

A 2017 cartoon from this post.
After the embargo update (Oct 25): Now that I have some answers from the people involved let me make a quick update: 1) I still find the paper unconvincing, specifically, the verifiable experiments (namely experiments that can be tested on a classical computers) cannot serve as a basis for the unverifiable fantastic claims. 2) Many of my attempts to poke hole in the experiments and methodology are also incorrect. 3) In particular, my suggestion regarding the calibration goes against the description in the supplement and the basic strategy of the researchers. 4) I will come back to the matter in a few weeks. Meanwhile, I hope that some additional information will become available. Post rearranged chronologically.
Some main issues described in the post and also this critique was brought to the attention of John Martinis and some of the main researchers of the experiment on October 9, 2019.
(Oct 28, 2019) The paper refers to an external site with all the experimental results. Here is the link https://datadryad.org/stash/dataset/doi:10.5061/dryad.k6t1rj8. In my view, it will be valuable, (especially, for an experiment of this magnitude) if there will be an independent verification of the statistical computations.
(October 23, 2019). The paper (with a supplementary long paper) is now published in Nature. The published versions look similar to the leaked versions.
Original post: For my fellow combinatorialists here is the link to the previous post on Kahn-Park’s result, isoperimetry, Talagrand, nice figures and links. Quick update (Sept. 27) Avi Wigderson’s book is out!
Recent quantum computer news
You already heard by now that Google (informally) announced it achieved the milestone of “quantum supremacy” on a 53 qubit quantum computer. IBM announced launching in October a quantum computer also on 53 of qubits. Google’s claim of quantum supremacy is given in two papers from August that were accidentally leaked to the public. Here are links to the short main paper and to the long supplementary paper. The paper correctly characterizes achieving quantum supremacy as an achievement of the highest caliber.
Putting 50+ qubits together and allowing good quality quantum gates to operate on them is a big deal. So, in my view, Google and IBM’s noisy quantum circuits represent a remarkable achievement. Of course, the big question is if they can do some interesting computation reliably, but bringing us to the place that this can be tested at all is, in my view, a big deal!
Of course, demonstrating quantum supremacy is even a much bigger deal, but I expect that Google’s claim will not stand. As you know, I expect that quantum supremacy cannot be achieved at all. (See this post, this paper A, this paper B, and these slides of my recent lecture at CERN.) My specific concerns expressed in this post are, of course, related to my overall skeptic stance as well as to some technical points that I made in my papers, but they could (and should) have also been made by responsible quantum computer believers.
Achieving quantum supremacy via sampling
In the last decade there were several suggestions to demonstrate the computational superior power of quantum circuits via sampling tasks. The computer creates (approximately) a probability distribution D on 0-1 strings of length n (or other combinatorial objects) that we have good computational complexity reasons to think that classical computers cannot achieve. In our case, D is the probability distribution obtained by measuring the outcome of a fixed pseudo-random quantum circuit.
By creating a 0-1 distribution we mean sampling sufficiently many times from that distribution D so it allows us to show that the sampled distribution is close enough to D. Because of the imperfection (noise) of qubits and gates (and perhaps some additional sources of noise) we actually do not sample from D but from another distribution D’. However if D’ is close enough to D, the conclusion that classical computers cannot efficiently sample according to D’ is plausible.
How to run supremacy sampling experiment
You compare the distribution E obtained by the experiment to the ideal distribution D for increasingly larger values of n. If there is a good match this supports your supremacy claims.
There are two important caveats:
- A single run of the quantum computer gives you only one sample from D’ so to get a meaningful description of the target distribution you need to have many samples.
- Computing the ideal distribution D is computationally hard so as n increases you need a bigger and bigger computational effort to compute D.
Still, if you can show that D’ is close enough to D before you reach the supremacy regime, and you can carry out the sampling in the supremacy regime then this gives you good reason to think that your experiments in the supremacy regime demonstrate “quantum supremacy”.
Earlier experiments
The Google group itself ran this experiment for 9 qubits in 2017. One concern I have with this experiment is that I did not see quantitative data indicating how close D’ is to D. Those are distributions on 512 strings that can be described very accurately. (There were also some boson sampling experiments with 6 bosons and 2 modes and 5 bosons with 5 modes. In this case, supremacy requires something like 50 bosons with 100 modes.)
The twist in Google’s approach
The twist in Google’s approach is that they try to compute D’ based mainly on the 1-qubit and 2-qubit (and readout errors) errors and then run an experiment on 53 qubits where they can neither compute D nor verify that they sample from D’. In fact they sample 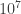
The missing part in the experiment.
The obvious missing part in the experiment is to run the experiment on random circuits with 9-25 qubits and to test the research assumption about D’. I find it a bit surprising that apparently this was not carried out. What is needed is experiments to understand probability distributions obtained by pseudorandom circuits on 9-, 15-, 20-, 25- qubits. How close they are to the ideal distribution D and how robust they are (namely, what is the gap between experimental distributions for two samples obtained by two runs of the experiment.)
