
Below are 10 annotated slides from a spontaneous informal talk that I gave at the school on mathematics of quantum computing a weak ago. (Power point presentation.) Later in the afternoon we had a panel/debate on quantum supremacy (click for the video click for the new video) moderated by Sandy Irani and featuring Scott Aaronson, Dorit Aharonov, Boaz Barak, Sergio Boixo, Adam Bouland, Umesh Vazirani, and me. It was a thoughtful and interesting discussion. (The presentation was initially prepared for the afternoon debate but at the end I gave it as a separate talk and presented just one slide at the panel itself. The plan was also to post it as a background material before the discussion, but not untypically, I was too slow, so here it is a week later.) I am thankful to Dorit for inviting me to the panel (and for organizing a great school!), to Sandy for her excellent moderation, and to all the panelists for their good spirit. (Update: A blog post by Dorit at Windows on Theory)
My assessment continues to be that both the Google supremacy claims and their other central claim about fidelity estimation are incorrect.
(Dec 23, 2019: Following some renewed discussion in the last days on the terminology I proposed to replace the term “quantum supremacy” with “HQCA – Huge Quantum Computational Advantage” and I myself may try to follow my new term in my own lectures/papers in the future and see how it goes. In fact, I already used HQCA in our Sunday’s Kazhdan seminar where I lectured about noise stability and sensitivity for Boolean functions, Boson Sampling, and quantum circuits (lecture notes).)
My Presentation on the Google Quantum Supremacy Demonstration
Note: you may click on a slide to see it in full screen.

My lecture is not about quantum computers and quantum supremacy in general but about the Google quantum supremacy claims. (If you want to know more about my general argument against quantum computers, quantum supremacy and quantum error correction go to the previous post Gil’s Collegial Quantum Supremacy Skepticism FAQ and to several of my papers and presentations linked there.)

In this presentation I will concentrate on aspects of the Google experiment that are “too good to be true”. (Which is a bad sign, not a good sign.)

There is an amazing agreement between the fidelity as estimated from the experimental data and a very simple high-school model based on the probability of individual qubits and gates to malfunction. (An even simplified version, below in purple, requires just three parameters – the number n of qubits, the number g1 of 1-qubit gates and the number g2 of 2-qubit gates.)
Formula (77) itself is not surprising but the terrific success of Formula (77) may serve as a smoking gun for the claim that the Google’s experiment has serious methodological problems.
I was not the only one to be amazed. Here is what John Martinis, the scientific leader of the Google supremacy experiment told about it. (Nov 1., 2019) Read carefully!

The accuracy of Formula (77) is the most amazing thing about the data, something that came as a big surprise, and that (jokingly) will let quantum scientists keep their jobs.
And here is what I think

No no, you cannot estimate with precision of 10-20% the probability of failure of a physical system with 1000 interacting elements as the product of 1000 error-probabilities.
This remarkable agreement is a major new discovery, and it is not needed for building quantum computers. It is only needed for the extrapolation argument leading the Google team to supremacy.
Even if quantum computers will be built this is something that we are not going to witness. It is interesting to check if we see anything remotely like this for the IBM quantum computers.

Here on the left you see for various values of n, the number of qubits, two experiments with different circuits that leads to entirely different probability distributions. Since each pair have a similar number of gates, Formula (77) leads to very close fidelity estimates which are so accurate that the green and blue lines coincide! We do not expect to see such close agreements in experimental data.

Blue, orange and green analytic smooth curves representing three distributions. For all three you see also empirical samples from the distributions. For two of them the samples are perfect, for the other one you see a sample based on a complicated physical experiment.
Test your intuition: can you tell the difference? Can you tell which is which?
(You can also test your intuition which was the single slide presented at the afternoon debate.)

Blind tests are standard in scientific experiments and are quite easy to implement here.
The meaning of the surprising statistical success of Formula (77) should be carefully examined.
Two extra slides
To put my view in context, I devote one slide for my general argument against quantum computers, quantum supremacy and quantum error correction.

I mentioned that most experts do not agree with my argument or do not even understand it, and for some of them, this may give reasons for skepticism also about my critique on the Google experiment. I personally think that my general argument is good, but I don’t think it is ironclad and I am pleased to see this matter explored experimentally (properly). I also think that my critique on the Google demo stands well on its own.
And what may convince me to change my mind? poetry!

Let me add that all my critique as described here and elsewhere was first presented to the Google team.

