

I would like to discuss the following remarkable paper posted on the arXiv in June 2023.
Effect of Non-unital Noise on Random Circuit Sampling,
by Bill Fefferman, Soumik Ghosh, Michael Gullans, Kohdai Kuroiwa, and Kunal Sharma’s
Abstract: In this work, drawing inspiration from the type of noise present in real hardware, we study the output distribution of random quantum circuits under practical non-unital noise sources with constant noise rates. We show that even in the presence of unital sources like the depolarizing channel, the distribution, under the combined noise channel, never resembles a maximally entropic distribution at any depth. To show this, we prove that the output distribution of such circuits never anticoncentrates — meaning it is never too “flat” — regardless of the depth of the circuit. This is in stark contrast to the behavior of noiseless random quantum circuits or those with only unital noise, both of which anticoncentrate at sufficiently large depths. As consequences, our results have interesting algorithmic implications on both the hardness and easiness of noisy random circuit sampling, since anticoncentration is a critical property exploited by both state-of-the-art classical hardness and easiness results.
I am thankful to Soumik and Kunal, two of the authors, for bringing the paper to my attention and to Soumik for helpful clarifications and useful discussion. This work was featured on the UChicago CS departmental website.
In this post I will describe some findings of the new paper and possible relevance to my study (with Yosi Rinott and Tomer Shoham) of the Google 2019 quantum supremacy paper. As far as we can see, the phenomenon described in the new paper is not witnessed in the experimental data of the Google 2019 experiment.
Noisy random circuit sampling
Random quantum circuits have an important role for the study of NISQ (noisy intermediate quantum) computers, which, in turn, represent much of current efforts for demonstrating quantum computation. There were several important theoretical papers for understanding the effect of noise on the ideal probability distribution and for connecting it with classical computational hardness and easiness of the sampling task preformed by the quantum computer. We devoted a post to the paper by Xun Gao et al. where we also mention a more recent paper by Aharonov et al.
Update: Here is a very interesting very recent paper on random circuit sampling Incompressibility and spectral gaps of random circuits, by Chi-Fang Chen, Jeongwan Haah, Jonas Haferkamp, Yunchao Liu, Tony Metger, and Xinyu Tan, and a related paper by Lucas Gretta, William He, and Angelos Pelecanos, More efficient approximate k-wise independent permutations from random reversible circuits via log-Sobolev inequalities. There are interesting (speculative) connections between random quantum circuits and black holes.
Anticoncentration and some findings of the new paper
A central problem studied in the new paper is
Do random quantum circuits, under the influence of physically motivated noise models, anticoncentrate?
Anticoncentration means that the distribution is not concentrated on a sufficiently small number of outcomes and it is an important property for RCS samples under basic noise models. In mathematical terms, if the probability for a bitstring 


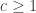

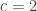
In the words of the authors, what the new paper shows is that
“In this work, we answer this question in the negative: we show how random quantum circuits, under noise models inspired by real hardware, which is a mixture of both unital and non-unital noise of certain types, exhibit a lack of anticoncentration, regardless of the depth of the circuit. This shows that the output distribution does not resemble the uniform distribution, or close variants of the same. Interestingly, we find that this behaviour is exhibited even when there are also unital noise sources, like the depolarizing noise, present in the system, whose property is to push the system towards the maximally mixed state — which, when measured in the standard basis, gives the uniform distribution. In this sense, these non-unital sources ”dominate” the other sources.
(In mathematical terms this means that the effect of non-unital noise is that 