Actually, as I noted in the introduction to Paper A (subsection on near term plans for “quantum supremacy” and Figure 3), you can bring the hypothesis of quantum supremacy via pseudo-random circuits into test already in the 10-30 qubit regime without even building 53- or 72- qubit devices. (I can certainly see the importance in building larger circuits that are necessary for good quality error correcting codes.)
The main potential mistake and the matter of correlation.
(Oct 18): In hindsight this section about correlation is not relevant to the Google supremacy story.
Let me also indicate what is a potential mistake in the computation of D’ relying just on the behavior of qubits and gates. This is related to correlated (2-qubit gate) errors that I studied mainly before 2014.
The general picture regarding correlated qubit errors is the following:
(1) Errors for gated qubits (for a CNOT gate) are (substantially) positively correlated.
Here, you can think about the extreme form of “bad” noise where with a small probability t both gated qubits are corrupted and with probability (1-t) nothing happens. (“Good” noise is when each qubit is corrupted with probability t, independently. Real life 2-qubit noise is a certain mixture of good and bad noise.)
(2) Therefore, (unless you are below the threshold level and apply quantum fault tolerance scheme) qubits in cat states that were created indirectly will have correlated noise of this kind.
(3) Therefore (and going from (2) to (3) is a mathematical part) probability distributions described by pseudorandom circuits will have a strong effect of synchronized errors.
What is most devastating about correlated errors is that the accumulated error-rate in terms of qubit errors becomes quadratic in the number of rounds instead of linear. See Remark 4.2 about “model error-rate” and “effective error-rate” in Paper A.
My predictions.
Let me mention that Paper B describes fairly detailed predictions about probability distributions obtained by pseudo-random circuits and these predictions can be tested in the 9-25 qubits range. In particular, they suggest that robust outcomes will be easy to simulate classically, as they belong to a very low level (LDP) computational complexity class, and that noise sensitivity will lead to chaotic outcomes which are far from the ideal distribution.
A problem with the supremacy statements itself.
On Google Cloud servers, we estimate that performing the same task for m = 20 with 0.1% fidelity using the SFA algorithm would cost 50 trillion core-hours and consume 1 petawatt hour of energy. To put this in perspective, it took 600 seconds to sample the circuit on the quantum processor 3 million times, where sampling time is limited by control hardware communications; in fact, the net quantum processor time is only about 30 seconds.
It is not clear where these fantastic numbers come from. They refer to a specific algorithm and there might be some vague reason to think that this algorithm cannot be improved for D or near by distributions. But, for example, for the probability distribution I predict this algorithm is extremely inefficient and the sampling can be carried out efficiently.
Distance-3 surface code
In 2013 I was one of the organizers of a conference Qstart celebrating our then new Quantum Science Center. John Martinis gave a lecture where he mentioned building distance-3 surface codes on 20+ qubits as a (then) near term task. My argument against quantum computers does not give a definite prediction whether distance-3 surface codes are within or beyond reach and it would be interesting to examine it.
Conclusion
It looks that Martinis’ groups announcement of supremacy, while based on a remarkable experimental progress, was premature and in my view it is mistaken. (To be fair, the papers themselves were prematurely released.) This post was also written rather quickly so I will certainly have to think about matters further, perhaps also in view of more careful reading of the papers, some comments by members of the Google group themselves and other people, and also Scott Aaronson promised to write about it.
Links and updates
My papers and early posts
Paper A: Three puzzles on mathematics computations, and games, Proc. Int
Congress Math 2018, Rio de Janeiro, Vol. 1 pp. 551–606.
Paper B: The argument against quantum computers, To appear in: Hemmo, Meir and Shenker, Orly (eds.) Quantum, Probability, Logic: Itamar Pitowsky’s Work and Influence, Springer, Nature (2019), forthcoming
Paper C: The quantum computer puzzle, Notices AMS, May 2016
my ICM 2018 videotaped lecture (Also about other things)
My videotaped CERN 2019 lecture (I am not sure how well it works) and the slides.
A cartoon-post from 2017: If quantum computers are not possible why are classical computers possible?
The authors

Whether it stands or refuted the Google paper represents serious multidisciplinary effort, an important moment for the scientists involved in the project, and a notable event in science!
Other links and updates
Scott Aaronson enthusiastic blog post gives his take in the new development and also mentions some several key researchers behind the pursuit of quantum supremacy on NISQ systems. Among the interesting comments on this post: Camille (the effect of non-uniform errors; the tension with Ali Baba’s classicl simulation capabilities); Ryan O’Donnell (Proposing to demonstrate the situation for 20+ and 30+ qubits. Ryan made several additional interesting comments);
Comparing various types of circuits: (Oct, 2) From what I could see one new aspect of the methodology is the comparison between various types of circuits – the full circuit on the one hand and some simplified versions of it that are easier to simulate for large number of qubits.
There is a large media coverage of the claims by Google’s researchers. Let me mention a nice Quanta Magazine article by John Preskill “Why I called it quantum supremacy” on inventing the terms “quantum supremacy” and “NISQ”.