From right to left: Sandy Irani, me, Boaz Barak, Adam Bouland, Dorit Aharonov, and on the left Umesh Vazirani, Scott Aaronson, and Sergio Boixo. (Collage; More pictures – below.)
Answer to Test your intuition: The orange graph is the one that comes from the experiments.
Some recollections, reactions, and comments from the debate:
Uploading data for verification
At the beginning of the debate, I nudged Sergio to upload some (additional; promised) data that is needed for verification and analysis of their results.
Formula (77)
Formula (77) was discussed in some details in Q/A of the the informal talk and also in the panel/debate. (I raised the question if the Google experiment is correct and specifically the issue with Formula (77) at 36:50 and Formula (77) was discussed for the next 25 minutes.) Of course, the surprising issue is the accurate predictions that Formula (77) gives.
Sergio briefly explained the statistical rationale for such a precision. The way I see it, the quality of the prediction for (77) requires two assumptions: (1) No systematic errors, (2) statistical independence. Both these assumptions seem utterly unrealistic. No systematic errors means that the average error estimation say for read-out errors or for gate errors are precise and fluctuations are symmetric. This is very unrealistic. The assumption of statistical independence also seems unrealistic. (Positive correlations will actually lead to better fidelity.) Dorit, Boaz and several other people (and also Peter Shor earlier here on the blog) proposed that the remarkable predictive power of (77) and, in particular, the required statistical independence may follow from having a random circuit. I don’t understand that.
Beside the concrete attempts to understand the predictive power of Formula (77) there were some general comments about it. Adam opined that in physics the data fits the models very well. Scott joked that here I am arguing that the results fits the model too well and he could imagine me arguing in another universe that the results don’t fit the model well enough. At another point he said “First the data is not good enough, and now the data is too good, what will make you happy, Gil” and I answered that the data should be reliable.
The extended Church-Turing thesis (ECTT)
Does “supremacy” (or HQCA), in general and in the context of Google’s experiment violates the extended Church-Turing thesis? Dorit claimed that the answer is negative since (roughly) the experiments cannot be scaled. Sergio sort of agreed and said they only claim to challenge the ECCT. (Indeed the fidelity goes exponentially to zero and even if producing such samples is beyond the power of a classical computer the sample sizes need to be exponential; it is an interesting question if every scalable supremacy demonstration requires quantum fault tolerance.) A point that I made is that if we assume further certain “naturalness” principle, namely that, in practice, constants in computational complexity asymptotic behavior are mild, then an astronomical speed-up as claimed by Google, can be considered as violating ECCT.
Trillions
Actually, in the early lecture I presented another slide about my initial feeling towards the Google (then licked) paper. I was surprised by the trillions-time speed up, and regarded the 300,000,000,000 speed-up as expressing some “supremacy fever:” why not start with a more modest speed-up but with convincing direct evidence?

Why the trillions speed up should not surprise us? Adam Bouland commented that this is to be expected when we think about exponential speed-up. BTW, Adam gave very nice lectures on quantum algorithms and quantum supremacy.
Miscellaneous
- I was slowly loosing my voice so in the earlier lecture Or Sattath read the quote from Martinis, and Adam read the poem by Renan. (I should try that also in talks where I am not loosing my voice.)
- Sandy asked about other reasons for skepticism regarding the Google claims and Scott mentioned the possibility that much better classical algorithms will be found.
- Both me and Scott (and perhaps others in the panel as well) emphasized the importance of replications.
- Adam was Scott’s Ph. D student and Scott was Umesh’s Ph. D. student so we had on the panel three academic generations!
- Toward the end Scott described briefly the decade-old history, theory+experiment, of quantum supremacy.
- There were various other interesting issues that were raised.
- For history: The video flipped left and right. In reality Sandy was right farthermost and I was second to the right; (March 9) A new correct version was uploaded.
Quantum error-correction
Dorit asked about quantum error correction and I asked specifically about distance-3 surface code and Sergio said that the quality of gates is insufficient for that. If I understood correctly the error rate needs to be reduced by a factor of five. (The fact that good quality quantum error correction requires achieving lower error rate than what is required for quantum supremacy is an important ingredient of my general argument against quantum computers.)
Noise models and the noisy data.
Dorit and others raised the issue of the noise model and discussed some toy noise models. There was some discussion on correlated errors. (This is unrelated to the statistical dependence of (77).) I pointed out that correlated errors are irrelevant to random circuits (but relevant to quantum error-correction). Later in the debate I mentioned the concern regarding not having large enough samples to determine the empirical noisy distribution.
At some point Umesh referred to another issue that I raised which is that the noisy model in the Google paper seems oversimplified. I came back to it briefly but we did not discuss this further. (At the Q/A part of my early lecture Boaz have made some interesting comments about identifying the effect of the errors in the last round of the computation.)
I also repeated my suggestion of “Beckner noise” (and correlated variants) as a good toy noise model for noisy quantum circuits.
My argument against quantum computers
At the panel I mentioned my general argument against quantum computers, quantum supremacy and quantum error correction only in a few sentences.
BTW, one way to think about the argument is as comparing four thresholds for the level of noise (on gates) 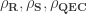





Comparisons to Wright brothers’s first flight or to Fermi’s 1942 nuclear chain reaction
Nobody in the afternoon panel discussion (to the best of my memory) repeated earlier enthusiastic comparisons between Google’s experiment and the first flight in 1903, the first landing on the moon in 1968 (well, I referred to that), Fermi’s 1942 nuclear chain reaction, the first vacuum tubes computers, the discovery of the Higgs boson, etc. etc.
Silver lining (after-thought)

The beach of Tel Aviv
Major advances in human ability to simulate quantum physics and quantum chemistry are expected both if quantum supremacy can be demonstrated and quantum computers can be built and also if quantum supremacy cannot be demonstrated and quantum computers cannot be built.
Debate picture collage


The audience was happy

{kind=link}
Watched the panel/discussion and was surprised that google does not plan to demonstrate error detection first, before shooting for error correction. Demonstrating error detection, and repeating a given computation until no error gets detected (with as many qubits as the hardware allows) seems like an important and interesting experiment to me. Especially the remaining error distribution for the runs where no error was detected will be very interesting.
Pingback: Predicting Predictions For the 20s | Gödel's Lost Letter and P=NP
Pingback: Gil’s Collegial Quantum Supremacy Skepticism FAQ | Combinatorics and more
Pingback: Quantum Matters | Combinatorics and more
Pingback: Greatest Hits 2015-2022, Part II | Combinatorics and more