
Update: After the embargo update (Oct 25): Now that I have some answers from the people involved let me make a quick update: 1) I still find the paper unconvincing, specifically, the few verifiable experiments (namely experiments that can be verified classically) cannot serve as a basis for the larger experiments that cannot be classically verified. 2) Many of my attempts to poke hole in the experiments and methodology are also incorrect. 3) In particular, my suggestion regarding the calibration That I express with much confidence at the beginning of the post goes against the basic strategy of the researchers (as they now clarified) and the detailed description in the supplement. 4) I will come back to the matter in a few weeks. Meanwhile, I hope that some additional information will become available. Over the comment section you can find a proposal for a “blind” test that both Peter Shor and I agree to. (If and when needed.) It would respond to concerns about “cross-talk” between the classical computations and quantum computation during the experiments, either via the calibration method or by other means.
Original post (edited):
Here is a little update on the Google supremacy claims that we discussed in this earlier post. Don’t miss our previous post on combinatorics.
Recall that a quantum supremacy demonstration would be an experiment where a quantum computer can compute in 100 seconds something that requires a classical computer 10 hours. (Say.)
In the original version I claimed that: “The Google experiment actually showed that a quantum computer running for 100 seconds PLUS a classic computer that runs 1000 hours can compute something that requires a classic computer 10 hours. (So, of course, this has no computational value, the Google experiment is a sort of a stone soup.)” and that: “The crucial mistake in the supremacy claims is that the researchers’ illusion of a calibration method toward a better quality of the quantum computer was in reality a tuning of the device toward a specific statistical goal for a specific circuit.” However, it turned out that this critique of the calibration method is unfounded. (I quote it since we discussed it in the comment section.) I remarked that “the mathematics of this (alleged) mistake seems rather interesting and I plan to come back to it (see at the end of the post for a brief tentative account), Google’s calibration method is an interesting piece of experimental physics, and expressed the hope that in spite of what appears (to me then) to be a major setback, Google will maintain and enhance its investments in quantum information research. Since we are still at a basic-science stage where we can expect the unexpected.”
Detection statistical flaws using statistics
Now, how can we statistically test such a flaw in a statistical experiment? This is also an interesting question and it reminded me of the following legend (See also here (source of pictures below), here, and here) about Poincaré and the baker, which is often told in the context of using statistics for detection. I first heard it from Maya Bar-Hillel in the late 90s. Since this story never really happened I tell it here a little differently. Famously, Poincaré did testify as an expert in a famous trial and his testimony was on matters related to statistics.
The story of Poincaré and his friend the baker
“My friend the baker,” said Poincaré, “I weighed every loaf of bread that I bought from you in the last year and the distribution is Gaussian with mean 950 grams. How can you claim that your average loaf is 1 kilogram?”

“You are so weird, dear Henri,” the baker replied, “but I will take what you say into consideration.”*
A year later the two pals meet again
“How are you doing dear Henri” asked the baker “are my bread loaves heavy enough for you?”
“Yes, for me they are,” answered Poincaré “but when I weighed all the loaves last year I discovered that your mean value is still 950 grams.”
“How is this possible?” asked the baker
“I weighed your loaves all year long and I discovered that the weights represent a Gaussian distribution with mean 950 grams truncated at 1 kilogram. You make the same bread loaves as before but you keep the heavier ones for me!”

“Ha ha ha” said the baker “touché!”** and the baker continued “I also have something that will surprise you, Henri. I think there is a gap in your proof that 3-manifolds with homology of a sphere is a sphere. So if you don’t tell the bread police I won’t tell the wrong mathematical proofs police :)” joked the baker.
The rest of the story is history, the baker continued to bake bread loaves with an average weight of 950 grams and Poincaré constructed his famous Dodecahedral sphere and formulated the Poincaré conjecture. The friendship of Poincaré and the baker continued for the rest of their lives.
Epilogue
(Added, Dec 27, 2019).
“What?” asked the superintendent
“I think that this was an innocent mistake in the calibration method of weighting the bread” said Henri, and continued: “I found a beautiful mathematical explanation for how this could happen.” Henri was happy that he could simultaneously help his friend the baker, and brag about his mathematical skills. He truly believed in his calibration theory.
“I am working at the bakery since the age of 12 and I am surprised how ignorant Henri is about what we do.” said the baker and continued “There was no such mistake in the calibration method. and no baker in the world can make such a mistake” .
“Oh Benoît, Benoît,… merde…” thought Henri (in French)
* “There are many bakeries in Paris” thought the baker “and every buyer can weight the quality, weight, cost, and convenience”.