Rethinking computational hardness and easiness
According to the authors a key takeaway of the results is that we need to think carefully about new techniques to prove asymptotic easiness or hardness for random circuit sampling with constant noise rates. Existing techniques for both make strong assumptions on the nature of noise present — for instance, modeling the noise as completely depolarizing — which is unsatisfactory, because these techniques are very sensitive to such assumptions and break down for more realistic noise models. The paper suggests that the moment realistic noise models come into play, the true complexity of random circuit sampling is still an unresolved open question.
Relevance to the statistical analysis and the concerns regarding the Google 2019 experiment
In the past few years, Yosi Rinott, Tomer Shoham and I were engaged in a comprehensive statistical study of the Google’s 2019 quantum computer experiment. We wrote four papers:
- Y. Rinott, T. Shoham, and G. Kalai, Statistical Aspects of the Quantum Supremacy Demonstration, Statistical Science (2022)
- G. Kalai, Y. Rinott and T. Shoham, Google’s 2019 “Quantum Supremacy” Claims: Data, Documentation, & Discussion (see this post).
- G. Kalai, Y. Rinott and T. Shoham, Questions and Concerns About Google’s Quantum Supremacy Claim (see this post).
- G. Kalai, Y. Rinott and T. Shoham, Random circuit sampling: Fourier expansion and statistics. (this post)
The new paper by Fefferman et al. is related to this statistical study and in particular to bias toward ‘0’ for the experimental bitstrings. It appears that the phenomena described in the paper of bias toward ‘0’ as a consequence of non-unital gate errors is not witnessed in the Google experimental data.
This reminds me of the the paper by Xun Gao et al, which influenced our fourth paper. The story is similar: theoretical analysis suggests that gate errors contribute additional effects of similar mathematical nature to the effect of readout errors. Our paper used Fourier methods and statistical tools to study these effects and showed that these effects of gate errors are confirmed by simulations but are not witnessed in the Google 2019 experimental data.
Asymmetric readout errors
One basic form of errors are readout errors: the probability that a measured qubit will read as ‘0’ instead of ‘1’ and vice versa. For the Google 2019 experiment the paper reports that the the probability 

There are several ways to study the values of
- We can get an estimate on
based on the statistics of 0’s and 1’s in the empirical samples. Namely the expected number of 0s is
. (This gives estimates for individual qubits as well.)
- The Google method was simply to initialize (computational states representing) many known random bitstrings and then simply measure many times. This method provides the values for readout errors for individual qubits, in fact, it gave readout errors for a specific set of qubits
- We developed a statistical method (based on knowing the amplitudes of the ideal circuit) to estimate
Note that the first and third methods accounts not only for bias toward 0 for asymmetric readout errors but also for additional bias toward 0 coming from non unital gate errors that is considered in the new Fefferman et al.’s paper. It appears that Google’s method (item 2) does not involve the effect of non unital gate errors. The raw data for the effect of readout errors as studied in the second item was provided by the Google team in January 2021. (The file type is not supported by WordPress, but if you are interested drop me a comment/email.)
Are non-unital gate errors manifested for the Google 2019 data?
Comparing the different methods for estimating the parameters
- There is a good fit between the readout errors
obtained by Google’s method of item 2 and the fractions of 0s and 1s in the Google experimental samples (item 1).
- For n=12 (and circuit number 0) our MLE estimates for
.
Both these findings show no sign in the Google experimental samples for additional asymmetry between 0s and 1s caused by non-unital gate errors. This finding is quite interesting; it may simply reflect the fact that the non-unital error rates are very low, it may be a genuine finding about NISQ devices, or specific finding about the Sycamore quantum computer, it may be a legitimate effect of the Google’s calibration method, and it may also be an artifact of some methodological problems with the 2019 experiment of the kind suggested by our previous papers (mainly the third paper).
Of course, this may also show some misunderstanding or mistake on my part; and, I asked, a few weeks ago, the Google team’s members (and other participants of our email discussion about the 2019 experiment) on this matter. As always, comments are welcome.
Let me also mention that the dependency of the ratios of 0s and 1s on the location of the bit that is witnessed in the empirical samples does not appear to be manifested in Google readout raw data.
Fourier methods for the asymmetric case
Fourier-theoretical aspects of asymmetric readout errors are quite interesting and are related to 
Soumik Ghosh’s remark: The low and high noise regimes
Soumik Ghosh made the following insightful remark:
“Here’s my perspective on why Google potentially did not see the effect of gate errors in their data, which you write about in your blog post.
There are two noise regimes: low and high. High is when the noise rate is a constant. Low is when the noise rate scales as ~1/n (ie, goes down with system size). These two noise regimes have very different properties (see here for instance: https://arxiv.org/abs/2305.04954).
Implicitly, Google’s claims are in the low noise regime. For their 53 and 67 qubit devices, their noise rates are indeed of the order ~ 1/50 or 1/67. It doesn’t mean they will always be in the low noise regime in the future too, without major technological breakthroughs in noise reduction, but so far, there’s a claim to be made that they probably are.
What our results imply is that if they are ever not in the low noise regime — say if the noise reduction capabilities bottom out and the noise stays a constant with a increase in system size — then they will see effects of gate errors very prominently. This will be true even if they mitigate readout bias.
What if they are always in the low noise regime? Then it’s an open question as to what happens. Theoretically, it is known is that if the noise is purely unital (which is unrealistic), then the entire noise manifests as just a global depolarizing noise in the readout (the so called white noise model: https://arxiv.org/abs/2111.14907). It is an open question as to what happens with realistic non-unital noise models in this regime.”
From my point of view, the distinction between low and high error regimes and Soumik’s remark are very much to the point. The distinction between the low and high error regimes is indeed important from theoretical and practical purposes. In my works on noise sensitivity, I indeed argue that in the high error regime the noisy samples will have a noise stable component (representing low degree Fourier-Walsh coefficients) which represent a very primitive computation and a noise sensitive component (representing high degree Fourier-Walsh coefficients) which does not enable computation at all. In the low rate error regime interesting computation and more importantly the creation of good quality error correcting codes are possible.
My theory predicts that in the intermediate scale the low error regime that allows quantum supremacy and good quality quantum error correcting codes cannot be reached. (See e.g., this post and this paper.)
Let me move now from theory to the matter of scrutinizing the Google 2019 experiment and other NISQ experimental assertions. To check the effect of non-unital gate noise on the ratio of zeroes and ones for the Google experiments we probably need to run simulations with the noise parameters of the experiment. I hope that the Google team, other teams involved in the 2019 experiment, like those from NASA, and teams involved in other recent NISQ experiments will double-check this matter by themselves.