Another blog post by Scott on SO is on a paper published by Nature claiming implementation of a Shor-like algorithm on a classical device. Scott offers a very quick debunking: “ ‘p-bit’ devices can’t scalably outperform classical computers, for the simple reason that they are classical computers.” The gist of my argument against the possibility of achieving quantum supremacy by NISQ devices is quite similar: “NISQ devices can’t outperform classical computers, for the simple reason that they are primitive classical computers.”
Updates (Oct 16):
1) Here is a remark from Oct 10. I thought this is a big deal for a while but then it turned out to be a wrong understanding of the system calibration process. Upon more careful reading of the papers, it seems that there are major issues with two elements of the experiments: the calibration and the extrapolation.
The main mistake is that the researchers calibrate parameters of the QC to improve the outcomes of the statistical tests. This calibration is flawed for two reasons. First it invalidates the statistical test since the rejection of the null hypothesis reflects the calibration process. Second, the calibration requires computational power which is larger than the task they have for the QC. (So its invalidate any claim for quantum advantage.)
The second related mistake is that the researchers extrapolate from behaviors for experiments that they can calibrate (30 or so qubits for the full circuit or 53 qubits for a simplified circuit) to the regime where they cannot calibrate (53 qubits for the full circuit). So even if the calibration itself was kosher, the extrapolation is false and there is no reason to think that the statistical test on the 53-qubits sampled for the full circuit will do as well as they expect it.
Let me add some detail on the main mistake: The crucial mistake in the supremacy claims is that the researchers’ illusion of a calibration method toward a better quality of the quantum computer was in reality a tuning of the device toward a specific statistical goal for a specific circuit. If the effect of the calibration w.r.t. one random circuit C was to improve the fidelity of the QC then they could indeed run it after calibration on another random circuits D. But there is no claim or evidence in the paper (or an earlier one) that this should lead to good match for D. (This certainly can be tested on small number of qubits.) Without such a claim the logic behind the calibration process is fundamentally flawed.
2) Scott Aaronson initiated (email) (See also his comment) (Sept 25) an email discussion between Ryan O’Donnell and me and John Martinis and some of his team. John noted that because of the press embargo they would not like to discuss this much more until the paper is published, and raised the concern that discussions before the embargo is lifted will be leaked. I wrote to John and the groups two emails on October 7 and 9.
3) In the same comment Scott wrote regarding the request for full distributions that he passed to John: “John Martinis wrote back, pointing out that they already did this for 9 qubits in their 2018 Science paper.” Indeed, this paper and some supplementary slide (that John kindly attached) show an impressive match between the empirical and theoretical distributions for 9 qubits. The 2018 Science paper gives a detailed description of the calibration method.
4) It will be valuable if John Matrinis and his team will clarify (publicly) even before the press embargo is lifted, if and in what way does the calibration process depends on the target circuit. (And making it clearer for the 2018 science experiments does not even violate any obligation regarding press embargo of the current paper.)
5) The whole notion of press embargo was new to me, and the inability of the scientific community to discuss openly scientific claims before they are published raises some interesting issues. I tend to think that an obligation toward the publisher does not cancel other obligations the scientists might have especially (but not only) in a case where an early version of the paper had become publicly accessible.

Dare I say a computer without error correction is just an analog computer? QM has always been hard to compute, as are too many billiard balls. https://arxiv.org/pdf/1906.03860.pdf
Beauregard: “We introduce a circuit which uses 2n+3 qubits and O(n^3 lg(n)) elementary quantum gates in a depth of O(n^3) to implement the factorization algorithm.” So 2*2048+3 = 4099 cubits! The linear Hilbert space of n qubits has 2^n complex dimensions and the density operators (Hermitian semipositive with unit trace) have real dimension 2^(2n)−1. Where is the limit?
https://arxiv.org/abs/quant-ph/0205095 https://arxiv.org/abs/1905.09749
And maybe I should cite the 2012 Martinis paper on surface codes: “Here we assume an error rate approximately one-tenth the threshold rate…We can now estimate the number of physical qubits needed for our factoring problem. The 4,000 computational logical qubits require a total of about 4000 × 14,500 = 58 million physical qubits.” Yikes! https://arxiv.org/ftp/arxiv/papers/1208/1208.0928.pdf
And maybe I should cite the 2012 Martinis paper on surface codes: “Here we assume an error rate approximately one-tenth the threshold rate…We can now estimate the number of physical qubits needed for our factoring problem. The 4,000 computational logical qubits require a total of about 4000 × 14,500 = 58 million physical qubits.” Yikes! https://arxiv.org/ftp/arxiv/papers/1208/1208.0928.pdf
Just a note that for boson sampling, you need more like 50^2 modes with 50 photons. This is because the classical complexity is better than 2^n if the number of modes is a constant factor times the number of photons.
Thanks, Raphael, I doubt if 10 bosons with 20 modes is within reach.