** While the conversation was originally in French, here, the French word touché is used in its English meaning.
The mathematics of such a hypothetical calibration in a few sentences.
The ideal distribution 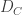

The first order effect of the noise is to replace 


The second order effect of the noise is adding a Gaussian fluctuation described by Gaussian-distributed probabilities 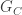
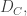
For low fidelity, as in our case, the calibration mainly works in the range where
Technical update (Nov 18): Actually, some calculation shows that even with a hypothetical calibration toward noisy
Trivia question: what is the famous story where a mathematician is described as objecting to children dreaming.
Answer to trivia question (Nov 15, 2019).
The famous story is the Happy Prince by OSCAR WILDE
“He looks just like an angel,” said the Charity Children as they came out of the cathedral in their bright scarlet cloaks and their clean white pinafores.
“How do you know?” said the Mathematical Master, “you have never seen one.”
“Ah! but we have, in our dreams,” answered the children; and the Mathematical Master frowned and looked very severe, for he did not approve of children dreaming.
A famous sentence from the story is:
“Swallow, Swallow, little Swallow,” said the Prince, “will you not stay with me for one night, and be my messenger?

Are you sure this is what they did? If so, can you point me to the relevant passages in their paper/supplementary material? I would have assumed they ran the circuit for different U using the same calibration…
Hi Marco, I think that the logic of the paper regarding the calibration is mainly incoherent. If the effect of the calibration w.r.t. one random circuit C was to improve the fidelity of the QC then they could indeed run it after calibration on another random circuits D. But there is no claim or evidence in the paper (or an earlier one) that this should lead to good match for D. (This certainly can be tested on small number of qubits.) Without such a claim the logic behind the calibration process is unclear. (Even with such a claim, you still need to justify why computationally you gain anything).
(I vaguely remember seeing in the paper that they considered starting with a circuit C and changing just the 1-qubit gates. But I don’t remember where and in what context.)
Thanks – I agree that if they do as you suggest than that appears highly problematic. If they do the calibration and then do a full alphabet of random circuits with the same calibration I would not see a problem though. It is too bad we have to wait until the Google team can properly explain themselves.
Hi Marco,
Here is the basic Figure referring to Google’s calibration method
Indeed it will be good if the Google team would clarify this issue. To me, the idea of calibrating the qubits and gates based on the performance of the system for circuits with many layers and many qubits seems a priori strange.
If it is agreed that calibrating the system based on knowledge of the target circuit (for the supremacy experiment) is problematic, then the best (and standard) way to convince the scientific community that the test is appropriate would be to decide on a number of qubits (in the top range where the experiment could be tested) and then, once the QC is calibrated, to let it run on a previously unknown random circuit. So a third party will give the Google team the details of one or several circuits to be tested, these circuits are unknown to the Google people in advance, and neither the Google people nor the third party classically computed the desired outcome beforehand (or during the experiment).
If the Google team disagrees with us that calibrating the system based on knowledge of the target circuit (for the supremacy experiment) is problematic, then of course they need to justify this methodology.
Buffon’s needle computes π. So is it a computer?
Is Google aware of this post? If they are and if they cannot respond to it reasonably, they should tell their publisher to “Stop the press!” so that it does not become another Cold Fusion story. I am amazed that you are saying that Google likely made the same mistake as the Bible Codes folks (just as I suggested they might have in my previous post here: https://gilkalai.wordpress.com/2019/09/23/quantum-computers-amazing-progress-google-ibm-and-extraordinary-but-probably-false-supremacy-claims-google/#comment-60998).
Craig, please see the update of my previous post. The people from Google are certainly aware of my technical points. You indeed suggested in a comment that we should look at the calibration which was not my first priority at the time. Kudos!
There is a Hebrew saying that says “do not mix joy with joy” (אין לערבב שמחה בשמחה), and as you certainly realized I am not happy to discuss comparisons with the Bible code episode (and not with “cold fusion”).
I do think that the Google team should address these concerns among themselves and if indeed the supremacy is (or might be) just a stone soup phenomenon they should (perhaps after further experiments if needed) revise the paper accordingly (or retract it).
I don’t see this as mixing joy with joy. I wanted the Bible code stuff to be proven correct.
