
In a recent post we discussed Google’s claim of achieving “quantum supremacy” and my reasons to think that these claims will not stand. (See also this comment for necessary requirements from a quantum supremacy experiment.) This debate gives a good opportunity to discuss some conceptual issues regarding sampling, probability distributions, statistics, and computational complexity. This time we will discuss chaotic behavior vs. robust experimental outcomes.
On unrelated matter, I just heard Shachar Lovett’s very beautiful TCS+ lecture on the sunflower conjecture (see this post on the Alweiss, Lovett, Wu, and Zhang’s breakthrough). You can see the lecture and many others on the TCS+ you tube channel.

Slide 30 from my August, ’19 CERN lecture: predictions of near-term experiments. (Here is the full powerpoint presentation.) In this post we mainly discuss point b) about chaotic behavior. See also my paper: The argument against quantum computers.
Consider an experiment aimed for establishing quantum supremacy: your quantum computer produced a sample 



But, is it possible that all the distributions 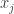
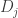
Here are a couple of questions that I propose to think about:
- How do we test robustness?
- Do the supremacy experiments require that the experiment is robust?
- If, after many samples, you reach a probability distribution that require exponential time on a classical computer should you worry about the question whether the experiment is robust?
- Do the 10,000,000 samples for the Google 53-qubit experiment represent a robust sampling experiment?

It seems that if you argue that the sampling experiment was not robust, then the experimenters would respond, “Then how do you explain the fact that the experiment got such a low p-value?”
Then one could answer that perhaps the different distributions $D_i$ average to the ideal distribution (from quantum mechanics), which would explain the low p-value (1 in several million). And if so and if each of the different distributions are easy for a classical computer to compute, then this would prove that the experiment did not demonstrate quantum supremacy and it is easy to spoof the results with a classical computer.
The big question is “would the different distributions average to the ideal distribution?” Answering this question might be tricky, since we are dealing with the squares of exponentially many sums of complex numbers.
Thinking about this more, I don’t see how going this route will lead to a debunking of Google’s experiment – if the million or so different distributions D_i indeed would average to the ideal quantum distribution and the different distributions are easy for a classical computer to simulate, then we would have a recipe for efficiently simulating the random quantum circuit on a classical computer by just picking D_i at random and just simulating D_i on the classical computer, which would contradict the universal belief that random quantum circuits are impossible to efficiently simulate on a classical computer.
I hope Gil can debunk Google’s experiment, because unfortunately I don’t know how to debunk it.
Craig, the present post is not about debunking Google’s claims but about raising the interesting issue of robust vs chaotic experimental outcomes.
How do we test robustness?
We develop a statistical test T which (assume this for a moment) intended to test if the resulting distribution is “close enough” (whatever this means) to D. In fact, T is just a deterministic program with input k strings and output Yes or No. We then repeat the test N times. If the answer is always “Yes”, then we can conclude that the experiment is “robust”. It still may be that the distributions Di are different, but, “not too much” different.
Do the supremacy experiments require that the experiment is robust?
No. Assume now that the results are from very different distributions Di, and the outcome is not close to any fixed distribution D. But assume that we still have some test T such that the outcome passes T with high probability. This time T does NOT tests “closeness” to D, it is just an arbitrary (but explicitly presented) deterministic program with input k strings and output Yes or No. Most importantly, assume also that no efficient classical algorithm is known to generate the distribution that consistently passes T. Then we have a task “to pass test T” which quantum computer can solve efficiently, and classical – cannot, hence, by definition, we have quantum supremacy.
If, after many samples, you reach a probability distribution that require exponential time on a classical computer should you worry about the question whether the experiment is robust?
The experiment may be not robust in sense that each outcome comes from very different distributions Di not close to any fixed distribution D. However, it still should consistently pass our test T.
Do the 10,000,000 samples for the Google 53-qubit experiment represent a robust sampling experiment?
I assume the following. Google can do mistakes but they do not intentionally lie. Because they can do mistakes their experiment is possibly non-robust. But, because they do not lie, I am confident that the output of the experiment consistently passes the test T they developed. Hence, their experiment is a demonstration of quantum supremacy if and only if there is no efficient classical algorithms whose output consistently passes T as well.
I agree.
Nice answer!
I’m more concerned with the fact “qubits” don’t really exist. Preskill himself says they are just continuously varying and that the noise is not only environmental: https://www.youtube.com/watch?v=o3hHO3S8Unk&feature=youtu.be&t=1850
Doing some silly quantum experiment and getting back quantum mechanics isn’t really surprising; the same distribution can be achieved with an AQS. It can hardly be called supremacy. The real question is if these computations can be digitized and this seems unlikely, given the assumptions that go into the threshold theorem: “It seems likely that the (theoretical) success of fault-tolerant computation is due not so much to the ‘quantum tricks’, but rather to the backdoor introduction of ideal (flawless) elements in an extremely complicated construction.” https://arxiv.org/pdf/quant-ph/0610117.pdf
“A useful quantum computer needs to process a set of continuous parameters that is larger than the number of subatomic particles in the observable universe.” They have still to demonstrate a FULLY error-corrected qubit. Let’s say I’m skeptical. https://spectrum.ieee.org/computing/hardware/the-case-against-quantum-computing
As for the first question on how do we test robustness. For small values of n (10,12,16, 20) I would compare the outcomes of two distributions described by two samples. The samples should be rich enough to describe well the underlying distribution.
As for the second and third (very related) questions, here is an example to think about (nothing is quantum here): Suppose you have a computer with 1,000,000 bits of memory; You consider a set A of n bits. (Suppose that n is in the 20-100 range). Now suppose you sample 1000 times a second for a year the states of these bits and collect the data.
Ok so here are some more details. (Not related to the Google story). If you show that some strings of 0-1 bits represent something that requires millions of CPU years then robustness does not matter. But if you base a supremacy argument on extrapolation: that you need say steps on a classical computer when n is 10,15,20,25 then you need to demonstrate also robustness. Without robustness a sample of 10-25 from your set A may represent a polynomial process on the entire computer (where the relevant n is 10^6.).
steps on a classical computer when n is 10,15,20,25 then you need to demonstrate also robustness. Without robustness a sample of 10-25 from your set A may represent a polynomial process on the entire computer (where the relevant n is 10^6.).
As for the Google experiment. Checking robustness (namely comparing two distinct samples) is not relevant to the specific statistical goal, but in my opinion it should be checked as part of such an experiment (like the comparison of the full distributions).
As for Bogdan’s answer: a) I think T is simply the cross entropy test. b) Bogdan wrote: “I am confident that the output of the experiment consistently passes the test T they developed.” No, the researchers don’t compute T for the 53 bits samples because 53 is too large. (In fact as far as I can see they do not carry any statistical test on this sample.) They infer that the 53-bit samples will pass T by a certain (incorrect) extrapolation.
Pingback: Gil’s Collegial Quantum Supremacy Skepticism FAQ | Combinatorics and more