You write about “The main potential mistake”, “strong effect of synchronized errors”, etc. However, in my understanding the situation is
1) Google developed a device returning set X of strings in few minutes (they claim that X goes from some distribution D or close to it but this does not really matter)
2) Google developed a classical “test” T with input set of strings and output Yes or No (they claim that test T checks if X is close to a sample from D, but this does not really matter)
3) On input X the test T reruns Yes with high probability (in other words, X passes the test T)
4) Google claims that classically it is practically impossible to generate set X which passes the test T
The best response from sceptics would be an efficient classical algorithm which generates set X which passes the test T.
Excellent comment, thanks! Most importantly, can you explain the test T and/or say where is the best place in the papers to read its description?
When I talked about the “main potential mistake” I referred to the claim (lets call it claim A) that X is very close to D. I think that there are experimental ways to test claim A and that the research claim is incomplete without carrying these experiments. (In addition, there are reasons to doubt claim A.)
You correctly say that claim A does not really matter if we believe in claim 4 that it is classically impossible to generate set X which passes the test T. (A small caveat is that for all I see the argument/intuition behind claim 4 is claim A, am I right?)
You are correct that to refute 4) one needs to generate efficiently a set X which passes the test T. Indeed one way to go about it would be to try to guess what the realistic noise model is, and build X based on it. X can simply be a noisy version of the ideal state with higher rate of noise which accounts for effect of correlated 2-qubit gates.
Of course if we have experimental results on the distributions for small circuits this can either give a hint about a classical X that will pass the test or give some support for claim 4.
Not sure why I named ma3517 in the previous comment, I will now try to comment under my name (Bogdan).
As far as I understand, informal description of Test T is the paragraph with formula (1) in their short paper, starting with words “We verify that the quantum processor is working properly…”. Of course, we need an exact algorithm of how they actually perform the verification and (ideally) also an open-source executable code with implementation.
After this, it would be possible to refute the supremacy claim by producing a classical sample X which pass their test. Of course, your intuition of why claim A is wrong can be a key for producing such X.
If, however, after years of efforts no-one will be able to produce such X classically, and Google can easily produce X using their quantum device, we must accept the supremacy claim, no matter if claim A is correct or not.
Of course, any such acceptance is temporary. At any time someone may develop classical algorithm to produce X (or factor integers, or prove that P=BQP) and the supremacy disappear.
Dear Bogdan, if you trace the best location for test T in the long paper let me know. We can think about it together. Exact formula or algorithm will do.
“After this, it would be possible to refute the supremacy claim by producing a classical sample X which pass their test. Of course, your intuition of why claim A is wrong can be a key for producing such X.”
“If, however, after years of efforts no-one will be able to produce such X classically, and Google can easily produce X using their quantum device, we must accept the supremacy claim, no matter if claim A is correct or not.”
OK, let me say something about it that refers also to Scott’s comment 52. Proving quantum supremacy is a major scientific event, in my view, in the caliber of the Higgs discovery or something like that. It is not a game between the authors and the skeptics where the skeptics (or referees that need to be skeptical) have to prove that the authors are wrong. ALL the claims matter. If the author claim that X is close to D they need to justify and show that X is close to D. Failing to do so reduced severely the scientific quality of the paper. T should be motivated and studied, and the intuition that fooling T is intractable should be justifies. If this hardness intuition is based on X being close to D and X is not close to D this is a major flaw. The years of efforts to produce X classically and to poke hole in the argument need to be carried out mainly by the authors and not by skeptics.
And to this end it goes without saying that here “skeptics” refer to the entire community not to people who are skeptics about the entire quantum computer endeavor. The fact that people in the community share a point of view similar to your comment just like Scott’s early victory celebrations (and also some choices and rhetoric of the paper) are not encouraging signs to the ability of the community to handle critically and professionally claims of this magnitude.
As I said, in my view, the claims will eventually not stand (but I dont see a need to retract the paper itself). And, in particular, X will not be closed to D. (Which is consistent with what other experts generally think about the quality of current gates and qubits in superconducting qubits.) So the path to real progress is via better qubits and better gates which most people regard as possible and even in near terms and I regard (for reasons amply discussed in my papers) as impossible.
Let me qualify my assessment by saying that Scott promised in comment #52 to give further explanation and at the publishing date much more supplementary material which may change the picture.
“Of course, any such acceptance is temporary. At any time someone may develop classical algorithm to produce X (or factor integers, or prove that P=BQP) and the supremacy disappear.”
In my opinion, Bogdan, raising very unlikely scenarios of this kind is not scientifically productive.
Dear Gil,
I will look for test T in the long version as soon as official long version become available.
I think we need to agree what exactly we mean by quantum supremacy. Ideally, we would like to observe how quantum computer solves useful task for which we either have strong theoretical evidence of classical hardness or long history of trial and fails (factoring). For SUCH supremacy, I agree that this would be a major scientific event, in the caliber of the Higgs discovery. However, no one expects this in any near future.