Gil, you don’t seem like the religious type, but speaking of the Bible, here is a Bible verse that proves that large scale quantum computers cannot possibly exist:
מַה-שֶּׁהָיָה, הוּא שֶׁיִּהְיֶה, וּמַה-שֶּׁנַּעֲשָׂה, הוּא שֶׁיֵּעָשֶׂה; וְאֵין כָּל-חָדָשׁ, תַּחַת הַשָּׁמֶשׁ. “That which hath been is that which shall be, and that which hath been done is that which shall be done; and there is nothing entirely new under the sun.” Ecclesiastes Chapter 1:9.
GK: Craig, the problem with what you say is that it also “proves” that evolution theory, quantum physics itself, etc. etc. cannot possibly exist. Also your translation is incorrect and the word “entirely” should be omitted.
Gil, I agree that it is normally translated “nothing new under the sun”. But doesn’t the kol-chadash mean “entirely new”? If not, then what does the kol mean?
You can think about it as “no anything new under the sun”
OK, that makes sense. Thank you Gil. I’m not a native Hebrew speaker, but love the Hebrew language.
Pingback: Quantum computers: amazing progress (Google & IBM), and extraordinary but probably false supremacy claims (Google). | Combinatorics and more
Hi Gil,
It seems to me that in this blog post, you are admitting that your theory of quantum computation being derailed by noise inherent in quantum gates is wrong. Because if the noise were unavoidably inherent in quantum gates, then no amount of classical precomputation and calibration should be able to reduce it.
I admit that spending thousands of hours of classical computer time to calibrate a quantum computer so as to do a computation that takes only ten hours on a classical computer is indeed ironic. But did you expect a proof-of-principle experiment to actually produce useful results?
Hi Peter, thanks for your comment.
We need to distinguish between two types of calibrations:
Calibration of type (A): We spend much (classical) computer time and engineering efforts to optimize the computer parameters and improve the quantum computer and then we are able to run a fresh new random circuit C so it passes the statistical test.
Calibration of type (B): Given a specific random circuit C, we spend much (classical) computer time and engineering efforts (geared toward the circuit C) to optimize the computer parameters and then we are able to run the circuit C so it passes the statistical test.
What you say is correct for a calibration of type (A) but is incorrect for a calibration of type (B). The Google research is (apparently) based on many calibrations of type (B) and they do not claim, and as far as we know unable to achieve a calibration of type (A).
Calibrations of type (B) (based on massive classical computation) have no value as a proof-of-principle for quantum advantage of any kind. This is the major mistake of the Google team.
A main point of my post is to raise the riddle on how to tell statistically from the data that the success of the statistical test is based on a calibration of type (B) (like in the baker story). The brief mathematical part at the end of the post offers a picture of the mathematics related to calibration of type (B).
(As an aside, the Google paper claims that a certain sampling for a 53 qubit QC requires 10,000 years of classical computer time and this is flawed even with a successful calibration of type (A) on a smaller number of qubits.)
The Google’s type-(B) calibration method have thus no bearing on my “theory of quantum computation being derailed by noise is inherent in quantum gates”. The method also have no bearing on the more common view that asserts that demonstration of quantum supremacy or of high-quality quantum error-correction still requires substantial improvement of the quality of qubits and gates, that the Google’s gymnastics can neither achieve nor replace.
Hi Gil,
I don’t see why it matters how the calibrations were done. After the calibrations were done, Google had a quantum computer that was able to sample from a distribution that no classical computer (no matter how you calibrated it) would be able to sample from in reasonable computation time. Or at least, the best algorithms known for classical computers for sampling from this distribution take much longer than the quantum computer did.
Dear Peter,
You wrote: “After the calibrations were done, Google had a quantum computer that was able to sample from a distribution that no classical computer (no matter how you calibrated it) would be able to sample from in reasonable computation time.”
No, this is absolutely not the case.
You have to distinguish between sampling that Google performed for circuits with 30-40 qubits where they could compute their statistical test and sampling that was reported for 53 qubits.
As it seems, for 30-40 qubits Google performed a sampling for a circuit C where the calibration used a classical computation of the probabilities for the same (noiseless) circuit C. In this case the computational task that Google performed could be done by a classical computer in a reasonable time, and in fact the calibration was based on carrying this computation and tweaking the quantum computer towards the desired outcome.
For 53 qubits indeed Google claims that they have few millions samples from a distribution that no classical computer would be able to sample from in reasonable computation time. But this claim is simply baseless, it is not supported by any statistical test, and it is based on a wrong extrapolation argument. (As far as we know no statistical test was performed on these samples of length 53 and they were just stored to the computer.)
