this:
You have two experiments where in one the strength of the conjectured effect is small and in the second the strength is large. Due to different sample sizes you get precisely the same p-values. The question is if you regard the case that the effect is real equally convincing, or you regard the experiment with weaker effect and larger sample size as more convincing or perhaps ypu will regard the experiment with stronger effect and smaller sample size more convincing.
If I understand your answer in point 3) you regard both experiments as equally convincing.
Also you said that for Bayesian statistician the answer is straightforward. But what is it?
In any case, I am certainly interested in a point of view of “classical statistician”. If the point of view is that the question (say, in the crux way described in this comment) is meaningless then this is also of interest. (But I tend to doubt it.)
Regarding your point 2) and the interpretation of p-values these are interesting issues. But to make the situation as simple as possible I assumed that both the required significance level and the observed p-value are the same in both examples.
In any case, it is very nice to hear your views as a professional statistician and a good opportunity to recommend your very nice ststistics blog to my Hebrew speaking readers.
Hi Yosi, It looks that your third comment is parhaps the most important. You wrote “As a pharmaceutical statistician, I would also say that the larger study is a waste of resources,” and I completely agree with this. (On the other hand, I will not regard running independent replications as a waste of resources.)
You also wrote “The null hypothesis is either true or false,… as a consequence, the treatment is either effective or non-effective”. I do not agree that if the null-hypothesis is false then necessarily the treatment is effective. (I also don’t think this is the standard statistical point of view.) The null hypothesis can be false (or can be seen as being false by the statistical analysis) from reasons other than the research hypothesis being true.
So my intuition request is precisely aimed at this discrepancy: In which of the two scenarios I described (if any) the failure of the null hypothesis is more convincing to establish that the treatement is effective.
“The null hypothesis can be false (or can be seen as being false by the statistical analysis) from reasons other than the research hypothesis being true.”
My understanding of the point you are making is that there are three possibilities: 1) the null hypothesis is true – i.e. the observed difference between the experimental and control group is due to random error; 2) the research hypothesis is true – i.e. the treated group has a better outcome, because of the medication; 3) the treated group has a better outcome, because of some systematic effect that the experimental design failed to control. Is that what you mean?
Looking at it this way, my intuition is that a small effect is more likely to be produced by a flawed experiment than a large one, so the experiment showing a large effect is more convincing that there is some genuine effect from the medication.
Dear Ben, “Is that what you mean?” yes.
Here is an interesting related post:
http://andrewgelman.com/2015/10/13/what-do-you-learn-from-p-05-this-example-from-carl-morris-will-blow-your-mind/
Thanks for the update! Carl Morris’s example seems to show the same phenomenon I was pointing out in my 2011 comment: Pr(H_0 | t) is in each instance larger than the p-value, and the discrepancy is larger when the sample size is smaller.