So, let us agree that quantum supremacy is “to the use of a quantum computer to solve some well-defined problem P that would take orders of magnitude longer to solve with any currently known algorithms running on existing classical computers”. Note that this definition does not require P to be a famous problem, it may be a new just defined problem, for which we can have at most some informal intuition why we think P might be classically hard.
In this case, no classical algorithms to solve P, except of brute force, exists, for a simple reason that no-one tried to develop such an algorithm yet expect maybe the authors of the paper. So, it is not a surprize at all that it takes exponential time to solve P classically. In my opinion, this cannot be counted as a “major scientific event, in the caliber of the Higgs discovery” just because classical algorithm for P may be easy to find, they may appear in a month or two, and this is not an unlikely scenario at all. Only if many people would try and fail to solve P classically for at least several years, we can (carefully!) start to celebrate a “major scientific event”.
Back to the current Google claim. When they publish the final version of the papers, and we find and understand their test T there, we will have a candidate problem P “to generate the set X which pass the test T”. Then, in my opinion, the main question will be: can we efficiently solve P classically or not? If not, then P would satisfy the definition above, and, BY DEFINITION, we would have a demonstration of the quantum supremacy (even if some other claims in the papers are wrong).
Bogdan, I agree with you. You say that the supremacy claim is fairly tentative so its shaky nature is a good reason not to regard it automatically as a major advance but judge it according to the context and clarity. (This is a good general advice.) I also agree with what you regard as the main question. On the technical matters, there appears to be recipe to describe the noisy distribution based on 1-qubit and 2-qubit fidelity and I will be happy to have an explanation or a pointer to this recipe.
Dear Gil,
I have been very puzzled by this announcement. Their claim seems to me to be impossible. You worked on debunking the Bible codes. Do you think there is a possibility that they made similar mistakes with their experimental protocol in their calibration of their computer?
Craig Feinstein
Sent from my Sprint Samsung Galaxy S® 6 edge.
Craig, generally speaking methodological mistake in calibration processes can lead to troubles. I dont see how this might be relevant here, and there are a couple of other things that I consider more relevant.
Reading your other comments in this thread, it appears that you believe that the answer to “Q8. Is there a mathematical proof that no fast classical algorithm could possibly spoof the results of a sampling-based quantum supremacy experiment?” on Scott Aaronson’s blog is “yes”, even though Scott says “not at the present” and he seems to imply that the likely answer is “never” even though he cannot prove it. So you believe that the “conditional hardness results” that Scott talks about in his answer are not strong enough to rule out a classical algorithm that could spoof the results of the experiment?
I made a mistake in how I phrased my previous question. I meant to ask “you believe that there is a fast classical algorithm that could spoof the results of a sampling based quantum supremacy experiment?”
Craig, indeed I don’t see any convincing reason to think that the specific statistical tests in the paper for the 53-bit samples (or other samples) detect “quantum supremacy”. This is not very related to the asymptotic questions in Scott’s Q8.
Craig, actually after reading more carefully the description of the calibration process in the supplementary material, it is indeed possible that some of the success in the statistical tests may reflect methodological problems of the calibration process.
Not surprising, as both are fantastic claims. Actually, I spoke with one of the Bible codes experimenters a long time ago, who said he did not do anything to tune the spelling of the names of the rabbis, as your paper in 1999 claimed they probably did. I believe him. In fact I believe that all of the major Bible codes experiments were done honestly (just as I believe the Google experiment was done honestly). However, the fact that they *could* have done them dishonestly is what convinced me that their experiments simply had a flaw in their design.
Villalonga (2019) discusses four different categories of classical simulators: direct evolution of the quantum state, perturbation of stabilizer circuits, tensor network contractions and hybrid algorithms. Obviously matching the fidelity of a NISQ device can substantially reduce the computational burden. The Kullback-Leibler divergence can distinguish the Porter-Thomas distribution but analog computers can produce it as well (see Tangpanitanon 2019). Makes me wonder if anything “digital” is really going on here. Either way, they are a long way from the BILLION physical qubits of high quality needed to crack RSA. https://arxiv.org/pdf/1905.00444.pdf
This recent paper has at least reduced the billion qubits to around 20 million to crack 2048-bit RSA: https://arxiv.org/pdf/1905.09749.pdf
I wrote to John Martinis, Hartmut Neven, and Sergio Boixo, passing along your request for the full histogram of probabilities for random circuit sampling with a smaller value of n.
John Martinis wrote back, pointing out that they already did this for 9 qubits in their 2018 Science paper. John asks whether this is satisfactory or whether you’d like more data.
Thanks for the initiative Scott. We will continue this by email.
(I actually referred to the very same paper when I wrote above “One concern I have with this [2017] experiment is that I did not see quantitative data indicating how close D’ is to D.” So I did not find a satisfactory data there even then, but I will have a second look.)
Prof. Kalai,
I’ll rephrase my below question, about moment matching, in terms of Google’s 2017 paper. Eqn (2) and Fig 3(b) of that paper describes and shows a KL comparison to theory. What does that comparison lack, in your view?