I have some interesting ideas that might plausibly enable classical computers that could far outperform quantum computers even if suitable error correction methods would otherwise enable quantum supremacy. I have not yet developed these concepts in detail but have given them a bit of thought.
Thanks for the excellent post, Gil!
Just to add a little bit more to your discussion about the relation between statistical tests to test for non-unital noise in Google’s experiment and our results, Bill and I had a quick observation.
A specific type of non-unital noise that causes 0s to be more favored than 1s is amplitude damping. However, there could be other types of non-unital sources with very different properties, or, hypothetically speaking, it could be that there is no readout error and the circuit terminates with a layer of noiseless gates.
By our results, anti-concentration would still not be satisfied for any of these models. However, we may need a different test to test for the noise — what is reasonable for amplitude damping, ie, testing if 0s are more favored, may not work for this case.
Hi Soumik, and Bill.
Thanks for interesting comment. Our statistical study supports your “anti-concentration” hypothesis. This is studied by the estimator “ ” in Section 4.7 of our first paper. (We considered a normalized version “
” in Section 4.7 of our first paper. (We considered a normalized version “ “, for non Porter-Thomas ideal distributions in our fourth paper.) It looks that
“, for non Porter-Thomas ideal distributions in our fourth paper.) It looks that 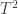 is an estimator for
is an estimator for  in your formulas.
in your formulas.
Our estimator “T” is closely related to the notion of speckle purity benchmarking (SPB) from the supplement to the Google 2019 paper, Section VI.C.4, and especially equation (49) there. (This estimator was used inthe Google experiment for circuits of 2-qubits and was not computed for the experimental samples.) It is related to a source of noise that is described in the Google 2019 paper, and it is worth looking at it.
We study this matter further in Section 3.3 of our third paper. Judging from Table 1 of our third paper it seems reasonable that is not bounded as a function of the number of qubits, (Perhaps
is not bounded as a function of the number of qubits, (Perhaps  grows even linearly with
grows even linearly with  ), as you predict.
), as you predict.
Two remarks:
1) From what I understand from your paper the specific non-unital gate errors for Google experiment should probably manifest larger percent of ‘0’s beyond the readout errors. As another sanity-test for the Google experimental data, this deserved to be carefully checked.
2) We showed in our first paper (e.g. Section 4.3) that the XEB estimator is robust under additional such forms of noise (and this confirmed assertions from the Google paper).
Thanks for the very insightful discussion, Gil, on behalf of both Bill and myself. It was very helpful!