Hi Gil,
The paper is now out, so I can ask this question. Where in the paper does it say that Google tuned the calibration using the proper output probabilities? Many thanks,
Peter
Peter, please have a look at the thread of discussion I had with Marco Tomamichel on this matter. (On the top of the comment section.)
Here is the basic Figure referring to Google’s calibration method
Here is the author’s description: “Process flow diagram for using XEB to learn a unitary model. After running basic calibrations, we have an approximate model for our two-qubit gate. Using this gate, we construct a random circuit that is fed into both the quantum computer and a classical computer. The results of both outputs can be compared using cross-entropy. Optimizing over the parameters in the two qubit model provide a high-fidelity representation of the two-qubit unitary.”
This could be legit (while strange) if after a calibration process toward one circuit Google will run their experiments toward entirely fresh circuits. As far as I can see the paper is not clear about it and the logic of the paper regarding the calibration is incoherent.
I agree that you might be able to interpret that figure caption the way you do in your blog post. But Google also says in the paper, “Lastly, we design our calibration to be done almost entirely at the single- or two-qubit level, rather than at the system level, in order to be as scalable as possible,” which seems to argue against that interpretation.
Today is a turning point in this discussion for two reasons. First, that the Google/Martinis paper finally appeared in Nature and it is much easier to have a full discussion. Second, that for the first time you (Gil) referred to a specific part of one of the papers, namely Figure S11 in the draft supplement or S15 in the published version, in order to make your case against the Google results.
You wrote:
However, Figure S11/S15, and as far as I know the calibration section, Section VI of the supplement, does not refer to circuits acting on 30 to 40 qubits. Instead, the figure describes a two-qubit calibration circuit. Most of the calibration section describes separate calibration for individual qubits and pairs of qubits using circuits local to only those one or two qubits. Only later, in Section VI.C.5, do they start to discuss whole-chip calibration, and even then they only calibrate individual circuit layers, not the whole circuit. In this subsection, they say specifically:
Then in Figure S15/S19, they show their plan to test each of their four layers separately. As the figure shows, for each layer, they repeat that layer m times to make 22 or 23 two-qubit circuits running in parallel. That is as close as they ever get to whole-circuit calibration.
Peter, perhaps we can agree that a good (and standard) way to proceed regarding the concern about system-level calibration is to run a blind test: After deciding on a number of qubits (in the top range where the experiment could be classically tested and perhaps also a bit above it) then we let the Google team calibrate their quantum computer, and once the Google quantum computer is calibrated, to let it run on a previously unknown random circuit.
So when the Google people announce that they are ready, a third party will give the Google team the details of one or several circuits to be tested. (These circuits will be unknown to the Google people beforehand.) As the running time of the quantum computer is just a few hundreds seconds the quantum computer could produce the samples rather quickly. Only after the samples will be produced the classical probabilities will be computed and the statistical test will be performed.
I would agree.
I have the impression that, to work as well as it did, the calibration needed some information on which gates were used, and which gates were operating near which other gates. But I assume you wouldn’t object if the Google people had this information in advance as long as it didn’t narrow down the possible circuits too much.
Pingback: Google's quantum supremacy is only a first taste of a computing revolution - CNET - Ranzware Tech NEWS
Thoughtful concerns regarding the calibration process in the Google experiment were raised by Till (comment #30 in this post on SO) and where discussed in subsequent comments. (See especially the comment of Craig Gidney and that of Sergio Boixo, and Till’s follow up comment #37, #38, #41, and #43.) It turns out that the experiments were conducted not for standard gates but for (slightly) modified gates (“native” gates) that were selected based on the calibration stage. (Those are still universal and allow the same “composite gates” as the standard gates.) There is also an explanation by John Martinis on how the fidelity can further be improved based on further analysis regarding the 2-gates. (Related to Figure S43 (S42 in v.1.)) in the supplement to Google’s paper.)
Gidney’s remark proposes protocols for experiments which is quite similar to the one Peter Shor and I agreed about.
“Basically, in an ideal experiment, the circuit to execute would be generated by a referee and then run by the quantum machine as well as the classical machine. Instead, the quantum machine was saying “here are the operations I can do the best right now for each pair of qubits” and then the referee was picking a circuit that used those operations. This means that if you wanted to run the circuits again at a later date, the quantum hardware would underperform since its calibrated gates would differ slightly.”
Pingback: Google's quantum supremacy is only a first taste of a computing revolution - Das Blog
Pingback: Ordinary computers can beat Google’s quantum computer after all | Combinatorics and more
Pingback: Greatest Hits 2015-2022, Part II | Combinatorics and more