I agree that if one measures different experimental distributions for different experimental runs in their latest results, then that will be concerning. I expect there will be more clarity on that when it is published.
Thanks.
To Klee’s comments, as I wrote in a comment below, I suppose that a quantitative study of a distance notion (like cross-entropy distance) between the sampling given by the quantum computer and the distribution described by the proposed theoretical model (for the range of 5-25 qubits or so) would be useful and it seems necessary. (It would also be nice to have the distance between two independent samples, to account for point 4 in that comment). The distance between the QC sample and the uniform distribution is less relevant.
Update: Scott proposed (Sept 25) that rather than continuing to serve as a go-between, Ryan and I will correspond directly with John Martinis and his team. John (Sept 25) welcomed our interest but asserted that because of the press embargo they would not like to discuss this much more until the paper is published. I wrote to Google team two emails (Oct 7 and 9): Here is a link to these emails. (Sergio Boxio made a quick short response on one technical issue; My Oct 7 email contained in line comments to an earlier email by John and those are not included.)
Pingback: OK, WTF Is Google’s ‘Quantum Supremacy’?
Pingback: OK, WTF Is Google’s ‘Quantum Supremacy’? | e-Radio.USa
Pingback: Shtetl-Optimized » Blog Archive » Scott’s Supreme Quantum Supremacy FAQ!
Pingback: OK, WTF Is Google’s ‘Quantum Supremacy’? – Shirley Coyle
Bogdan, Ryan, and others,
The way I see mathematically the situation is the following:
A) The ideal distribution has a certain Fourier-type expansion. The effect of the noise is to reduced higher terms exponentially. The resulting distribution for the current level of noise still have some low correlation with the ideal distribution due to low terms Fourier terms but it is very very classical. (Indeed it is not uniform) This is what the statistical test detect. It has nothing to do with quantum supremacy.
B) The reason that the outcomes shrink the larger coefficients more than what the Google people expect is due to the fact that they do not take into account the large positive correlation for gated 2-qubit errors and other factors. (In any case, not testing for the precise distributions their system gives for small value of n is, in my opinion, a serious scientific flaw.)
C) Specifically to Bogdan’s point. It goes against my computational complexity intuitions (as well as my intuitions about statistics) that a statistical test of the kind described here will detect distributions that manifest quantum supremacy. (I suspect that usually, statistical tests examine low term Fourier coefficients.) It seems that the (very low) significance levels are w.r.t. a null hypothesis of uniform distribution and certainly not w.r.t. a null hypothesis of a classical distribution.
Dear Gil,
Just to clarify. When you say that “The resulting distribution … is very very classical” you mean that it is easy to write down a classical computer program which generates it? Specifically, the program returning a distribution that have “some low correlation with the ideal distribution” and therefore pass their statistical test. Such a program would finish the discussion (except that I still do not see EXACT code or algorithm how exactly they perform their test).
Bogdan, yes you are right. I suppose that the full supplementary material will have the details of the statistical algorithm.
Klee, Randomly chosen example is perfectly fine. I am not sure what you mean by “match theory”. The noisy version have only very small traces of the ideal distribution, so the moment will be very very different.
Prof. Kalai,
To move the argument forward, could you propose a circuit C and integer m such that if experimentalists statistically confirm that the leading m moments from their quantum implementation of C matches theory and shows a speedup, then they have achieved supremacy, at least for C? Such a worst case example can’t be randomly chosen because it may not have sufficient CNOTs that (I believe) you think will ultimately consign such results to LDP.
Absent such a (C,m), it appears like every experimental quantum speedup can always be attributed to a constant pre-factor in LDP. Also, if m is infinite no matter how C is chosen, then there doesn’t seem to be any avenue for quantum experimental proof (although classical devices and algorithms of the future can be shown as disproofs).
Thanks.
I don’t think the debate is resolved until we see an error-corrected, programmable machine outperform a classical computer on a perfectly verifiable computation. I’m not convinced this isn’t just a fairly silly quantum experiment on an AQS in disguise, proving what we already know about QM. Quantum chaos is not a new phenomenon. https://arxiv.org/pdf/1906.03860.pdf
Pingback: B1. Kutipan2 | Entropy Rider
An additional prediction from my papers is that noisy implementations of pseudorandom circuits (or surface codes) will be, for certain ranges of noise, chaotic. Namely rather than sampling from one fixed distributions, two runs of the experiment amounts to two distinct distributions (The low term Fourier coefficients are robust but the higher terms have very large fluctuations.) This means that an important thing you need to verify for such an experiment is that the experimental results are robust.
Sure, but I find “quantum supremacy” is trying to pull itself up by its own bootstraps by assuming localized Pauli errors. Verifying the digital error model requires a proper benchmark. Demonstrating a predictive uncorrelated error model up to a Hilbert space of 2^53 sounds impressive but compared to what? Compare to achieving the PT distribution with a driven analog quantum processor? This all seems like circular logic.
Matt, I think that it is possible to plan a good “quantum supremacy” experiment with circuits of size 50 (or even smaller) Some necessary requirements for such a test are:
1) The model should be checked experimentally for 5-10-15-20-25 qubits (Actually, in my 2018 paper I noted that that this already gives strong positive or negative support for quantum supremacy claims. It is certainly necessary.)
2) The model proposed for the noisy distribution should be correct regarding 1-qubit errors and 2-qubit errors including 2-qubit correlations for gated qubits and including error-fluctuations.
3) There should be a critical study of a proposed statistical test for quantum supremacy.
4) There should be a clear evidence that the sampling is robust: Each sample is from (approximately) the same probability distribution.
I would regard an experiment as a priori incomplete if it does not meet these requirements.(Or else give good reasons for not meeting them.)
Pingback: Noisy quantum circuits: how do we know that we have robust experimental outcomes at all? (And do we care?) | Combinatorics and more
It looks to me that the main statistical tool used in the Google’s paper namely the cross-entropy benchmark F=F_WEB might have serious problems and that it might be easy to fool it with a classical distribution. Let P be the (noiseless) probability distribution described by our fixed-in-advance random circuit. For a sample we compute
we compute  . The expectation of F is 1, while for the uniform distribution the value is 0 and the test for supremacy is F > 0.001 (or something like that). It is perfectly reasonable that asymptotically with n finding a sample with F>0.001 is hard.
. The expectation of F is 1, while for the uniform distribution the value is 0 and the test for supremacy is F > 0.001 (or something like that). It is perfectly reasonable that asymptotically with n finding a sample with F>0.001 is hard.
But now the point is this: Suppose we have an oracle access to the (noiseless) probability distribution P described by our random circuit. Then by a polynomial number of oracle calls we can easily a samples for which F is log n. So far this is very hard (perhaps in the neighborhood of #P).
But now suppose that we apply a Beckner-type noise t on the distribution P and get a noisy distribution Q(t). The expectation of F will likely shrink by a fraction t. But by choosing the best sample among polynomially many (or best n samples among n^3) we get a value for F which is probably logn / t. However the noisy version of P can be sampled by a number of steps which is proportional to the number of “large” Fourier coefficients of Q(t). In the ranges we talk about (n=30-53) it looks that it will be easy to fool the test without any supreme powers.
Three points. First, if we choose the sum of log p_i we get only log log n so it will make matters harder. (This is related to Ryan’s comment.)
Second, This observation suggests that calibration of the circuit based on F might be a flawed methodology, as it does not optimize the actual fidelity of the noisy circuits but rather it optimizes toward our specific statistical test.
Third efficient sampling according to “heavy” Fourier coefficients is not obvious but an important (while easy) algorithm of (ironically) Goldreich and Levin.
Added later: the statement “we get a value for F which is probably logn / t” seems incorrect. So the effect so noise will decrease F more than that”.
To relate it to the SO discussion. Scott commented (#46): “It’s just that preferentially sampling the ‘heavier-weight’ strings is expected to be a classically intractable problem.”
My point is that sampling the t-Beckner-noisy distribution will give us good preferential sampling of the noiseless distribution and the computational cost (running time) behaves like 2^H(t)n. So, while asymptotically intractable, in the range of interest it is very tractable.
Very interesting comment Gil. That answers my other questions on this blog. I hope you are right.
Thanks. This post and my comments are preliminary ideas on the papers of the Google’s team. The Google supremacy experiment is an interesting event, and it gives an opportunity to examine various issues related to the debate 🙂
Gil, I am glad you are explaining the skeptic’s side to the QC debate. My guess is that when (if) Google formally announces quantum supremacy, you will get a lot more visitors here in this blog.
You write “the cross-entropy benchmark F=F_WEB might have serious problems and that it might be easy to fool it with a classical distribution”
However, the recent preprint of Scott Aaronson and Sam Gunn
https://arxiv.org/abs/1910.12085
proves the conditional hardness result for fooling this test!
After this paper, I now starting to believe in the supremacy claim!
Indeed, Google may make mistakes and their device may output different distribution from what they think. However, the output, whatever it is, passes the cross-entropy benchmark test. On the other hand, Scotts papers gives theoretical evidence that passing this test classically is hard. Then why not this is a supremacy?
Hi Bogdan, I also think now that the cross entropy test is quite good and I agree with your last sentence. It looks, for examples, that (modulo some small issues) a cross entropy test on 53 qubits of 1+1/10,000 is sufficient to disprove my conjectures. (Even if, as the IBM paper asserts, it can be achieved in a few days by a very strong computer.) The crucial aspect, in my view, is to understand (and also further develop, and replicate) the experiments in the regime that can be tested by a classical computer. (This regime is larger now by the IBM method.)
Pingback: New top story on Hacker News: Extraordinary but probably false quantum supremacy claims (Google) – Golden News
Pingback: New top story on Hacker News: Extraordinary but probably false quantum supremacy claims (Google) – Hckr News
Pingback: New top story on Hacker News: Extraordinary but probably false quantum supremacy claims (Google) – News about world
Pingback: New top story on Hacker News: Extraordinary but probably false quantum supremacy claims (Google) – Latest news
Pingback: New top story on Hacker News: Extraordinary but probably false quantum supremacy claims (Google) – protipsss
Pingback: New top story on Hacker News: Extraordinary but probably false quantum supremacy claims (Google) – Outside The Know
Pingback: New top story on Hacker News: Extraordinary but probably false quantum supremacy claims (Google) – World Best News
Pingback: Extraordinary but probably false quantum supremacy claims (Google) – INDIA NEWS
Pingback: Quantum computers: amazing progress, but probably false supremacy claims – Hacker News Robot
Pingback: Quantum computers: amazing progress (Google & IBM), and extraordinary but probably false supremacy claims (Google). – Gadgets and Technology News
Upon more careful reading of the papers, it seems that there are major issues with two elements of the experiments: the calibration and the extrapolation.
The main mistake is that the researchers calibrate parameters of the QC to improve the outcomes of the statistical tests. This calibration is flawed for two reasons. First it invalidates the statistical test since the rejection of the null hypothesis reflects the calibration process. Second, the calibration requires computational power which is larger than the task they have for the QC. (So its invalidate any claim for quantum advantage.)
The second related mistake is that the researchers extrapolate from behaviors for experiments that they can calibrate (30 or so qubits for the full circuit or 53 qubits for a simplified circuit) to the regime where they cannot calibrate (53 qubits for the full circuit). So even if the calibration itself was kosher, the extrapolation is false and there is no reason to think that the statistical test on the 53-qubits sampled for the full circuit will do as well as they expect it.
Pingback: The story of Poincaré and his friend the baker | Combinatorics and more
Pingback: World News OK, WTF Is Google’s ‘Quantum Supremacy’? – Blue Bamboo Media
Two informative questions, perhaps some reader can help with the information.
One of the points I asked John Martinis and his group was the following: “Right now, it is not clear what is the largest n (somewhere around 30? 43?) on which the full circuit experiment was compared to the ideal distribution via the cross entropy test, and how many samples where taken. In a sense, this is the most crucial cross entropy test in the whole experiment. So I suggest to include this information in the paper.”
As it turned out a very similar point was also the main request of Scott Aaronson (as referee to the paper) from the authors as he explained: “I don’t mind revealing at this point that the lack of direct verification of the outputs, for the largest reported speedups, was my single biggest complaint when I reviewed Google’s Nature submission. It was because of my review that they added a paragraph explicitly pointing out that they did do direct verification, using something like a million cores running for something like a month, for a smaller quantum speedup (merely a million times faster than a Schrödinger-Feynman simulation running on a million cores, rather than two billion times faster).”
What I am curious about is where is this paragraph? What is the number of qubits? (38 perhaps?) how many samples were taken by the QC? what is the XEB value? (And, is there a link to the actual QC sample and the probabilities that were computed classically?)
GK: Scott told me that this refers to a simplified-circuit 53 qubit experiment.
A related question is that Scott also wrote: “But when the final paper is released with all the supplementary materials (and links to more stuff online), hopefully it will provide much of the additional data that you want.” So far I only see in the Nature site the short and long papers (which are similar to the leaked ones). Are there more supplementary material and links to come?
As it turned out the paper refers to an external site with all the experimental results. Here is the link https://datadryad.org/stash/dataset/doi:10.5061/dryad.k6t1rj8
I’m still trying to get a reply from Scott on this comment:
https://www.scottaaronson.com/blog/?p=4372#comment-1822402
GK: Craig, this was an initial heuristic thought of mine that noisy quantum circuits on 53 qubits with fidelity 10^-4 may be classically approximated by 2^{53}/10^4 algorithm. No need for a reply from Scott at this stage 🙂
Pingback: Starting today: Kazhdan Sunday seminar: “Computation, quantumness, symplectic geometry, and information” | Combinatorics and more
Pingback: Amazing! Keith Frankston, Jeff Kahn, Bhargav Narayanan, Jinyoung Park: Thresholds versus fractional expectation-thresholds | Combinatorics and more
Pingback: Did We Really Achieve Quantum Supremacy? - aster.cloud
Pingback: Gil’s Collegial Quantum Supremacy Skepticism FAQ | Combinatorics and more
Pingback: Google, IBM, and the Quantum Supremacy Affair Explained
Pingback: יומיות 04.10.2019: גוגל השיגה עליונות קוונטית, מה הלאה? | ניימן 3.0
Pingback: Google’s Quantum Supremacy: What Does It Mean For Cybersecurity? – Zox News Team
Pingback: Ordinary computers can beat Google’s quantum computer after all | Combinatorics and more
Pingback: Greatest Hits 2015-2022, Part I | Combinatorics and more
Pingback: Greatest Hits 2015-2022, Part II | Combinatorics and more